







为了方便实验,搭建一个Hadoop伪分布平台是很有必要的
一、所需的软件
VMwareworkstation-v9.0.1.zip
CentOS-6.4-x86_64-bin.iso (安装参考:云计算Hadoop部署和配置详情(一))
hadoop-2.0.0-cdh4.4.0.rar
cm4.7.3-centos6.tar.gz
二、安装软件
安装VMware
在虚拟机上安装CentOS
三、准备工作
关闭selinux
修改网络驱动配置
安装jdk (参考:云计算Hadoop部署和配置详情(一))
四、部署伪分布
1、/etc/yum.repo.d/ 首先确认此目录下已建立了以下三个文件:
(1)cloudera-cdh4.repo (cdh文件资源)
[cloudera-cdh4]
# Packages for Cloudera's Distribution for Hadoop, Version 4, on RedHat or CentOS 6 x86_64
name=Cloudera's Distribution for Hadoop, Version 4
baseurl=http://192.168.1.2/cdh/4/
gpgkey=http://192.168.1.2/cdh/RPM-GPG-KEY-cloudera
gpgcheck = 1
(2)cloudera-dvd-1.repo (Centos系统文件资源)
[cloudera-dvd-1]
# Packages for Cloudera's Distribution for Hadoop, Version 4, on RedHat or CentOS 6 x86_64
name=Cloudera's Distribution for Hadoop, Version 4
baseurl=http://192.168.1.2/dvd-1/
gpgkey=http://192.168.1.2/dvd-1/RPM-GPG-KEY-CentOS-6
gpgcheck=1
(3)cloudera-manager.repo (cm资源,安装jdk需要的)
[cloudera-manager]
# Packages for Cloudera's Distribution for Hadoop, Version 4, on RedHat or CentOS 6 x86_64
name=Cloudera's Distribution for Hadoop, Version 4
baseurl=http://192.168.130.56/cm/4/
gpgkey=http://192.168.130.56/cm/RPM-GPG-KEY-cloudera
gpgcheck=1
2、安装配置
yum install hadoop-conf-pseudo
rpm -ql hadoop-conf-pseudo
cp -r /etc/hadoop/conf.pseudo /opt/hadoop/conf/
alternatives --verbose --install /etc/hadoop/confhadoop-conf /etc/hadoop/conf.empty 10
alternatives --verbose --install /etc/hadoop/confhadoop-conf /etc/hadoop/conf 50
vim /var/lib/alternatives/hadoop-conf
sudo -u hdfs hdfs namenode -format
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudoservice $x start ; done
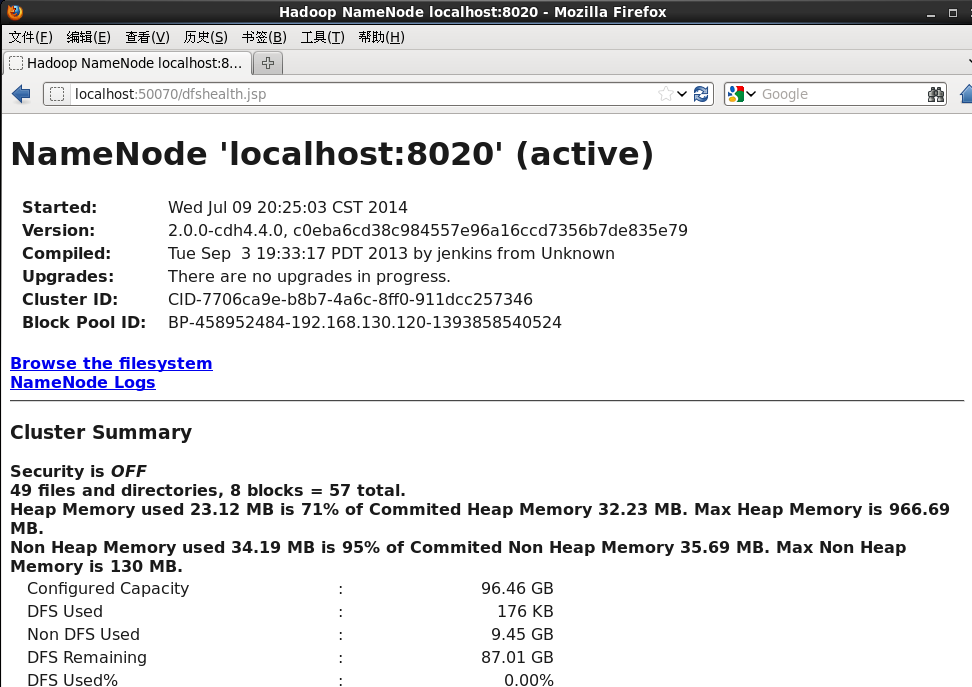
sudo -u hdfs hadoop fs -rm -r /tmp
sudo -u hdfs hadoop fs -mkdir /tmp
sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
sudo -u hdfs hadoop fs -mkdir /tmp/hadoop-yarn/staging
sudo -u hdfs hadoop fs -chmod -R 1777/tmp/hadoop-yarn/staging
sudo -u hdfs hadoop fs -mkdir/tmp/hadoop-yarn/staging/history/done_intermediate
sudo -u hdfs hadoop fs -chmod -R 1777/tmp/hadoop-yarn/staging/history/done_intermediate
sudo -u hdfs hadoop fs -chown -R mapred:mapred/tmp/hadoop-yarn/staging
sudo -u hdfs hadoop fs -mkdir /var/log/hadoop-yarn
sudo -u hdfs hadoop fs -chown yarn:mapred/var/log/hadoop-yarn
sudo -u hdfs hadoop fs -ls -R /
sudo service hadoop-yarn-resourcemanager start
sudo service hadoop-yarn-nodemanager start
sudo service hadoop-mapreduce-historyserver start
sudo -u hdfs hadoop fs -mkdir /usr/$USER
sudo -u hdfs hadoop fs -chown $USER /usr/$USER
sudo -u hdfs hadoop fs -mkdir /usr/xjp sudo -u hdfshadoop fs -chown xjp /usr/xjp
sudo -u hdfs hadoop fs -mkdir /usr/xjp/input
sudo -u hdfs hadoop fs -put /etc/hadoop/conf/*.xml/usr/xjp/input
sudo -u hdfs hadoop fs -ls /usr/xjp/input
sudo -u hdfs hadoop exportHADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
sudo -u hdfs hadoop jar/usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep /usr/xjp/input/usr/xjp/output1 'dfs[a-z.]+'
sudo -u hdfs hadoop fs -ls
sudo -u hdfs hadoop fs -put word.txt /usr/xjp
sudo -u hdfs hadoop jar example.jar /usr/xjp/word.txt/usr/xjp/output1
jps[查询hadoop启动的进程]。
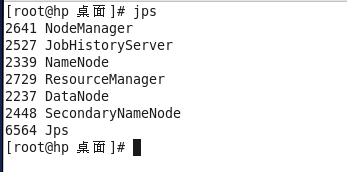
五、常见的错误:
[re-format question:Hadoop datanode is dead and pid fileexists]
java.io.IOException: Incompatible clusterIDs in/var/lib/hadoop-hdfs/cache/hdfs/dfs/data: namenode clusterID =CID-86e39214-94c8-4742-9f3e-37ddc43a0c53; datanode clusterID =CID-f77249c0-4c71-437c-8feb-bf401c42ee11
rm/var/lib/hadoop-hdfs/cache/hdfs/dfs/data -rf
安装虚拟机上 可以备份部署伪分布之前的系统状态,以便安装不成功之后,可以一键恢复再一次部署伪分布!
参考书:CDH4-Quick-Start.pdf















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









