










前言
- 📚 笔记专栏:斯坦福CS231N:面向视觉识别的卷积神经网络(23)
- 🔗 课程链接:https://www.bilibili.com/video/BV1xV411R7i5
- 💻 CS231n: 深度学习计算机视觉(2017)中文笔记:https://zhuxiaoxia.blog.csdn.net/article/details/80155166
- 🔥 2023最新课程PPT:https://download.csdn.net/download/Julialove102123/88734395
⚠️ 本节重点内容:
- 视频分类
- 3D CNN
- 双流网络
- 循环卷积网络
- 多模态视频理解
一、视频分类(Video Classfication)
视频是由许多张图片合成的(当然这些图片之间有关联性)。如果说图像的形状是3 × H × W (3指的是RGB三通道),那么视频的形状则是T × 3 × H × W 或3 × T × H × W 。

存在问题:计算资源太大!!!

解决方法 :选取一部分帧,让它的帧率变小,同时降低它的分辨率,这样就降低了它的计算资源的要求。在测试的时候,使用其他帧来测试,并取平均值。

方法一:Late Fusion
对于视频帧分开训练,即每帧图像都使用一个CNN来进行训练,然后在最后进行融合(比如说使用全连接层或者全局平均池化层来将不同2维CNN训练出来的特征融合,最终得到一个结果);
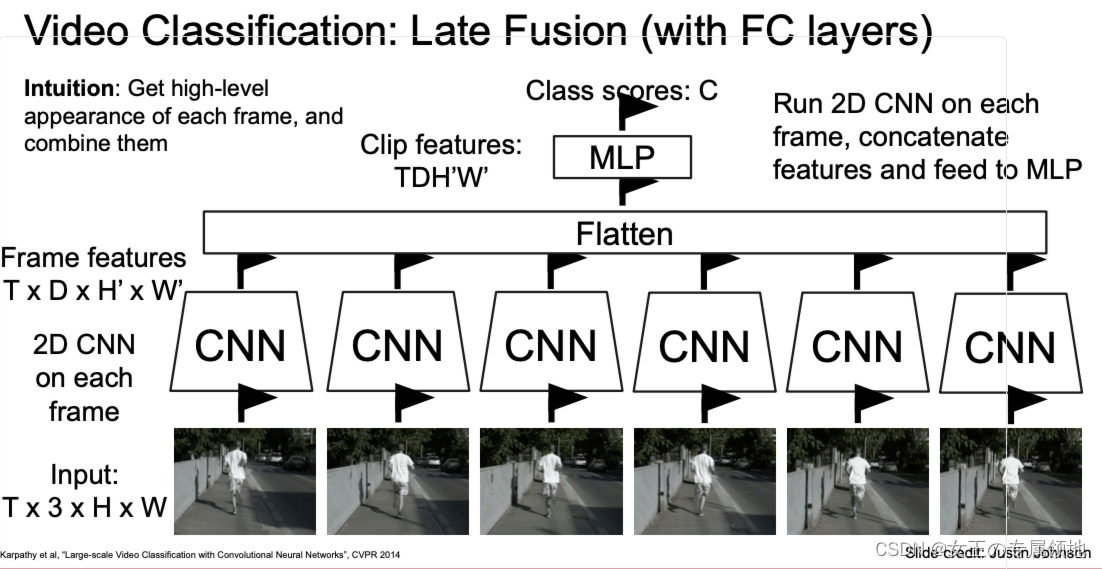

- 存在问题:很难比较不同帧之间的低级特征;
方法二:Early Fusion
先进行图片的早期融合,就是T张形状为3 × H × W 的图像融合成一张形状为3T × H × W 的图像),再将其输入到2维CNN中。可以解决方法一最后进行特征融合而导致的低级特征不足的问题;

- 存在问题:使用一个卷积层来进行时域处理(融合成一张图片)可能不够;
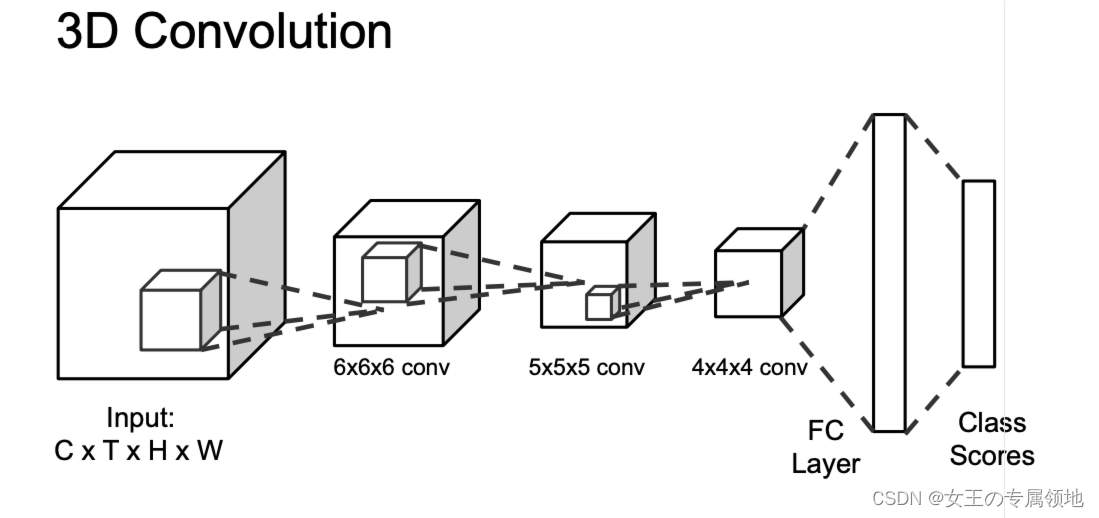
方法三:3D CNN
使用3维的卷积层和池化层来对视频进行处理,这样就既可以获取到输入的视频的时域信息,又可以避免上述的问题。

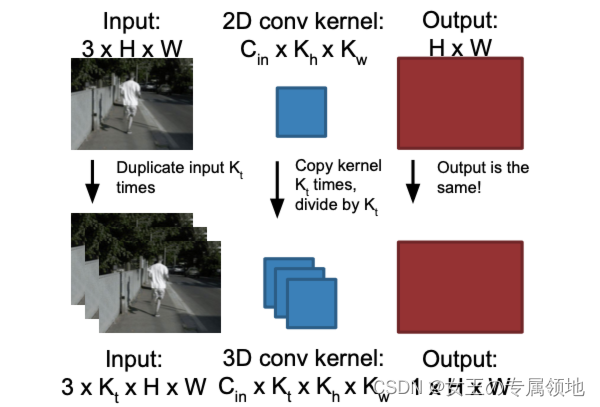
3D CNN与2D CNN是类似的。不同的是卷积层处理的是3维图像,即输入的特征由原来的3维tensor变成了4维(D × T × H × W),同时,卷积层和池化层也变成了3维的。这样的话,时间维度T上的信息就能被卷积核给提取到了。原理是卷积层中的特征map都会与上一层中的多个相邻连续帧相连,这样就有了时间上的信息了)。
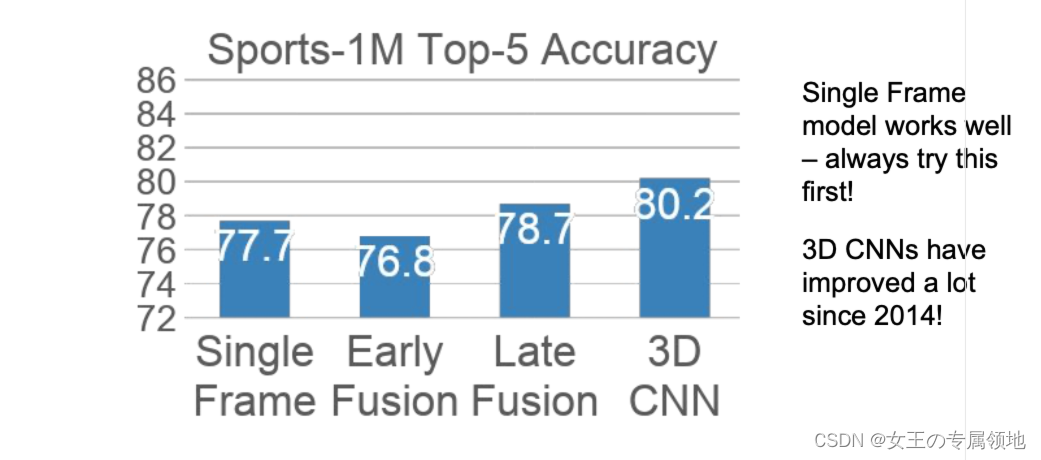
三种视频分类方法对比
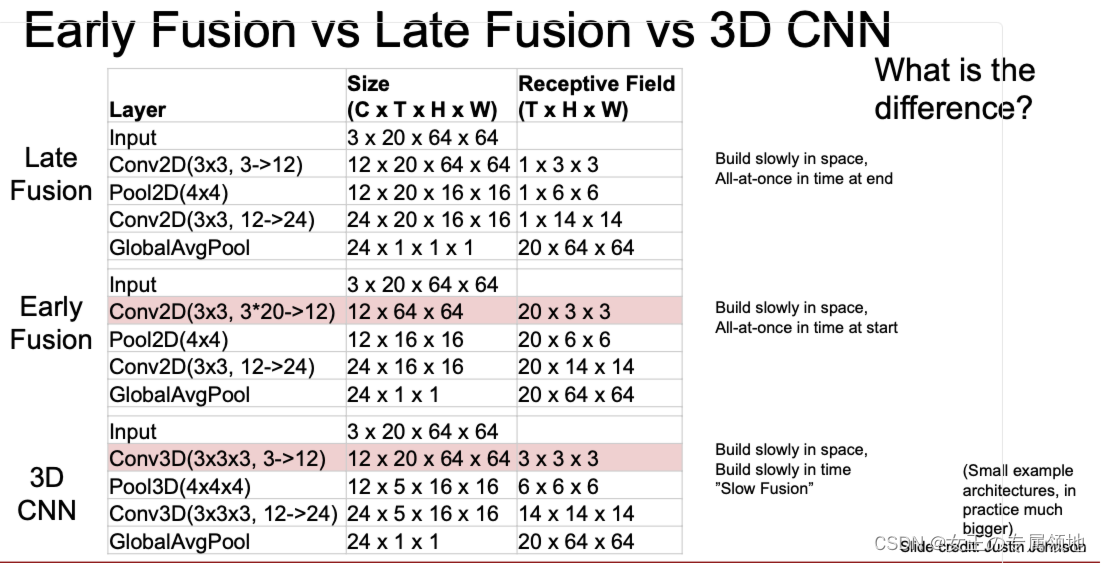
这三种方法中,最后融合的方法在空间上是逐步进行特征融合,同时时间上是最后进行融合。早期融合在空间上的融合也比较慢,同时时间上则是在开始就进行融合。而3D CNN则是空间上和时间上都是逐步进行融合。
二、双流网络(Two-Stream Networks)
光流(Optical Flow)
我们可以通过运动的信息来识别出运动的类别。同样在计算机中也有这种表示运动趋势的图像,那就是光流。光流被用于描述视频中物体的运动特征。通过提取光流,我们可以将背景中不必要的噪声 (视频中静止的部分) 全部忽略,只提取动作特征光流图像。
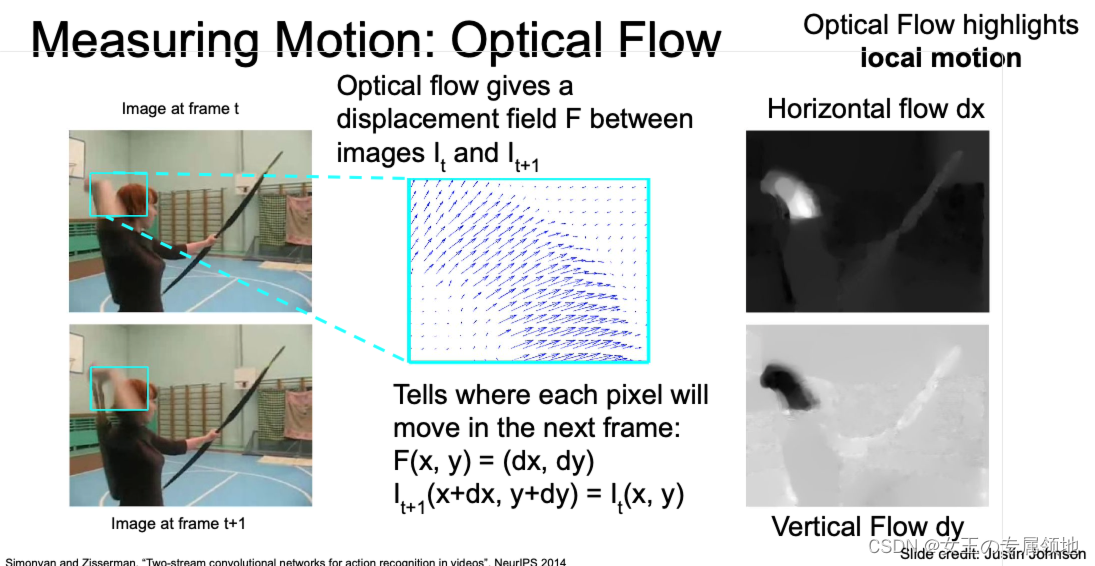
通过光流计算,能知道第i帧图像和第i+1帧图像之间的位移场,也就是说,光流图像告诉了我们在下一帧的时候,每个像素会移动到哪一个位置。
双流网络(分离运动和外观)(Two-Stream Networks)
通过光流算法可以了解运动的趋势。那么,通过光流算法,我们可以将运动和外观分开,再分别训练,从而得到视频的分类结果,这就是双流网络。
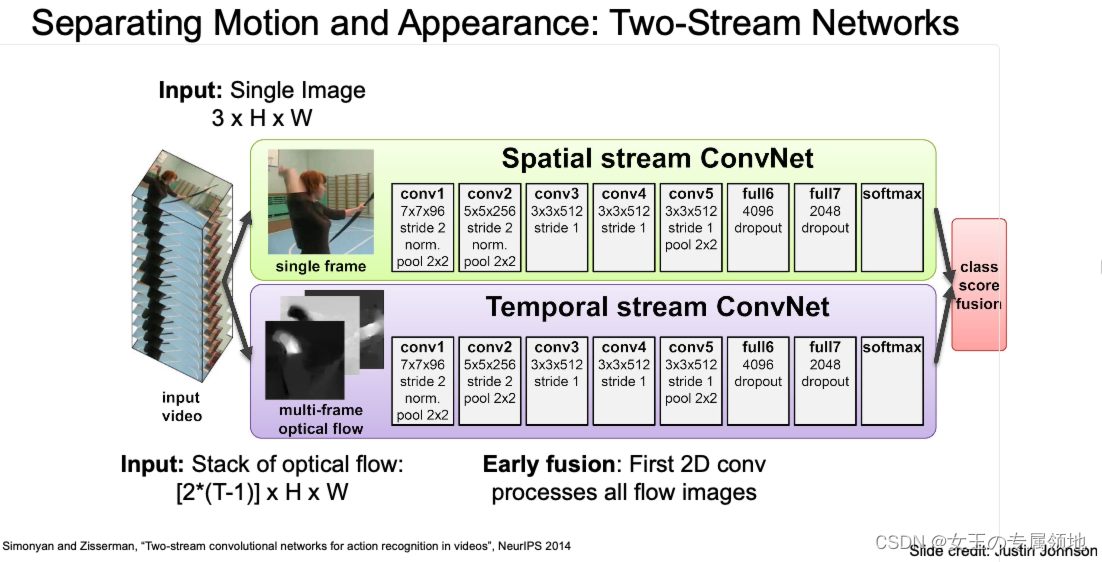
双流网络的一个形式主要就是有两个并行的网络结构。其中一个网络是处理视频的单帧图像(静态的),以提取外观特征。同时另一个网络则是处理多张光流帧,来获取时序运动信息。对于处理光流帧的网络,它运用的是早期融合的方式,先将所有的光流图像放在一起,再通过卷积神经网络进行处理。而对于整个网络,它是后期融合的方式,即在两个网络的最后,将静态帧的特征与动态帧的特征一起进行融合(后期融合的方法有两种:① 将两个网络流的softmax得分进行平均;②使用stacked
L
2
L_2
L2 -normalised softmax scores作为特征,以此来训练一个多分类线性SVM。
三、循环卷积网络
Non-Local Attention
到目前为止,我们只是使用卷积神经网络处理了一些非常短的视频(比如2-5秒)。
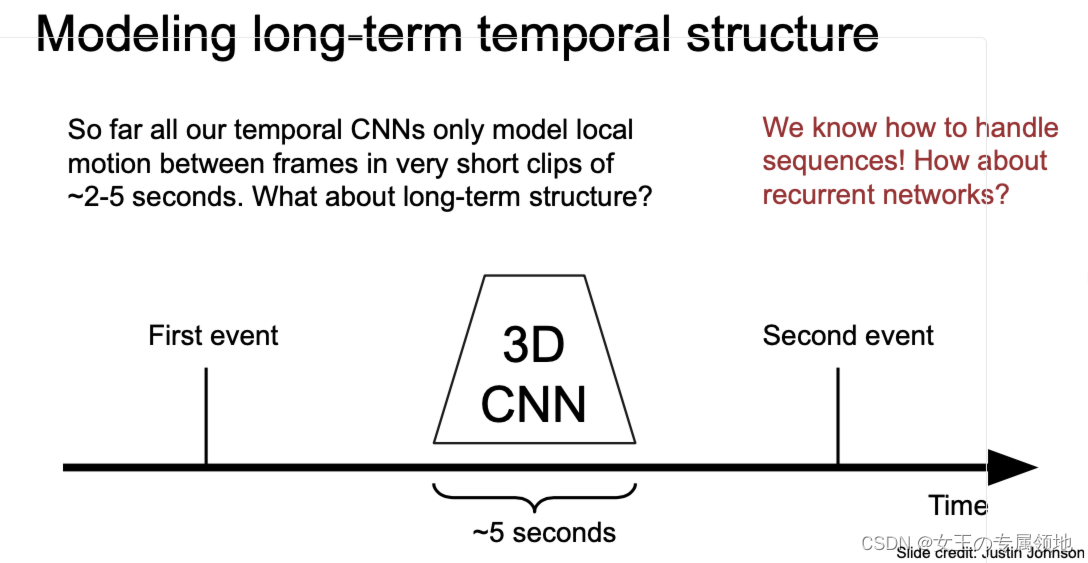
针对较长的视频,一个比较好的方法是利用循环神经网络结合卷积神经网络,也就是循环卷积网络来处理。循环卷积网络的结构与多层循环神经网络相似,只不过中间的处理是卷积层,它每次都依赖于两个输入,分别为来自同一层的前一时间步的输出以及前一层同一时间步的输出。同时在每一层都使用不同的权重并通过时间来共享权重。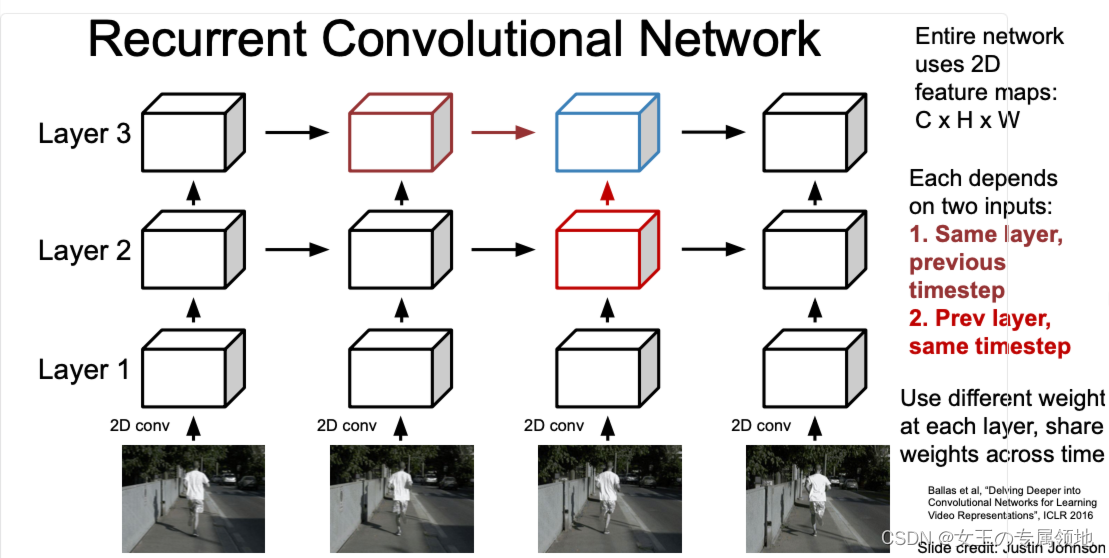
也就是说,对于第L层,时间为t的输出,是由第L层,时间为t-1的输出以及第L-1层,时间为t的输出作为输入,再类似于RNN的循环得到的。
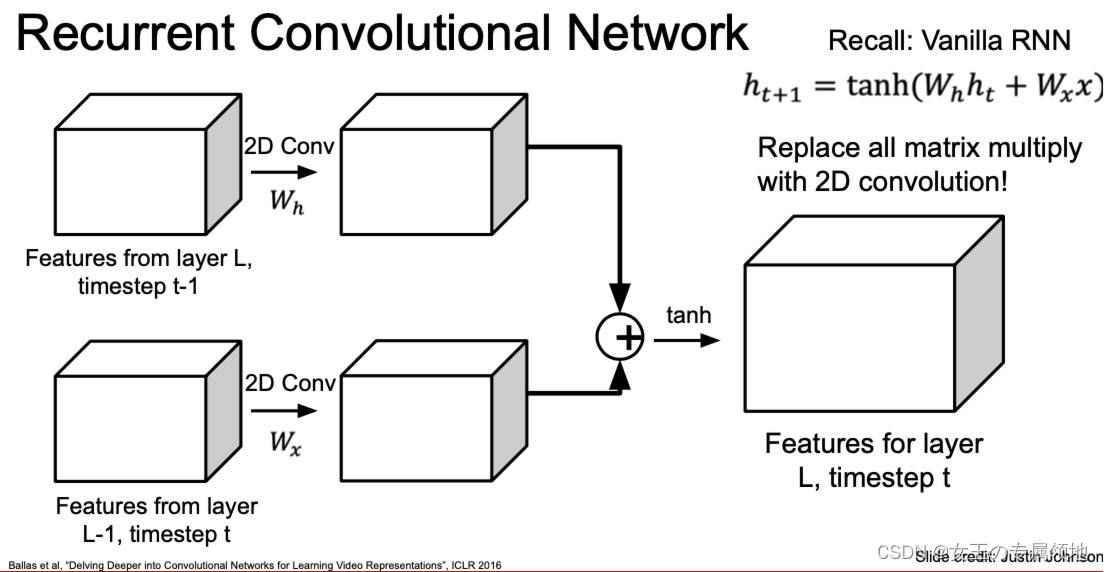
存在问题:处理较慢,引入自注意力机制
循环神经网络在处理长序列时速度会非常慢。同理,循环卷积网络在处理长序列时也会非常慢(因为不能并行处理)。对此,可以借鉴自注意力机制来获取长距离的特征信息,比如说Non-local attention。
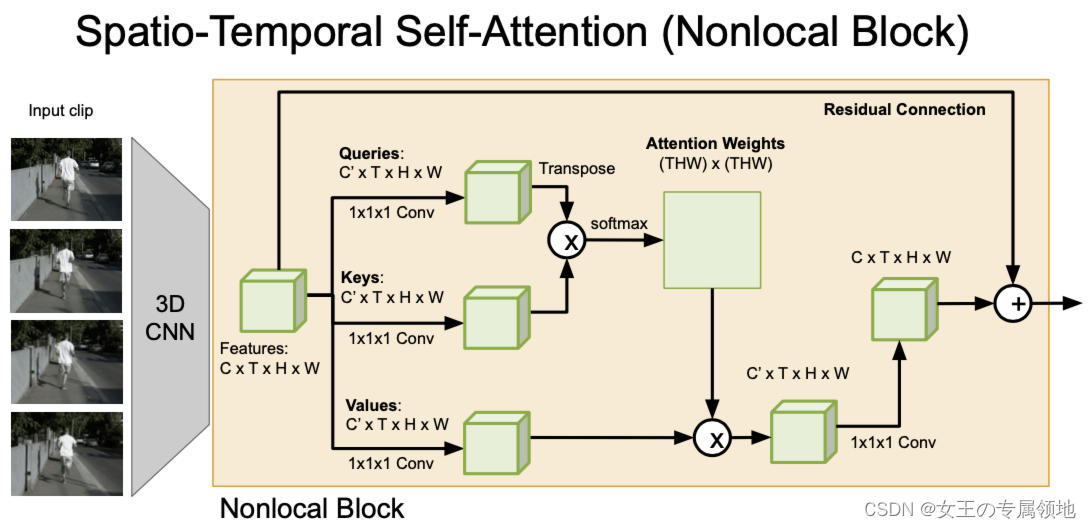
Non-local attention的流程:① 先通过三个1×1×1的3维卷积分别计算出q,k,v;②将q和k相乘之后进行sofmax,得到注意力权重;③ 将注意力权重与v相乘;④ 再通过一个卷积层之后与输入相加。
3D CNN
除了上面说的借鉴自注意力机制来处理视频之外,还可以借鉴其他的二维卷积神经网络框架来处理3维视觉(比如说Inception Block,就是将二维卷积变成三维卷积)。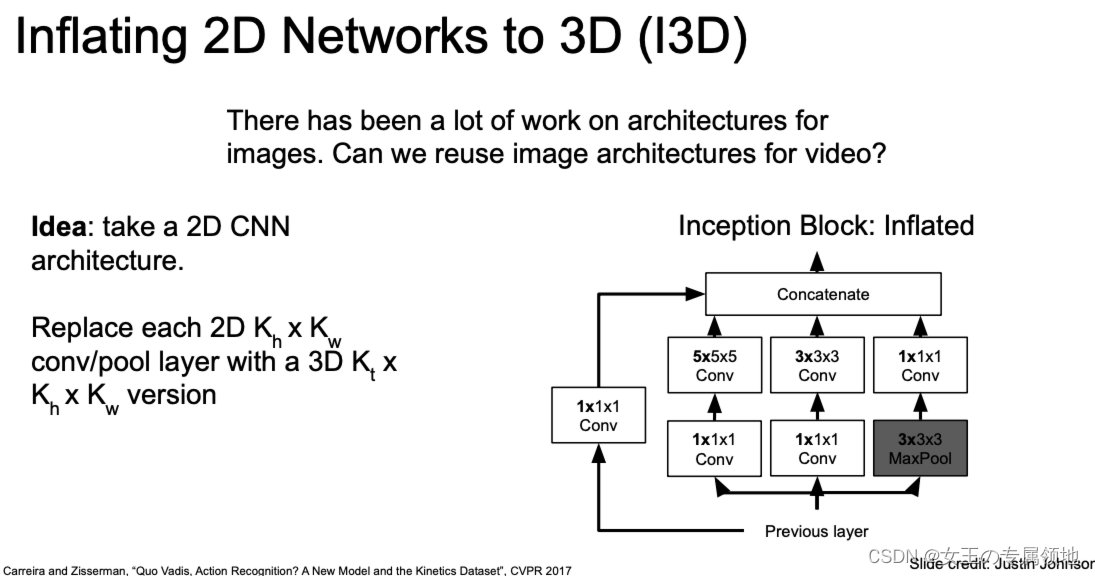
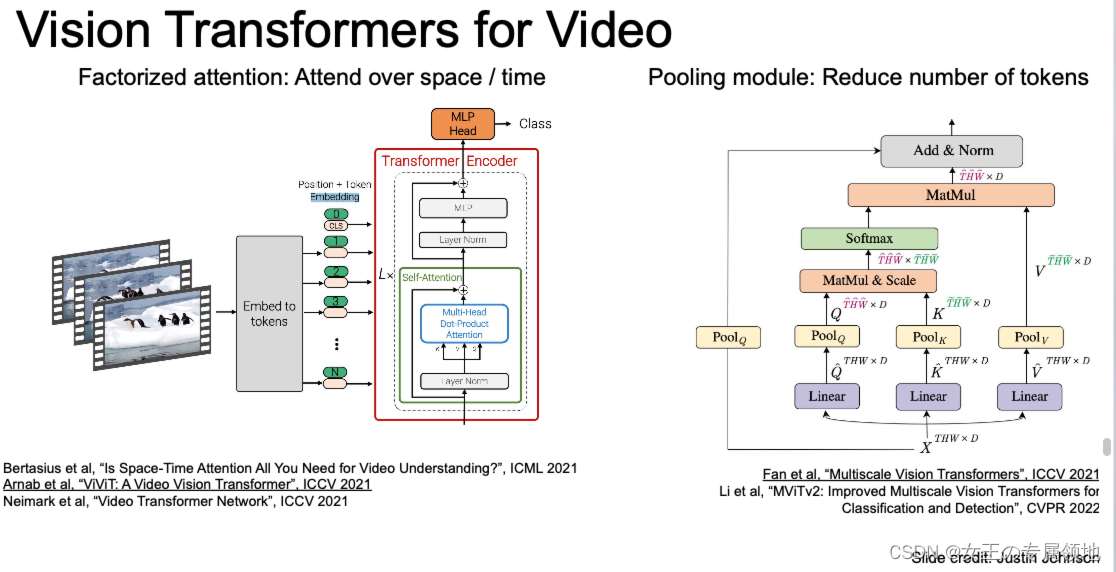
此外,还有Transformer也可以借鉴使用。
四、多模态视频理解(Multimodal video understanding)
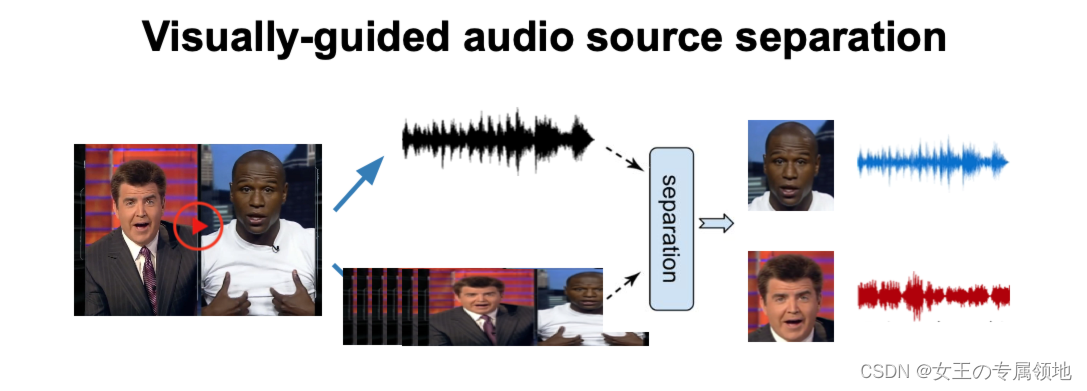
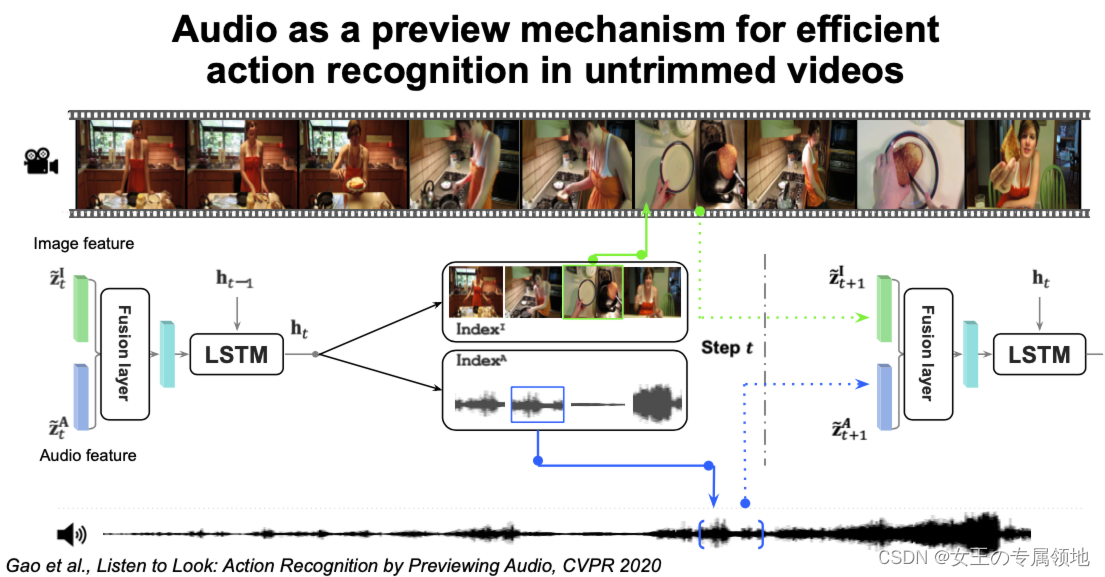
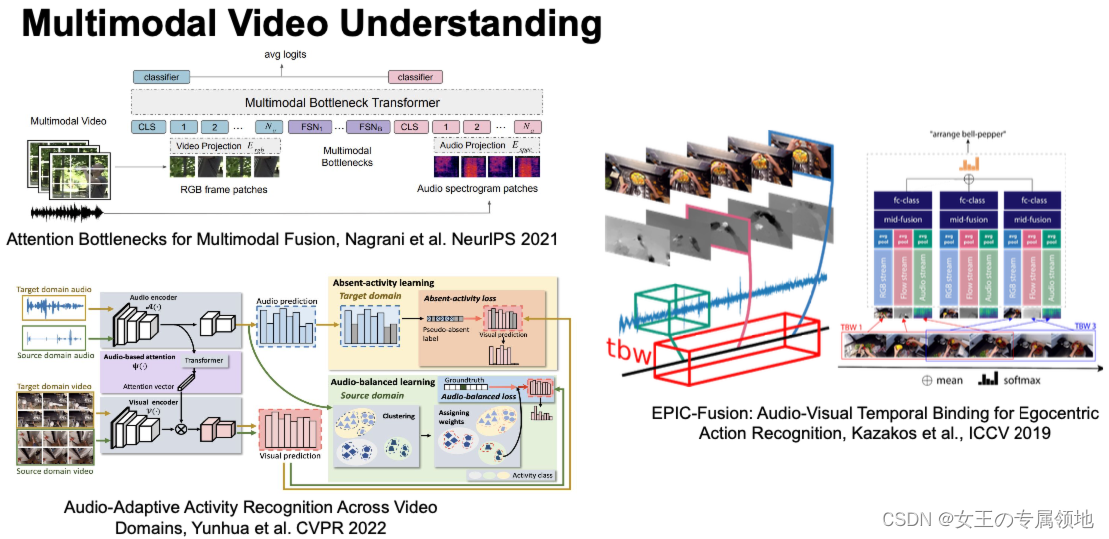
在这讲中,我们了解了深度学习在视频中的一些应用,以及如何应用,3D卷积网络来对视频分类,使用前期融合或者后期融合,再用2D卷积网络来分类;利用光流的特点,使用双流网络来对视频进行分类;结合循环神经网络和卷积神经网络的优点,使用循环卷积网络对长序列的视频进行分类(或者检测等),对于循环卷积网络,可以借鉴自注意力机制来对改善其运行缓慢的不足等。可以利用不同模态的数据来分离同一个视频中不同的声音等。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











