







 本文介绍了一种名为RECFORMER的新方法,它通过学习语言表征解决序列推荐中的冷启动和跨域问题。RECFORMER使用键值对表示item,结合Longformer编码文本,通过预训练和微调框架,实现了语言理解和推荐的联合,从而实现知识迁移。实验结果显示,RECFORMER在多种数据集上表现优秀,特别是在低资源场景中展现了潜力。
本文介绍了一种名为RECFORMER的新方法,它通过学习语言表征解决序列推荐中的冷启动和跨域问题。RECFORMER使用键值对表示item,结合Longformer编码文本,通过预训练和微调框架,实现了语言理解和推荐的联合,从而实现知识迁移。实验结果显示,RECFORMER在多种数据集上表现优秀,特别是在低资源场景中展现了潜力。
文章目录
今年KDD上一篇paper,通过学习语言表征的方式进行序列推荐,特点之一是摒弃了传统推荐中使用的ID,用key:value格式的item属性,也就是item的内容来表示item。

INTRODUCTION 逻辑
-
任务场景:序列推荐,即按照时间顺序建模用户历史的交互,基于此,推荐用户可能感兴趣的潜在item。
-
传统序列推荐方法面临的challenges:传统的推荐模型将item转为原子ID,然后创建embedding table对item ID进行编码作为item的表示。embedding table会在模型训练中根据user-item的交互数据不断更新。这就是ID-based方法。这种方法面临的问题有:
- 推荐中冷启动问题(新的item因为没有训练过表示从而得不到合适的推荐)
- 跨域推荐或者说不同数据集的迁移问题(每个数据集都定义原子ID,纵使不同领域的item有所关联,比如同名的电影和小说之间的联系,传统的方法也无法将模型进行很好的迁移)。
因此,一个能进行迁移的推荐模型能够适应于冷启动场景和跨域推荐场景。
-
现存可迁移的推荐系统的限制:
- 先前的可迁移推荐系统的工作通常假设共享信息是可用的,比如两个领域之间user-item交互上的重叠、共同的特征等,然后通过学习语义映射或者迁移组件来减少不同领域之间的gap。而这种假设在真实场景下通常很难达成。
- 还有一些方法是以自然语言作为通用接口。一种基本的想法是利用一个预训练的语言模型来获得文本表示,然后学习文本表示到item表示的转换,从而实现不同推荐领域之间的知识迁移。这样的方法目前存在的限制是:
- 预训练模型训练语料(通用语言领域)和item text之间存在gap,导致通过模型获得的item text的文本表示往往是次优的。
- 预训练模型的文本表示无法学习不同项目属性的重要性(这一点没太理解,这难道不是因为输入文本构造的问题吗?)
- 预训练模型的训练目标和推荐模型训练目标的不一致,导致预训练模型的推荐能力没有被充分挖掘。(预训练模型训练目标一般是MLM,而序列推荐是预测下一项item)-> 联合训练。
-
所提方法:一个能为序列推荐有效学习语言表示的框架,RECFORMER。一个将自然语言理解和推荐统一的ID-free序列推荐范式。通过自然语言理解和推荐任务的联合训练,从而利用语言模型的通用性实现推荐中的知识迁移。为了实现这个idea,作者认为有三个challenge需要解决:
- 当item输入到语言模型中时,需要一个统一的输入数据格式,要求这种格式足够灵活能够包含各类item的文本信息。(感觉这个不能算是challenge,,item的文本信息最终想要输入到语言模型中还是需要转成文本句子的形式,论文中的方法也是展平成item ‘sentence’)
- 在一个框架中,如何同时建模语言和item的序列关系?item和item文本如何在模型中对齐?
- ID-free的方法下,如何在没有item embedding table的情况下,根据语言模型对item进行有效排名而产生推荐?(推荐是通过ranking模型产生的)
-
RECFORMER的流程
- (解决第一个challenge)将item用key-value对表示,key是item的属性类型,value是item的属性。
- 使用基于Longformer的双向Transformer来编码item的text,这是一种encoder-only的模型,能够编码比较长的序列。
- 为了进行有效的语言表征学习,为模型设计了训练框架,包括预训练、微调和推理阶段。
-
整体逻辑:序列推荐challenge -> 需要有迁移能力的推荐模型,目前可迁移方法的限制 -> 为了解决上述限制,想到的idea,提出的方法。-> 所提方法的实施过程。
RECFORMER方法
recformer方法的结构图如图所示。
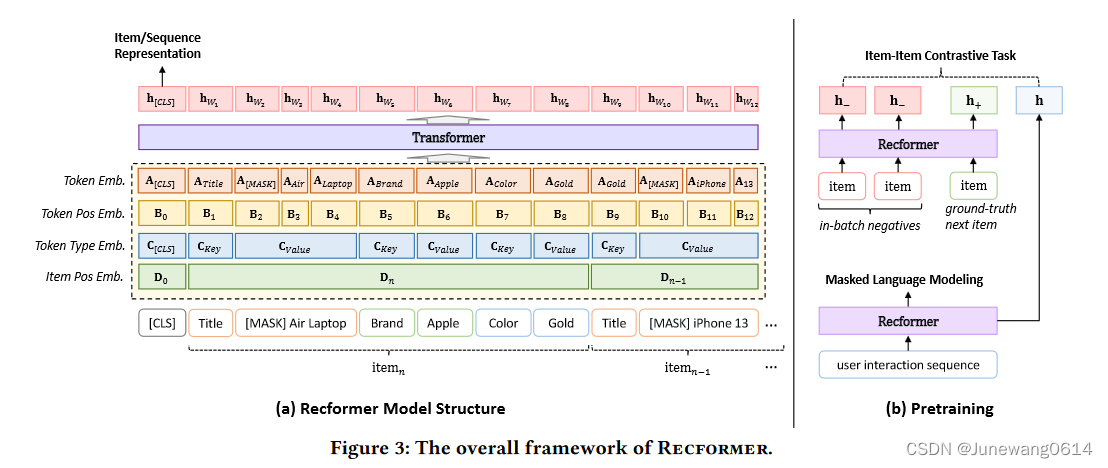
模型结构
模型input
- 对item的表示:每个item根据自己的属性建模为一个dictionary D i { ( k 1 , v 1 ) , ( k 2 , v 2 ) , … , ( k m , v m ) } D_i \left \{ (k_1,v_1),(k_2,v_2),\dots,(k_m,v_m) \right \} Di{(k1,v1),(k2,v2),…,(km,vm)}。为了能输入到语言模型中,将这个dictionary展平为一个item sentence: T i = { k 1 , v 1 , k 2 , v 2 , … , k m , v m } T_i = \left \{k_1,v_1,k_2,v_2,\dots,k_m,v_m \right \} Ti={k1,v1,k2,v2,…,km,vm},其中k和v都是由单词构成的,比如{’color’:‘red’}。item表示的输入最终构造为: X = { [ C L S ] , T i } X = \left \{ [CLS],T_i \right \} X={[CLS],Ti}
- 对user的表示:用户与item的交互序列用来表示user。序列按照时间顺序排列,但构造模型输入的时候会将该序列倒转,因为需要保证越近的交互能够出现在user的表示中而不是被截断。因此user表示的输入最终构造为: X = { [ C L S ] , T n , T n − 1 , … , T 1 } X = \left \{ [CLS],T_n,T_{n-1},\dots, T_{1} \right \} X={[CLS],Tn,Tn−1,…,T1}
模型嵌入层
如图所示,在输入到Transformer之前,模型的input会转为4种embedding,以此让模型能够从语言理解和推荐中的序列模式两方面感知模型的输入文本。这4种embedding融合了语言模型和序列推荐模型中的embedding层。
- Token embedding,对输入文本中每个单词进行embedding。 A ∈ R V w × d A\in \mathbb{R}^{V_w\times d} A∈RVw×d, d d d就是这种embedding的维度。
- Token position embedding,对输入文本按照每个单词进行position embedding(源自语言模型的设置), B i ∈ R d B_i \in \mathbb{R}^d Bi∈Rd,维度为 d d d。
- Token type embedding,类型的embedding主要分为三类 C [ C L S ] , C k e y , C v a l u e ∈ R d C_{[CLS]},C_{key},C_{value} \in \mathbb{R}^d C[CLS],Ckey,Cvalue∈Rd,分别表示当前的token是[CLS]还是key还是value,维度也为 d d d。这应该也是源自语言模型设置?special token?
- Item position embedding,用于表示当前的token是属于序列中哪个item的内容,这个用来感知输入中的item序列,源自序列推荐任务。 D k ∈ R d D_k \in \mathbb{R}^d Dk∈Rd,维度为 d d d。
问题:token embedding可以用预训练语言模型的embedding初始化,剩下三个embedding是有单独的可训练的embedding层还是根据计算而固定的?
解答:作者代码实现中自定义了一个embedding层,其中这四个都是nn.Embedding的方式定义的。应该都是可学习的参数。
获得了由四种embedding构成的整体的输入embedding后,进行layer normalization。整个embedding层的计算如下面公式所示:
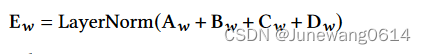
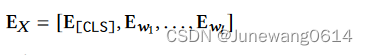
模型encoder Longformer
获得了模型输入
X
X
X的嵌入层结果
E
X
E_X
EX后,对
E
X
E_X
EX进行编码。采用基于Longformer的Transformer结构,其中
[
C
L
S
]
[CLS]
[CLS]包含了全局注意力,其他位置都是局部窗口注意力。Recformer对
E
X
E_X
EX的编码获得隐状态的表示如下:
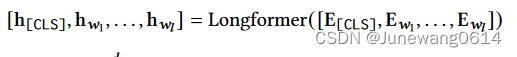
而其中
h
[
C
L
S
]
h_{[CLS]}
h[CLS]获得是整个输入的句子的表示。如果input的句子是item的表示,通过这一步获得的
h
[
C
L
S
]
h_{[CLS]}
h[CLS]就可以看作是模型对这个item的隐状态表示,同理,如果输入是user的句子,则
h
[
C
L
S
]
h_{[CLS]}
h[CLS]是模型对这个user的隐状态表示。
预测
预测方面和之前的方法类似,通过计算user的表示
h
s
h_s
hs和item的表示
h
i
h_i
hi之间的相似度来获得user和item之间的得分,这里用的是cosin相似度。在item全集上进行得分的计算,对得分进行排序,得分最高的item作为对下一个用户可能进行交互的item的预测。
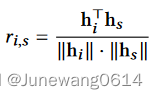
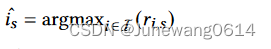
小小总结
这里感觉作者描述的挺清晰的,包括模型的输入构造,如何获得user、item的表示,如何进行预测等。
- 这里可以看到input相较于之前的方法,也可以看作被分为了两部分。item角度的部分 X = { [ C L S ] , T i } X = \left \{ [CLS],T_i \right \} X={[CLS],Ti},user角度的部分 X = { [ C L S ] , T n , T n − 1 , … , T 1 } X = \left \{ [CLS],T_n,T_{n-1},\dots, T_{1} \right \} X={[CLS],Tn,Tn−1,…,T1},相当于输入的句子有两类。
- 两类句子通过transformer获得的表示是同样维度的 h [ C L S ] ∈ R d h_{[CLS]} \in \mathbb{R}^d h[CLS]∈Rd,感觉也可以看作是两类表示, h s h_s hs和 h i h_i hi。
- 而预测部分则感觉和ID-based 方法是一脉相承的,user和item通过模型获得的表示进行点积计算相关度,当作user对item的打分,然后将得分进行排序获得推荐。
- 从这个角度总结的话,和ID-based方法的主要区别就是user、item表示的获取了。先前的方法都是有一个显式的item embedding table,通过item的ID索引查表获得item的表示。而这种方法中,item的表示是ID-free的,通过item的content info经过模型转成了item的表示。
现在个人的问题是,通过什么样的训练策略、训练目标,能够在一个模型中获得item和user的比较好的表示?细节方面就是上面对embedding层实现的一些疑问。 这些通过论文的后半部分和源码应该可以得到解答。
Learning Framework
预训练部分
预训练过程需要综合考虑自然语言理解与推荐两个方面,因此,作者采取了两个任务进行预训练。一个是Masked Language Modeling (MLM),一个是item和item之间对比任务。
- MLM任务:这个任务做的是随机遮盖某个word,看模型是否能预测出被遮盖的word的。能够防止语言模型在与其他特定任务联合训练的时候忘记单词语义。借助MLM任务,能够消除通用语言预料库和item文本之间的差距**(这是为什么呢?)**。对应的训练loss如下所示:

- item-item contrastive (IIC) task。 这个任务做的是对于正样本item,要让模型提高user的打分,对于负样本,则尽可能让模型降低user的打分。正样本就是训练数据中的groundtruth,负样本这里作者把同一个batch内的其他item作为负例。这是因为作者提出的recformer框架下,并不是很容易得就能获得负样本的表示,算是为了高效训练的一个设计吧。论文中也提到这是预训练部分,所以即使in-batch中会产生错误的负样本,也是无伤大雅。(感觉这种训练技巧要学习)对比的loss如下所示:
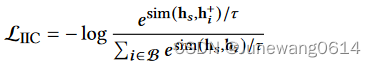
- 多任务训练的方式来联合训练这两个目标,所以综合的loss为:
L P T = L I I C + λ ⋅ L M L M \mathcal{L}_{PT} = \mathcal{L}_{IIC} + \lambda \cdot \mathcal{L}_{MLM} LPT=LIIC+λ⋅LMLM
【小总结】预训练部分总体来说就是两个任务MLM和IIC进行联合训练。从 λ \lambda λ的大小来看,MLM是辅助任务,IIC是主要任务。也就是预训练中需要尽可能让user的表示去靠近目标item,远离负样本item。(感觉这一步和学长的那篇工作中先用对比学习的方法训练模型中对doc和query的表示很像,或许要达成的目标是类似的)
两阶段的微调
核心idea是要获得item feature matrix, I ∈ R ∣ I ∣ × d \mathrm{I} \in \mathbb{R}^{|I|\times d} I∈R∣I∣×d。这个就类似于ID-based方法中的embedding table,还是要用个东西存储好item的表示。
两阶段的算法如图所示:

-
首先,这一阶段的loss function只有对比loss,具体为:
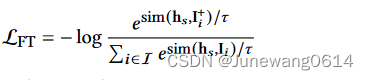
可以看到这一阶段,负例不再是in-batch,而是除了正样本之外 I I I中其他的item,也就是把剩下的所有item都作为负例。由于使用recformer编码item获得item的表示是一个很消耗资源的操作,所以作者设计了 I I I这个数据结构。 -
第一阶段,更新 I I I,也更新模型的参数 M M M。这里,为了高效训练,作者不会每个batch重新encode item的内容,从而获得item的表示。而是每个epoch,作者encode所有的item,然后保存在 I I I中,方便接下来训练的使用。
-
第二阶段,冻结 I I I,更新模型参数 M M M。这一阶段和第一阶段的不同主要体现在不会再训练item的表示table I I I了,而是只更新模型的参数,以通过稳定的训练达到最优的结果。
(问题,这里是怎么实现的,是怎么访问 I I I获得的想要的item的表示的?)
实验部分
设置
数据集
源自亚马逊的数据集。为了展现所提方法跨域的能力,
- 7个数据集用于模型的预训练,一个数据集作为验证数据。这些数据集都是source domain 数据集。
- 对于微调适应下游任务阶段,则采用了另外六个额外的数据集,这六个数据集是target domain。
- 数据集的处理上,删除了title欠缺的item,用商品的title,categories和brand来表示item。(好像没有提删除交互少于多少的用户和item)
- 数据集的划分上采用leave one out的划分方式。
baseline
主要分了三类:ID-based methods;ID + item side information ; ID-free methods,item text
- ID-based:GRU4REC,SASRec,BERT4Rec,RecGURU
- ID-Text methods : FDSA, S3Rec
- Text-only : ZESRec,UniSRec
实验结果
整体表现
Recformer在微调的6个数据集上的表现如表格所示:
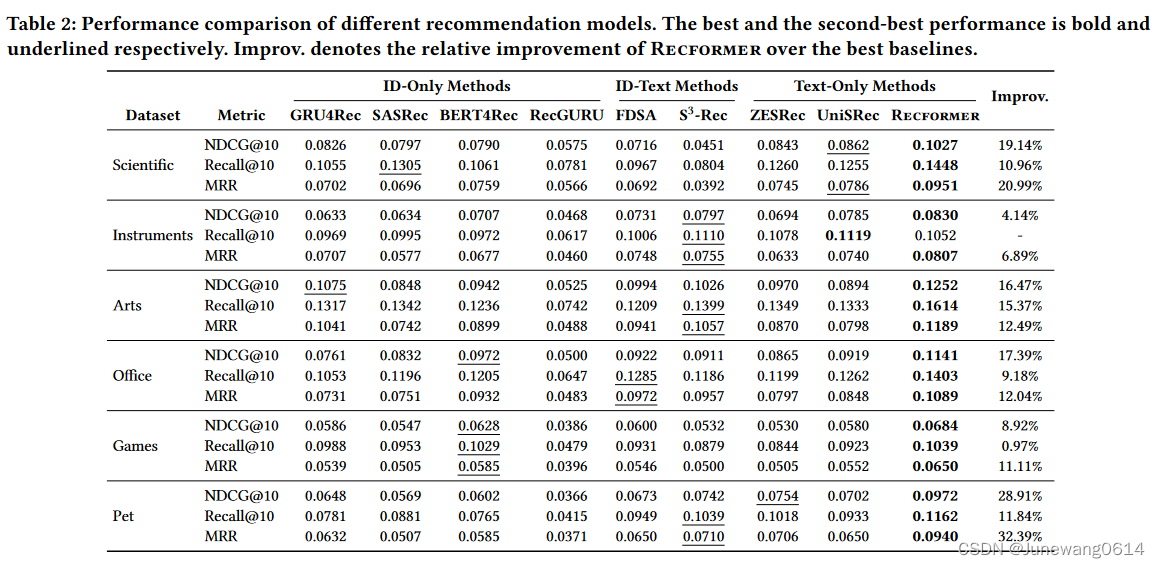
从实验结果可以发现:
- ID-Text的方法相较于其他的baseline方法能够得到更好的表现,作者认为这种方法不仅能够学到item的content feature(通过text),同时也能捕捉到序列模式(通过ID)
- Recformer在大部分情况下都取得了最好的结果,表现出提出的方法的有效性。
低资源表现
- zero-shot情况下。这种情况指的是对于上述微调的6个数据集,不会让模型通过里面的数据进行训练,而是直接用预训练完成的模型进行测试算指标。因为这种设置中ID-based的方法无法进行评估,所以作者将在完整数据集上训练的ID-based的baseline算是作为一个表现的参考吧,在图中以折线的方式表示。而Text-only的baseline在这种情况下可以评估,于是参与到和recformer的对比中。
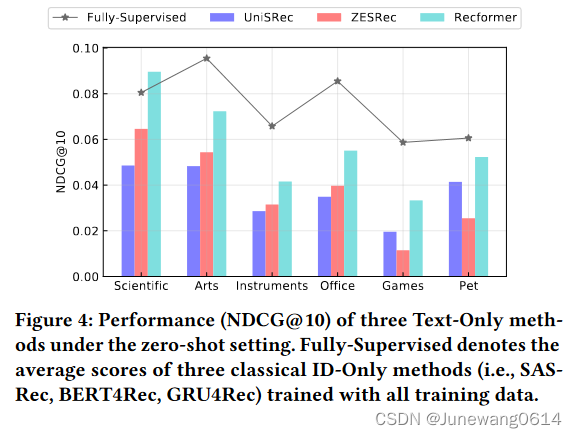
可以看到在zero-shot设置下,Recformer都取得不错的表现。作者认为这个结果能够说明:
(1) 自然语言作为不同推荐场景的通用item表示很有前景 -> text代替ID-based方法
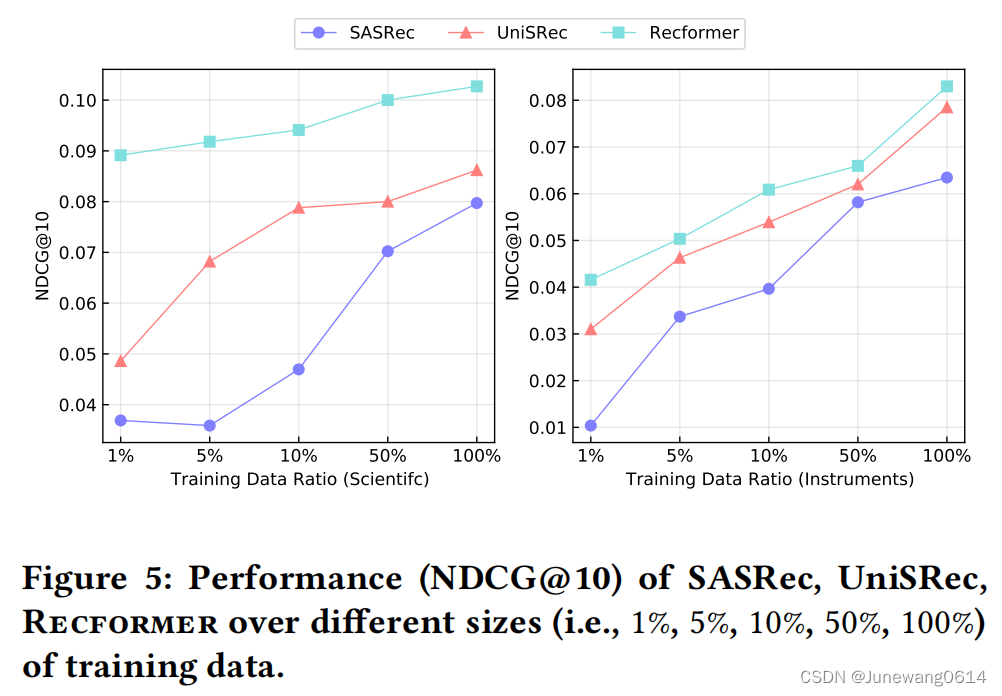
(2) Recformer可以有效地从训练前学习知识,并在语言理解的基础上将学习到的知识转移到下游任务中。满足作者一开始对于能够知识转移的推荐系统的设想。 - Low-Resource 这种条件下,将模型在下游任务数据集中训练,其中训练用的数据会根据不同的比例进行划分,结果如下图所示。ID-based方法中作者选取了SASRec,Text-only方法中选取了UniRec。结果能够反映出基于item text进行item表示的两种方法有融合先验知识并在新的领域中产生推荐的能力。但我感觉这个实验设置的有些问题,作者选取的两个下游任务数据集Scientifc和Instruments在全集上也是Text-only的方法表现更优,说服力不太强。

















 2487
2487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









