







Set是Collection子接口,模拟了数学上的集的概念。
HashSet是Set接口最常用的实现类,顾名思义,底层是用了哈希表(散列/hash)算法。其底层其实也是一个数组,存在的意义是提供查询速度,插入的速度也是比较快,但是适用于少量数据的插入操作。
在HashSet中如何判断两个对象是否相同问题:(二者缺一不可)
1、两个对象的equals比较相等,返回true,这说明是相同对象。
2、两个对象的hashCode方法返回值相等。
对象的hashCode值决定了在哈希表中的存储位置。
当往hashCode集合中添加新的对象的时候,会先判断该对象和集合对象中的hashCode值:
1)不等:直接把该新的对象存储到hashCode指定的位置。
2)相等:再继续判断新对象和集合对象中的equals作比较。
1>:hashCode相同,equals为true,则视为是同一个对象,则不会保存在哈希表中;
2>:hashCode相同,equals为false,非常麻烦,存储在之前对象同槽位的链表上。
所以存储在哈希表中的对象,都应该覆盖equals方法和hashCode方法,并且保证equals相等的时候,hashCode也应该相等。
当向hashSet集合中存入一个新的元素时,hashSet会先调用该对象的hashCode方法来得到该对象的hashCode值,然后决定该对象在HashSet中的存储位置;
如果两个元素通过equals方法比较返回true,但是他们的hashCode值不等,HashSet会把两个元素存储在不同的位置。
Eclipse可以自动生成hashCode和equals方法。
List接口:允许元素重复,记录先后添加顺序。
LinkedHashSet:底层才有哈希表和链表算法。
哈希表:保证唯一性,此时就是HashSet,在哈希表中元素没有先后顺序;
链表:来记录元素的先后添加顺序。
注意:必须保证TreeSet集合中的元素对象是相同的数据类型,否则报错。
TreeSet的排序规则:(自然排序)
TreeSet调用集合元素的compareTo方法来比较元素的大小关系,然后将集合元素按照升序排列(从小到大)
要求TreeSet集合中元素得实现java.util.Comparable接口。
java.util.Comparable接口:可比较的
覆盖public int compareTo(Object o)方法,在该方法中编写比较规则;在该方法中,比较当前对象(this)和参数对象o作比较(严格上来说比较的事对象中的数据,比如按照对象的年龄排序)
this > 0: //返回正整数
this < 0: //返回负整数
this == 0: //返回零,此时认为两个对象是同一个对象。
在TreeSet的自然排序中,认为如果两个对象比较的compareTo方法返回的是0,则认为是同一个对象。
定制排序(从大到小,按照名字长度排序):
在TreeSet构造器中传递java.lang.Comparator对象,并覆盖public int compare(Person o1, Person o2)方法,在覆写比较规则。
对于TreeSet集合来说,要么使用自然排序,要么使用定制排序:(判断两个对象是否相等的规则)
自然排序:compareTo方法返回0;
定制排序:compare方法返回0。
运行结果:
1、都不允许元素重复;
2、都不是线程安全的类。
1、equals比较为true;
2、hashCode值相同。
要求:要求存在在哈希表中的对象元素都得覆盖equals和hashCode方法。
LinkedHashSet:HashSet的子类,底层也采用的是哈希表算法,但是也使用了链表算法来维持元素的先后添加顺序,判断两个对象是否相等的规则和HashSet相同。
因为需要多使用一个链表来记录元素的顺序,所以性能相对于HashSet较低;一般少用,如果要求一个集合急要保证元素不重复,也需要记录元素的先后添加顺序,才选择使用LinkedHashSet。
运行结果:
Set集合存储特点:
1) 不允许元素重复。
2) 不会记录元素的先后添加顺序。
Set只包含从Collection继承的方法,不过Set无法记住添加的顺序,不允许包含重复的元素。当试图添加两个相同元素进Set集合,添加操作失败,add()方法返回false;
Set判断两个对象是否相等用equals,而不是使用==。也就是说两个对象equals比较返回true,Set集合是不会接受这两个对象的。HashSet是Set接口最常用的实现类,顾名思义,底层是用了哈希表(散列/hash)算法。其底层其实也是一个数组,存在的意义是提供查询速度,插入的速度也是比较快,但是适用于少量数据的插入操作。
在HashSet中如何判断两个对象是否相同问题:(二者缺一不可)
1、两个对象的equals比较相等,返回true,这说明是相同对象。
2、两个对象的hashCode方法返回值相等。
对象的hashCode值决定了在哈希表中的存储位置。
当往hashCode集合中添加新的对象的时候,会先判断该对象和集合对象中的hashCode值:
1)不等:直接把该新的对象存储到hashCode指定的位置。
2)相等:再继续判断新对象和集合对象中的equals作比较。
1>:hashCode相同,equals为true,则视为是同一个对象,则不会保存在哈希表中;
2>:hashCode相同,equals为false,非常麻烦,存储在之前对象同槽位的链表上。
所以存储在哈希表中的对象,都应该覆盖equals方法和hashCode方法,并且保证equals相等的时候,hashCode也应该相等。
当向hashSet集合中存入一个新的元素时,hashSet会先调用该对象的hashCode方法来得到该对象的hashCode值,然后决定该对象在HashSet中的存储位置;
如果两个元素通过equals方法比较返回true,但是他们的hashCode值不等,HashSet会把两个元素存储在不同的位置。
Eclipse可以自动生成hashCode和equals方法。
List接口:允许元素重复,记录先后添加顺序。
Set接口:不允许元素重复,不记录先后添加顺序。
LinkedHashSet:底层才有哈希表和链表算法。
哈希表:保证唯一性,此时就是HashSet,在哈希表中元素没有先后顺序;
链表:来记录元素的先后添加顺序。
注意:必须保证TreeSet集合中的元素对象是相同的数据类型,否则报错。
TreeSet的排序规则:(自然排序)
TreeSet调用集合元素的compareTo方法来比较元素的大小关系,然后将集合元素按照升序排列(从小到大)
要求TreeSet集合中元素得实现java.util.Comparable接口。
java.util.Comparable接口:可比较的
覆盖public int compareTo(Object o)方法,在该方法中编写比较规则;在该方法中,比较当前对象(this)和参数对象o作比较(严格上来说比较的事对象中的数据,比如按照对象的年龄排序)
this > 0: //返回正整数
this < 0: //返回负整数
this == 0: //返回零,此时认为两个对象是同一个对象。
在TreeSet的自然排序中,认为如果两个对象比较的compareTo方法返回的是0,则认为是同一个对象。
定制排序(从大到小,按照名字长度排序):
在TreeSet构造器中传递java.lang.Comparator对象,并覆盖public int compare(Person o1, Person o2)方法,在覆写比较规则。
对于TreeSet集合来说,要么使用自然排序,要么使用定制排序:(判断两个对象是否相等的规则)
自然排序:compareTo方法返回0;
定制排序:compare方法返回0。
自然排序和定制排序的基本使用:
class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Person other) {
if (this.age > other.age) {
return 1;
} else if (this.age < other.age) {
return -1;
}
return 0;
}
}
// 名字长度比较器
class NameLengthComparator implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
if (o1.name.length() > o2.name.length()) {
return 1;
} else if (o1.name.length() < o2.name.length()) {
return -1;
}
return 0;
}
}
public class TreeSetDemo {
public static void main(String[] args) {
Set<Person> set = new TreeSet<>();
set.add(new Person("倩儿", 32));
set.add(new Person("西门吹雪", 52));
set.add(new Person("叶孤城", 62));
set.add(new Person("霞", 18));
System.out.println(set);
System.out.println("----------------------------------");
Set<Person> set1 = new TreeSet<>(new NameLengthComparator());
set1.add(new Person("倩儿", 32));
set1.add(new Person("西门吹雪", 52));
set1.add(new Person("叶孤城", 62));
set1.add(new Person("霞", 18));
System.out.println(set1);
}
}运行结果:

1、都不允许元素重复;
2、都不是线程安全的类。
解决方案:Set set = Collections.sysnchronizedSet(Set对象);
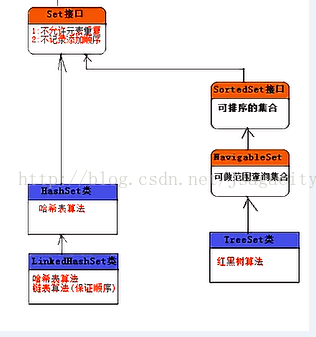
Set的家族:
1、equals比较为true;
2、hashCode值相同。
要求:要求存在在哈希表中的对象元素都得覆盖equals和hashCode方法。
LinkedHashSet:HashSet的子类,底层也采用的是哈希表算法,但是也使用了链表算法来维持元素的先后添加顺序,判断两个对象是否相等的规则和HashSet相同。
因为需要多使用一个链表来记录元素的顺序,所以性能相对于HashSet较低;一般少用,如果要求一个集合急要保证元素不重复,也需要记录元素的先后添加顺序,才选择使用LinkedHashSet。
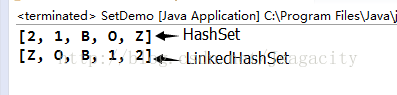
HashSet和LinkedHashSet的排序效果:
public class SetDemo {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("Z");
set.add("O");
set.add("B");
set.add("1");
set.add("2");
System.out.println(set);
Set<String> set1 = new LinkedHashSet<>();
set1.add("Z");
set1.add("O");
set1.add("B");
set1.add("1");
set1.add("2");
System.out.println(set1);
}
}运行结果:















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









