








美团22年sigir的一篇短文,关于浮动广告位的。
问题建模
将广告分配建模为马尔科夫决策过程,利用强化学习来优化
元素定义
- 状态空间: 广告序列,自然item序列,user的特征,上下文特征,user页面级别的历史行为序列(共四种,下单、点击、下滑和退出)。其中文章的一个重点就是将页面级别的行为特征建模并引入到模型决策过程中。
- 行为空间:将是否当前位置分配广告设置为行为。具体由0,1序列组成。

- 奖励: 当前状态所采取的行为,对应的奖励会定义为广告的收益+服务费用,具体是如何根据用户反馈(包括哪些?下单?点击等?)来计算的reward还需要通过代码来辨别。
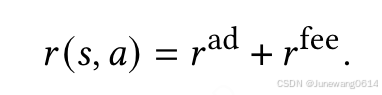
- 状态转移方程: P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at),含义是在 s t s_t st状态下采取行为 a t a_t at后,状态变为 s t + 1 s_{t+1} st+1。当用户退出了,状态转移也就结束了。
- 折扣因子
DPIN
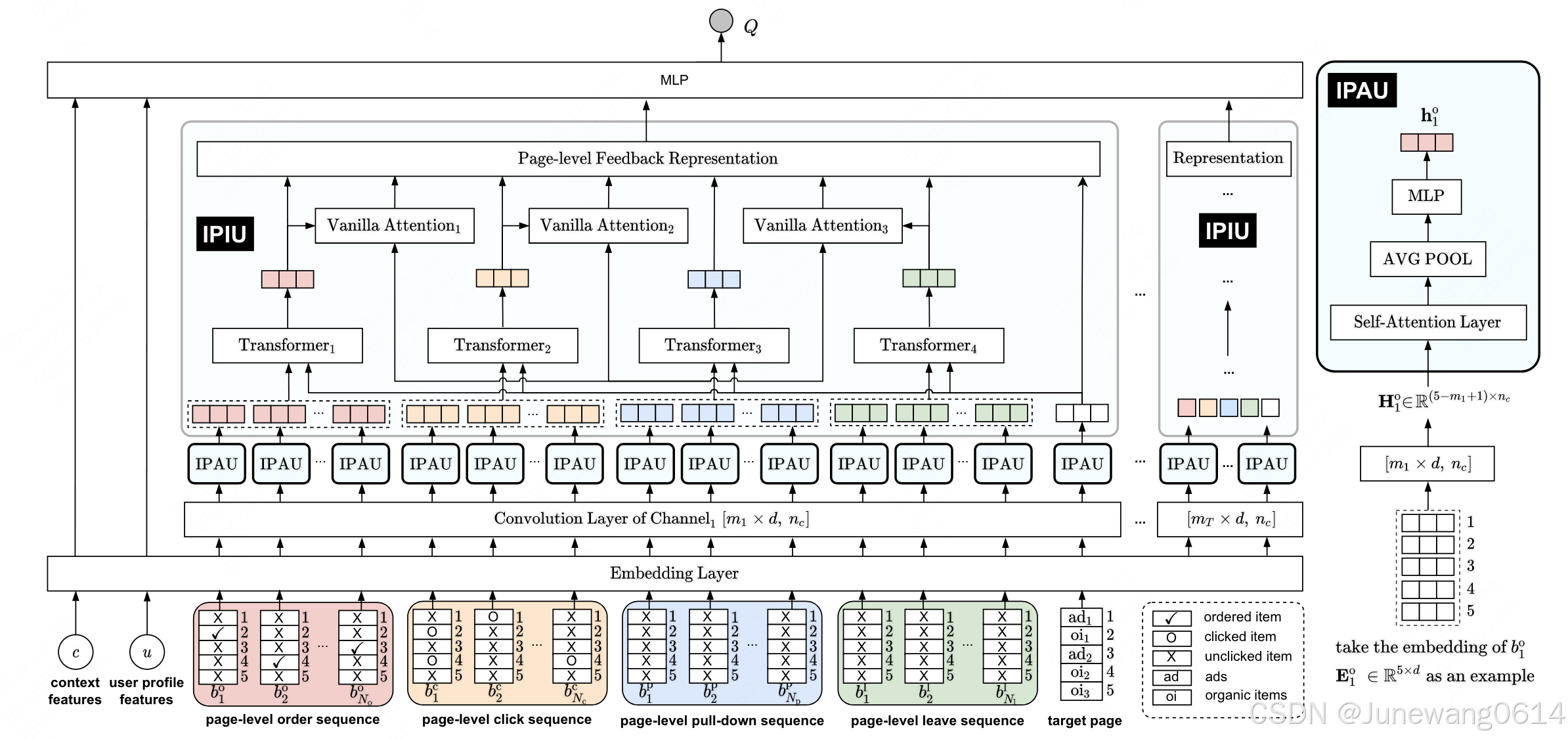
方法流程
embedding层
- 广告序列和自然序列,根据行为a的设置,排列成了page-level的格式,即图中的target。也可以看作是一种page-level的特征,编码方式可以仿照对page-level用户行为的编码。

- 每个页面有K个item,相应的page-level的嵌入表示用
E
∈
R
K
×
d
E \in R^{K \times d}
E∈RK×d 来表示。页面组成了行为序列则就再加一个序列长度的维度。target页面表示为
E
t
E^t
Et。

对于嵌入,目前先简单理解为所有的item(包括广告和自然item)都有一个通过id获得的嵌入表示。这些嵌入拼来拼去组成页面的表示。问题:E如何表示页面行为呢?感觉行为有相应的mask。
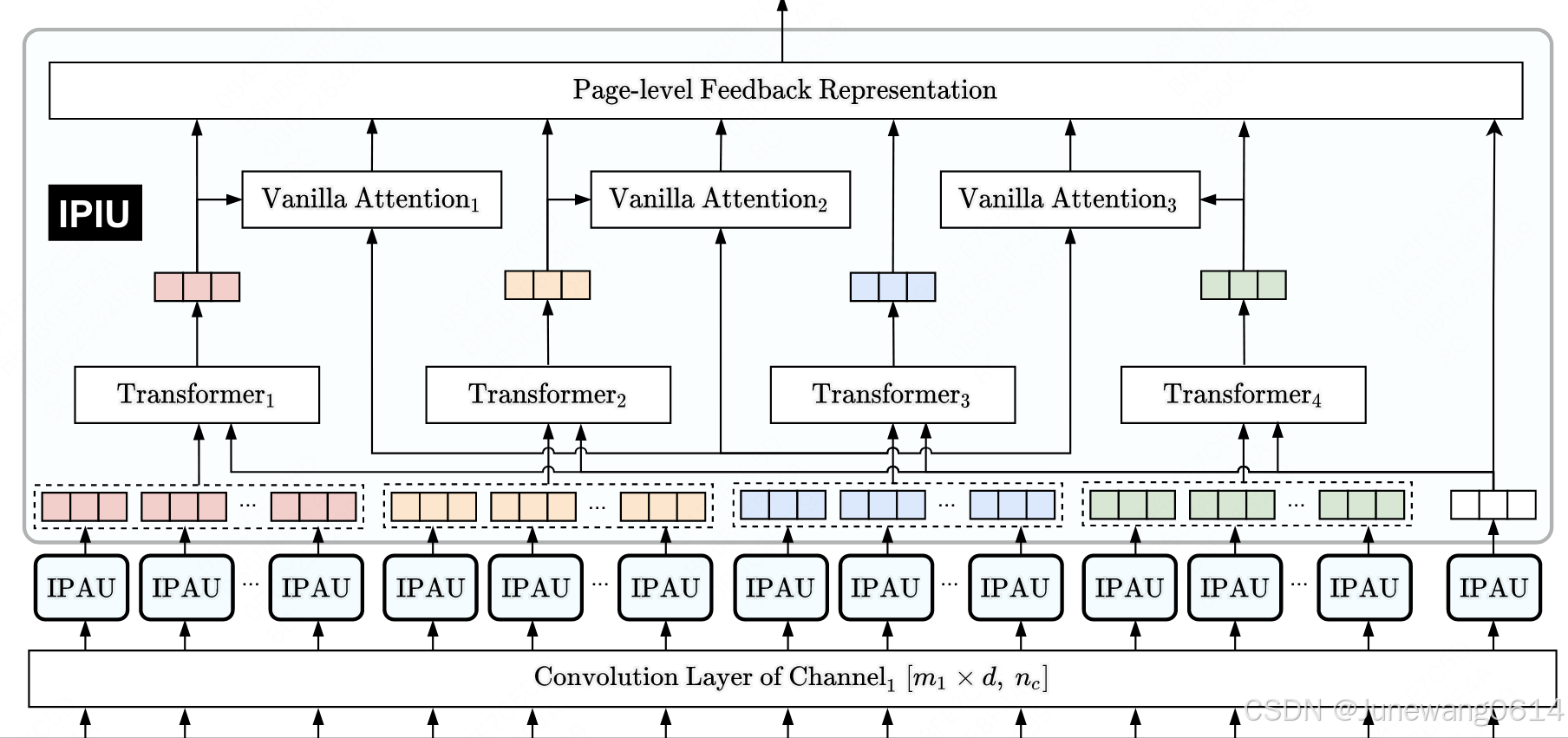
Multi-Channel Interaction Module (MCIM)
用于建模page-level的用户偏好,如果对target采用这种操作,每个位置倒是都考虑了其上下文的情况。
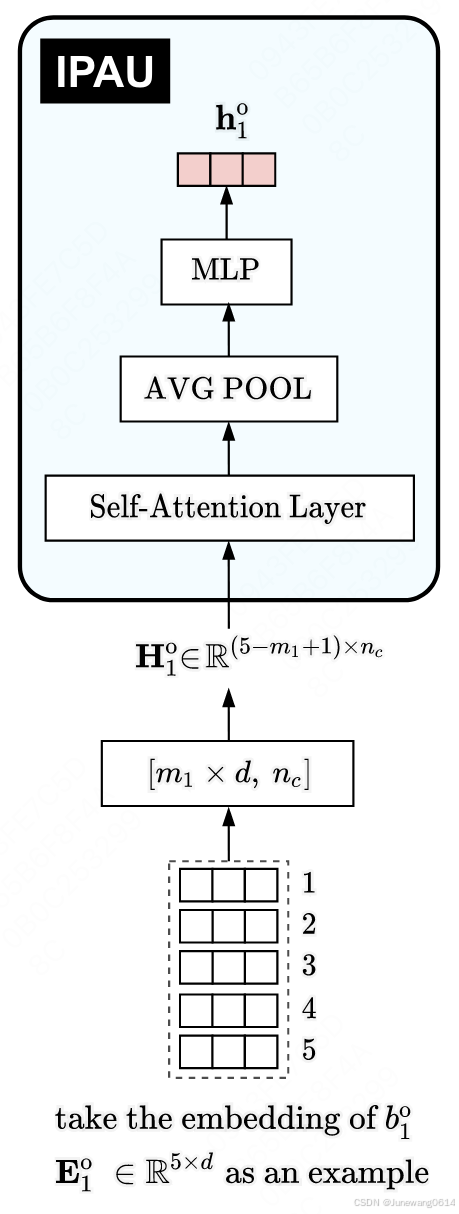
- 对每个页面进行卷积操作,将形状变为 H 1 ∈ R ( K − m + 1 ) × n c H_1 \in R^{(K-m+1) \times n_c} H1∈R(K−m+1)×nc。“页面item个数”和表示维度都变了。
问题: 为啥改页面item的个数啊?这样获得的表示难道不会对应不到每个具体的item上吗?
-
(IPAU模块)调用一个attention,可以获得整个页面内部相互的表示和关系。但是当前页面序列大小变成了 ( K − m + 1 ) (K-m+1) (K−m+1)。好像也不重要,最后进行了avg pooling,每一个页面就一个表示了,是h。
-
(IPIU模块)建模行为序列间的关系。
一共4种用户序列行为,每一种页面行为获得对应的页面表示以后,能够组成一个[seq_len, dim]的序列表示,加上target页面的表示,即变为了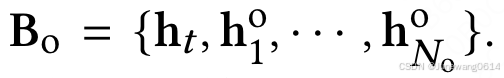
然后将这个再经过一个多头注意力网络,获得该序列的一个整体表示,用 z z z表示。就是图中的transformer那一部分。 -
(IPIU模块)矫正部分。作者说pull down特征可能会引入噪声,要根据其他的page-level的行为来矫正这个特征,于是将pull down每一个页面级的特征表示( h p h^p hp) 和其他三种行为做个类DIN 的操作构建关系,然后再这样获得一版序列整体表示。以下单行为为例:
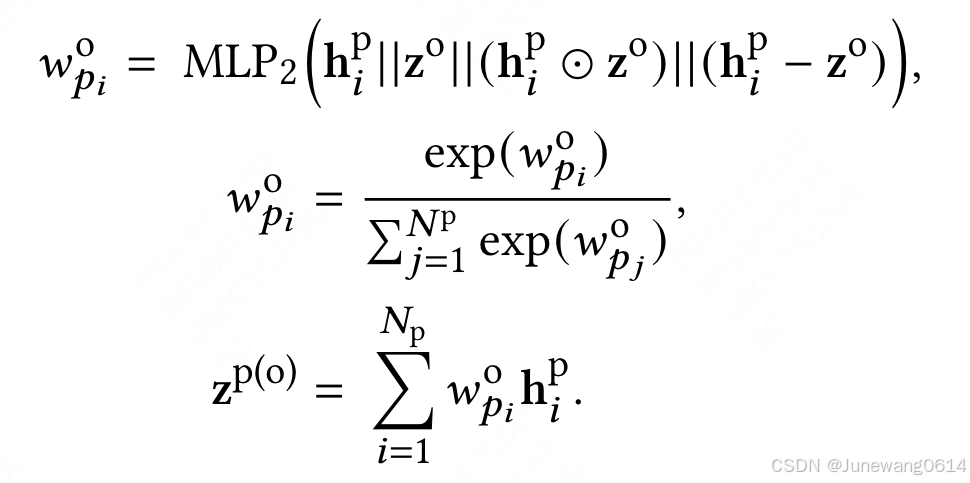
-
最后的连接,将4种序列级状态连接3个矫正后的pull down状态,结合target页面级别状态,获得第i个kernel级别的总状态 C i C_i Ci。MCIM的整体状态是由T个kernel对应的状态拼接而成。
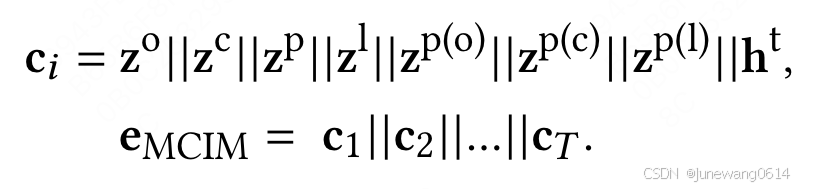
优化目标
- 获得的MCIM的状态结合user嵌入表示和上下文嵌入表示后,用于生成Q值。
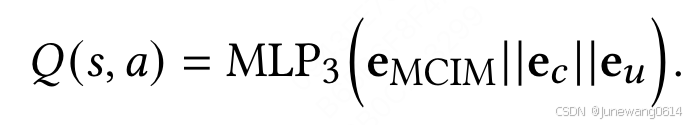
- 优化采用Q-learning的方式
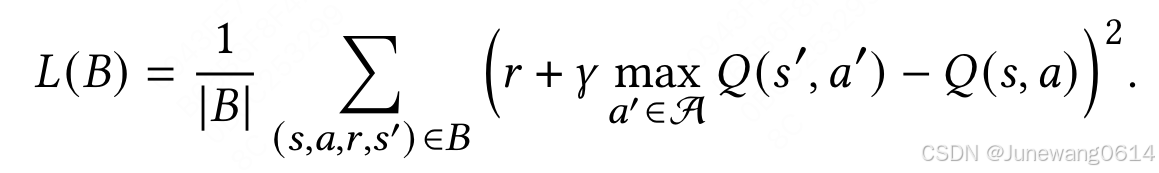


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









