






Fabric1.x各类bug错误解决:无法启动docker;Device or resource busy;peer无法连接orderer;Failed to Setup IP tables;创建channel时出错;Error endorsing chaincode:rpc error;Failed connecting to orderer;Error endorsing chaincode;panic: Unable to bootstrap orderer;Failed to initialize local MSP

更多区块链技术与应用分类:
1. 无法启动docker
错误描述
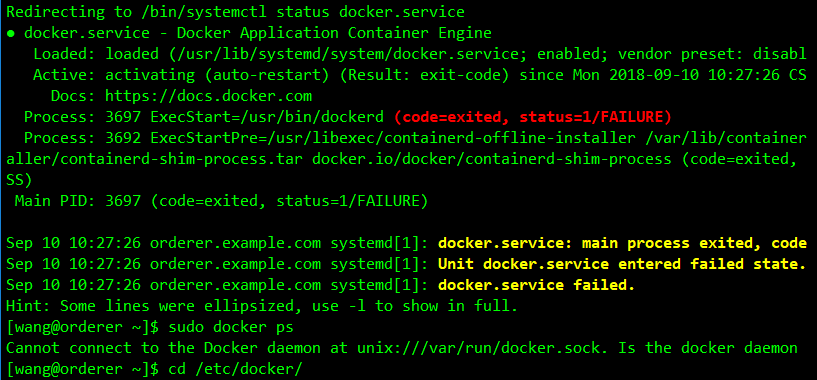
解决方法
(1)使用sudo journalctl -u docker.service 查看详细日志
(或 systemctl status docker.service或 journalctl -xe)
看到文件夹已存在

按上面提示,删除文件夹并重启docker
rm -rf /var/lib/containerd/io.containerd.runtime.v2.task/docker/dockerd
rm -rf /run/containerd/io.containerd.runtime.v2.task/docker/dockerd
service docker restart
(2) 上述如果还是不行的话,更新yum
yum update
因为看到自己用的docker版本是测试版,需更新到最新。
2. Device or resource busy错误
若上面更新yum后出现如下Device or resource busy错误,

解决方法:
cat /proc/mounts | grep "docker"
umount /run/containerd/io.containerd.runtime.v2.task/docker/dockerd/rootfs
3. docker容器启动失败
错误描述
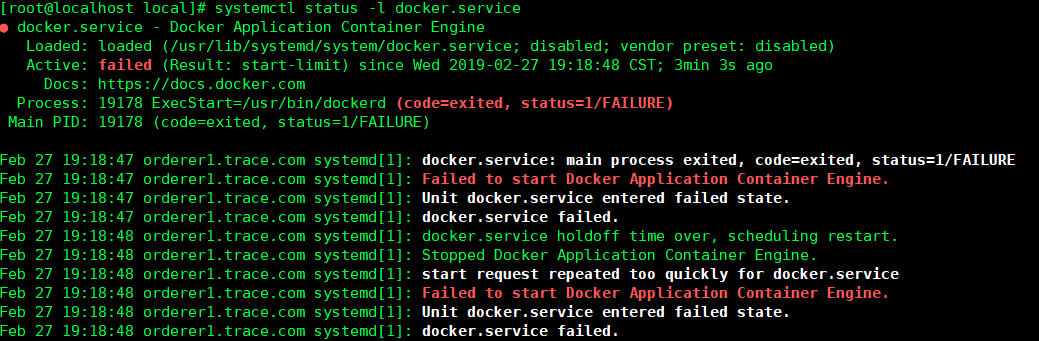
运行dockerd查看

问题原因
/var/lib/docker 目录有旧的container 文件,版本升级后需要删除。
解决方法
sudo mv /var/lib/docker /var/lib/docker.old
service docker start
rm -rf /var/lib/docker.old
4.多机部署时:创建channel时:peer无法连接orderer(orderer节点的docker宕掉了)
错误描述

解决方法
防火墙关闭以及SELINUX关闭(能ping通,但防火墙仍在运行)
(1) CentOS 7.0默认使用的是firewall作为防火墙
查看防火墙状态
firewall-cmd --state
停止firewall
systemctl stop firewall
禁止firewall开机启动
systemctl disable firewalld.service
(2) 关闭selinux
进入到/etc/selinux/config文件
vi /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
(3) 重启
orderer节点:
sudo docker-compose -f docker-orderer.yaml down
sudo docker-compose -f docker-orderer.yaml up -d
peer节点:
sudo docker-compose -f docker-peer01.yaml down
sudo docker-compose -f docker-peer01.yaml up -d
5.由于使用了1.0.0版本的tools。
解决方法
使用1.1.0版本
6. orderer节点IP错误导致启动失败
vim orderer.yaml
将ListenAddress: 127.0.0.1改为ListenAddress: 172.27.43.200。
然后重启
7. Failed to Setup IP tables错误

解决方法
服务端口被占用,重启docker
service docker restart
8.创建channel时出错

解决方法
历史数据未清除干净,orderer与peer都重启
sudo docker-compose -f docker-orderer.yaml down
sudo docker-compose -f docker-peer01.yaml down
sudo docker-compose -f docker-orderer.yaml up -d
sudo docker-compose -f docker-peer01.yaml up -d
9.Error endorsing chaincode:rpc error...

解决方法
将/opt/hyperledger/peer/core.yaml中
mode参数从dev改为net然后重新启动
10. Failed connecting to orderer

暂未解决。
11.当执行peer命令时Error endorsing chaincode
错误描述
Error: Error endorsing chaincode: rpc error: code = Unknown desc = access denied: channel [tracechannel] creator org [SampleOrg]
错误原因
启动前没有导入环境变量,重新执行:
export set CORE_PEER_LOCALMSPID=Org1MSP
export set CORE_PEER_ADDRESS=peer0.org1.trace.com:7051
export set CORE_PEER_MSPCONFIGPATH=/home/wang/sourceOrSoftware/traceabilityProjectConfig/crypto-config/peerOrganizations/org1.trace.com/users/Admin@org1.trace.com/msp/
12.启动peer时ERRO 00f Error creating GRPC server
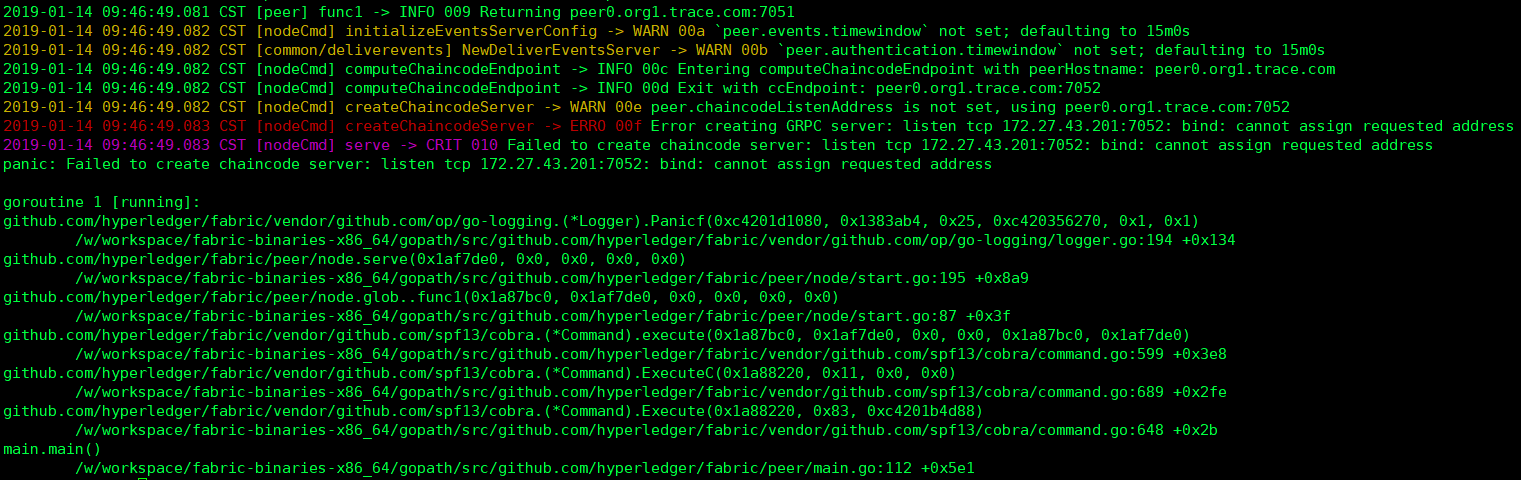
错误描述
2019-01-14 09:46:49.083 CST [nodeCmd] createChaincodeServer -> ERRO 00f Error creating GRPC server: listen tcp 172.27.43.201:7052: bind: cannot assign requested address
2019-01-14 09:46:49.083 CST [nodeCmd] serve -> CRIT 010 Failed to create chaincode server: listen tcp 172.27.43.201:7052: bind: cannot assign requested address
panic: Failed to create chaincode server: listen tcp 172.27.43.201:7052: bind: cannot assign requested address
解决方法
启动之前设置变量:
export set CORE_PEER_ADDRESS=0.0.0.0:7051
13. 启动peer后出错ERRO 035 Bad configuration detected: Received AliveMessage from a peer with the same PKI-ID as myself
错误描述
handleAliveMessage -> ERRO 035 Bad configuration detected: Received AliveMessage from a peer with the same PKI-ID as myself: tag:EMPTY alive_msg:<membership:<endpoint:"peer0.org1.trace.com:7051" pki_id:"\206\312\344\340\031\264\227 \315CQ\361`\346\335\354L\306\220fuu1\340\003\265\022\247).\235\357" > timestamp:<inc_num:1547433808625844097 seq_num:121 > >
14. 重装docker
0. 卸载
- 查询安装过的包
yum list installed | grep docker
docker-engine.x86_64 17.03.0.ce-1.el7.centos @dockerrepo
2. 删除安装的软件包
yum -y remove docker-engine.x86_64
3. 删除镜像/容器等
rm -rf /var/lib/docker
4.安装
yum install docker-ce
15.docker-compose运行orderer产生错误panic: Unable to bootstrap orderer
错误描述
panic: Unable to bootstrap orderer. Error reading genesis block file: open /traceabilityProject/orderer.genesis.block: no such file or directory
解决方法
保证volumes -后面的地址是一个创始区块文件而不是文件夹:

16. Failed to initialize local MSP错误
错误描述
Failed to initialize local MSP: could not load a valid signer certificate from directory /traceabilityProject/crypto-config/ordererOrganizations/trace.com/orderers/orderer1.trace.com/msp/signcerts: stat /traceabilityProject/crypto-config/ordererOrganizations/trace.com/orderers/orderer1.trace.com/msp/signcerts: no such file or directory
解决方法
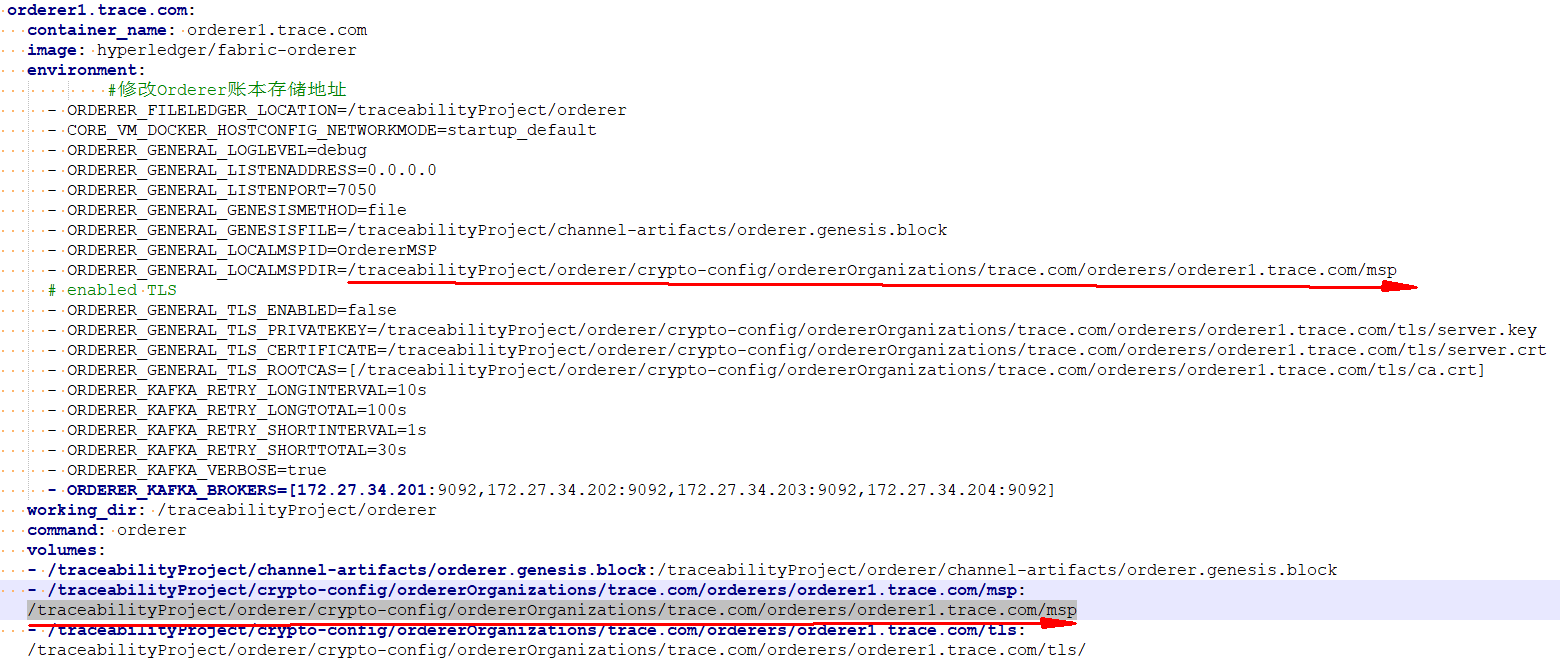
上面的ORDERER_GENERAL_LOCALMSPDIR目录,是容器内目录,不是本机目录,一定先在volumes中挂载,之后才能使用的地址。
17.生成channel时产生错误
错误描述

Error: got unexpected status: BAD_REQUEST -- error authorizing update: error validating DeltaSet: policy for [Group] /Channel/Application not satisfied: Failed to reach implicit threshold of 1 sub-policies, required 1 remaining
解决方法
(1)configtxgen生成创始块的时候,配置文件configtx.yaml指定了错误的msp目录。 导致生成的区块中包含的证书其它用户的证书。
重新生成channel-artifacts及crypto-config两个目录及内容。
(2)发现orderer.yaml下的ordermsp与configtx.yaml中定义的不一致(大小写改为一致OrdererMSP,则解决)
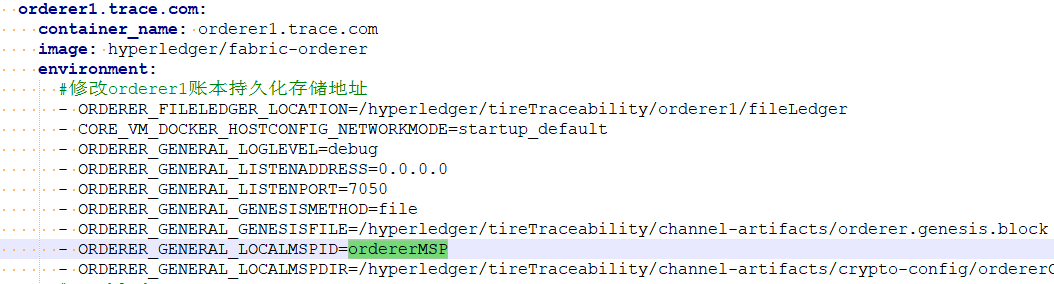
总之,该问题应是MSP识别出问题。
18. 加入通道时错误
错误描述
查看docker logs peer看到:
WARN 1be channel []: MSP error: the supplied identity is not valid: x509: certificate signed by unknown authority
错误原因
由于启动过网络并且更新了证书,在没有删除干净的环境中启动复用的之前的volume,所以导致证书认证失败。
docker-compose -f node1-docker-compose-up.yaml down --volumes --remove-orphans sudo docker rm -f $(docker ps -a |grep "hyperledger/*" |awk "{print $1}") sudo docker volume prune
解决方法
在peer容器中加入Admin的配置路径:
- CORE_PEER_MSPCONFIGPATH=/traceabilityProject/peer/crypto-config/peerOrganizations/org1.trace.com/users/Admin@org1.trace.com/msp
19. 当四个节点重启之后,出现错误panic: [channel: testchainid] Cannot set up channel consumer ,(Kafka、docker方式运行)。
错误描述
2019-03-20 06:58:44.634 UTC [orderer/consensus/kafka] try -> DEBU 86f [channel: testchainid] Need to retry because process failed = kafka server: The requested offset is outside the range of offsets maintained by the server for the given topic/partition.
2019-03-20 06:58:44.634 UTC [orderer/consensus/kafka] startThread -> CRIT 870 [channel: testchainid] Cannot set up channel consumer = kafka server: The requested offset is outside the range of offsets maintained by the server for the given topic/partition.
panic: [channel: testchainid] Cannot set up channel consumer = kafka server: The requested offset is outside the range of offsets maintained by the server for the given topic/partition.
错误原因
是fabric数据持久化问题,问题主要是没有将kafka的相关数据备份到本地。
解决方法
kafka数据持久化,启动文件修改:
kafka:
environment:
#Kafka数据也要持久化
- KAFKA_LOG.DIRS=/traceabilityProject/kafka/kafka-logs
#数据挂载路径
volumes:
- /traceabilityProject/kafka/kafka-logs:/traceabilityProject/kafka/kafka-logs
20. ERRO 001 Cannot run peer because cannot init crypto, missing...错误
问题描述
 p
p
eer0.org1.trace.com | 2019-04-15 09:04:32.243 UTC [main] main -> ERRO 001 Cannot run peer because cannot init crypto, missing /hyperledger/tireTraceability/channel-artifacts/crypto-config/peerOrganizations/org1.trace.com/users/Admin@org1.trace.com/msp folder
错误原因
没清楚docker挂载原理
解决方法
挂载了两个msp,且environment中的地址没有在volumes中出现(冒号后面)

21.Orderer节点问题,单机配置kafka时,Oderer无法连接到broker。
错误描述

Failed to connect to broker localhost:29092: dial tcp 127.0.0.1:29092: getsockopt: connection refused
解决方法
1.先查看zookeeper容器,发现一直报错
原因是dockerfile中zookeeper配置为host,且port不一样,这样不对。应该配置为容器形式,下面zookeeper1,zookeeper2,zookeeper3皆为容器:
- ZOO_SERVERS=server.1=zookeeper1:2888:3888 server.2=zookeeper2:2888:3888 server.3=zookeeper3:2888:3888
2.再配置kafka
由于以前是多机配置kafka所以使用extra_hosts用以连接其他host节点,
而现在是单机配置kafka,因此使用 不使用extra_hosts而使用depends_on,它后面跟的是容器服务。
depends_on:
- zookeeper1
- zookeeper2
- zookeeper3
由于使用的是容器,因此端口号可以统一,如kafka中参数:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
3.再配置Orderer
使用depends_on依赖容器:
depends_on:
- kafka1
- kafka2
- kafka3
- kafka4
然后配置参数(容器内端口设定为一致):
- ORDERER_KAFKA_BROKERS=[kafka1:9092,kafka2:9092,kafka3:9092,kafka4:9092]
注意:
在之前生成fabric初始文件时,需将configtx.yaml文件中的Orderer--> Kafka-->Brokers修改为:
- kafka1:9092
- kafka2:9092
- kafka3:9092
- kafka4:9092
(启动容器之前就可定义,难道docker中容器服务即host?)
22.peer节点问题,当同一组织下,其他peer节点想要加入通道并更新锚节点时,出现错误。
错误描述

ERRO 17ff Bad configuration detected: Received AliveMessage from a peer with the same PKI-ID as myself: tag:EMPTY alive_msg:<membership:<endpoint:"peer1.org2.trace.com:7051" pki_id:"\3349\005\202\304\244\230\013\237X/\036\003\306j<\271\306s:\270}\274X\006\225\256\204\303\303\237L" > timestamp:<inc_num:1556622781191104384 seq_num:487 > >
23.在Fabric v1.1版本中,当在同一个channel,同一链码名称及版本,即使清空整个Fabric网络重新部署,还是会自动启动以前安装过的链码,致使当前的链码无法安装,为何?
解决方法
没有删除链码的"镜像",实例化链码时,其实是生成镜像的过程(生成镜像时时间较长),如果存在指定名称和版本号的链码镜像则直接使用。而清空数据目录及Fabric容器后,并没有删除链码容器,导致使用旧版本!
sudo docker images
查看链码有关的镜像,删除链码相关的镜像
24. Org3运行链码时,invoke可以调用但不能将数据落账本,重启Org3的容器再执行就行可以了
25.Error creating GRPC server
错误描述
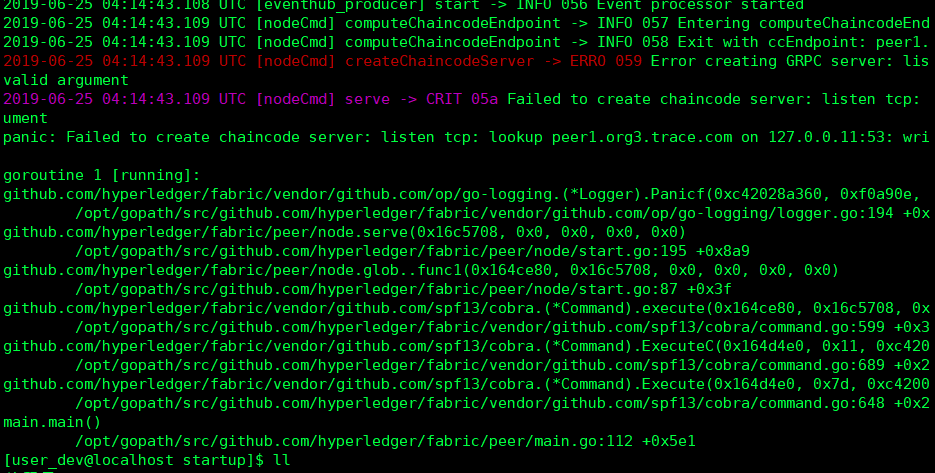
2019-06-25 04:14:43.109 UTC [nodeCmd] createChaincodeServer -> ERRO 059 Error creating GRPC server: listvalid argument
2019-06-25 04:14:43.109 UTC [nodeCmd] serve -> CRIT 05a Failed to create chaincode server: listen tcp: lument
panic: Failed to create chaincode server: listen tcp: lookup peer1.org3.trace.com on 127.0.0.11:53: write
goroutine 1 [running]:
github.com/hyperledger/fabric/vendor/github.com/op/go-logging.(*Logger).Panicf(0xc42028a360, 0xf0a90e, 0
/opt/gopath/src/github.com/hyperledger/fabric/vendor/github.com/op/go-logging/logger.go:194 +0x1
github.com/hyperledger/fabric/peer/node.serve(0x16c5708, 0x0, 0x0, 0x0, 0x0)
/opt/gopath/src/github.com/hyperledger/fabric/peer/node/start.go:195 +0x8a9
github.com/hyperledger/fabric/peer/node.glob..func1(0x164ce80, 0x16c5708, 0x0, 0x0, 0x0, 0x0)
/opt/gopath/src/github.com/hyperledger/fabric/peer/node/start.go:87 +0x3f
github.com/hyperledger/fabric/vendor/github.com/spf13/cobra.(*Command).execute(0x164ce80, 0x16c5708, 0x0
/opt/gopath/src/github.com/hyperledger/fabric/vendor/github.com/spf13/cobra/command.go:599 +0x3e
github.com/hyperledger/fabric/vendor/github.com/spf13/cobra.(*Command).ExecuteC(0x164d4e0, 0x11, 0xc4202
/opt/gopath/src/github.com/hyperledger/fabric/vendor/github.com/spf13/cobra/command.go:689 +0x2f
github.com/hyperledger/fabric/vendor/github.com/spf13/cobra.(*Command).Execute(0x164d4e0, 0x7d, 0xc42001
/opt/gopath/src/github.com/hyperledger/fabric/vendor/github.com/spf13/cobra/command.go:648 +0x2b
main.main()
/opt/gopath/src/github.com/hyperledger/fabric/peer/main.go:112 +0x5e1
解决方法
(1) 服务器重启
docker重装为17.06.2就好了
(2) docker-compose文件中加以下两个参数:
- FABRIC_LOGGING_SPEC=DEBUG
- GODEBUG=netdns=go
原文链接:Fabric1.x开发中各类Bug解决















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









