









4 月 30 日,谷歌在其官方博客上发文称将开放 Images V4 数据库,并同时开启 ECCV 2018 公开图像挑战赛。
2016 年,我们发布了一个包含大约 900 万张图片、标注了数千个对象类别标签的数据集 Open Images。发布之后,我们一直在努力更新和改进数据集,以便为计算机视觉社区提供有用的资源来开发新模型。
今天,我们很高兴地宣布开放 Open Images V4,它包含在 190 万张图片上针对 600 个类别的 1540 万个边框盒,这也是现有最大的具有对象位置注释的数据集。这些边框盒大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。另外,这些图像是非常多样化的,并且通常包含有多个对象的复杂场景(平均每个图像 8 个)。

与此同时,我们还将宣布启动 Open Images 挑战赛,这将是在 2018 计算机视觉欧洲会议(ECCV 2018)上举办的一场新的对象检测挑战赛。Open Images 挑战赛将遵循 PASCAL VOC、ImageNet 和 COCO 等赛事的传统,但是其规模将是空前的。
Open Images 挑战赛在一下这几个方面将是独一无二的:
-
有 170 万张训练图片,其中有 500 个类别和 1220 万个边框注释;
-
与以前的检测挑战相比,将有更广泛的类别,包括诸如「fedora」、「snowman」等这样的新对象;
-
除了主流的物体检测外,本次挑战赛中在检测物体对时还将包括视觉关系检测,例如「woman playing guitar」。
训练数据集现在已经可以使用;一个包含有 10 万张图片的测试集将于 2018 年 7 月 1 日发布在 Kaggle 上。挑战赛提交结果的截止日期为 2018 年 9 月 1 日。
我们希望更大的训练集能够刺激对更复杂检测模型的研究,这些模型将超过当前 state-of-the-art 的性能;而从另一方面,我们希望 500 个类别能够更精确地评估不同探测器在哪些方面表现的更好。此外,拥有大量带有多个对象标注的图像,可以帮组你探索视觉关系检测,这还是一个热门的新兴话题,而且具有越来越多的子社区。
除了上述内容外,Open Images V4 还包含了 3010 万张经过人工验证的针对 19794 个类别图像级标签的图片。当然这些标签不属于挑战赛的一部分,其中的 550 万张图像级标签是由来自世界各地成千上万名用户通过 crowdsource.google.com 生成的。
Open Images V4数据集
Open Images是一个由900万张图片组成的数据集,这些图像被标注为图像级标签和对象边界框。V4的训练集包含了600对象类的1460万个图像,其中共标记了174万个标记目标,这使得它成为现有的最大包含对象位置注释的数据集。这些物体的边界框大部分是由专业的注释器手工绘制的,以确保准确性和一致性。这些图像非常多样,通常包含有多个对象的复杂场景(平均每个图像有8.4个标记)。此外,数据集还带有数千个类的图像级标签。

数据组织结构
数据集被分割为一个训练集(9,011,219图像),一个验证集(41620个图像)和一个测试集(125,436张图片)。这些图像被标注了图像级标签和边界框,如下所述。
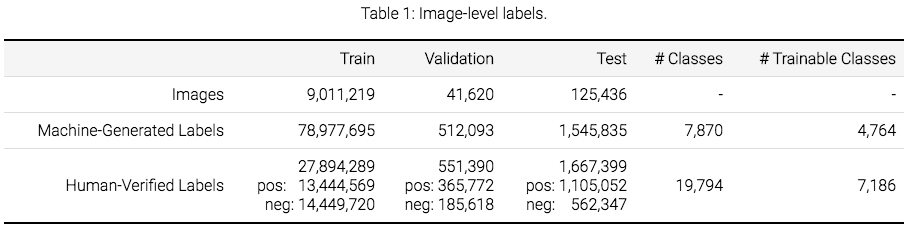
表1
表1显示了数据集的所有子集中的图像级标签的概述。所有的图像都有机器生成的图像级标签,这些标签是由类似于Google Cloud Vision API的计算机视觉模型自动生成的。这些自动生成的标签有一个很大的假正率。
此外,验证和测试集,以及部分训练集都包含经过人工验证的图像级标签。大多数验证都是由Google内部的注释者完成的。更小的部分是通过图片标签软件来完成的,如Crowdsource app, g.co/imagelabeler。这个验证过程实际上消除了假阳性(但不是传统意义上的假阴性,这种方式会导致一些标签可能在图像中丢失)。由此产生的标签在很大程度上是正确的,我们建议使用这些标签来训练计算机视觉模型。使用多个计算机视觉模型来生成样本,这样做是保证在训练时不仅仅用机器生成的标签数据,这就是为什么词汇表被显著扩展的原因,如表一所示。
总的来说,有19995个不同的类和图像级标签。请注意,这个数字略高于上表中人工验证的标签的数量。原因是在机器生成的数据集中有少量的标签并没有出现在人工验证的集合中。可训练的类是那些在V4训练集中至少有100个正例的人工验证类。基于这个定义,7186个类被认为是可训练的。
边界框

表2
表2显示了数据集的所有分割中边界框注释的概述,它包含了600个对象类。这些服务提供的范围比ILSVRC和COCO探测挑战的范围更广,包括诸如“fedora”和“snowman”之类的新对象。
对于训练集,我们在174 万的图像中标注了方框,用于可用的阳性人工标记的图像级标签。我们关注最具体的标签。例如,如果一个图像包含汽车、豪华轿车、螺丝刀,我们为豪华轿车和螺丝刀提供带注释的标注方框。对于图像中的每一个标签,我们详尽地注释了图像中的对象类的每个实例。数据集共包含1460万个的边界框。平均每个图像有8.4个标记对象。
对于验证和测试集,针对所有可用的正图像级标签,我们提供了所有对象实例详尽的边界框注释。所有的边界框都是手工绘制的。我们有意地尝试在语义层次结构中尽可能详尽地标注注释框。平均来说,在验证和测试集中,每个图像标记了5个边界框。
在所有的子集中,包括训练集、验证集和测试集中,注释器还为每个边界框标记了一组属性,例如指出该对象是否被遮挡。
类定义(Class definitions)
类别由MIDs(机器生成的id)标识,可以在Freebase或Google知识图的API中找到。每个类的简短描述都可以在类中CSV中找到。
统计和数据分析
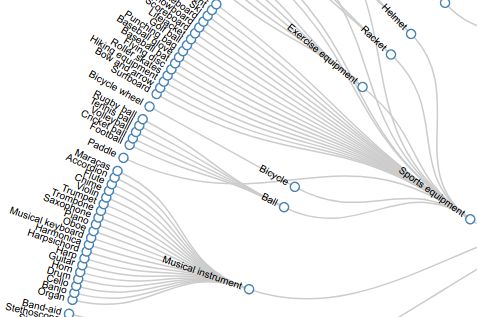
600个可标记类的层次结构
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











