






大家好,小编来为大家解答以下问题,python登录网站自动下载文件,python从网站下载文件,现在让我们一起来看看吧!
Source code download: 本文相关源码
获取请求头
手动获取:
点击右键,选择检查,再选择network,刷新一下(ctrl+r),随机选其中一个内容,将 User-Agent 后的内容复制出来就行:
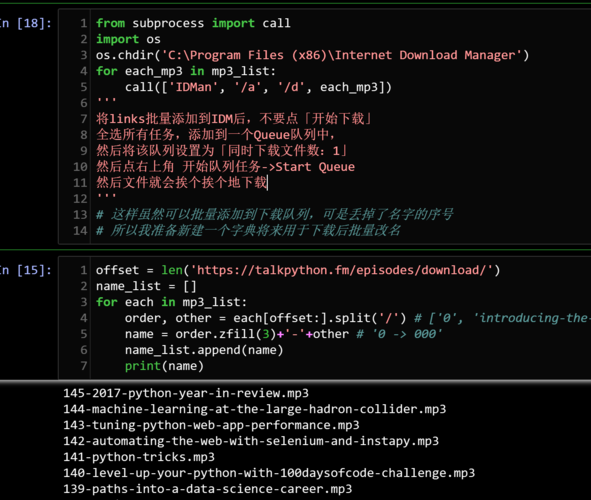
import urllib.request # url request
import re # regular expression
import os # dirs
import time
'''
url 下载网址
pattern 正则化的匹配关键词
Directory 下载目录
'''
def BatchDownload(url, pattern, Directory):
# 拉动请求,模拟成浏览器去访问网站->跳过反爬虫机制
# 在这里,必须使用元组或列表的方式定制请求头。
headers = {'User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
opener = urllib.request.build_opener() #自定义opener,使用build_opener()修改报头
opener.addheaders = [headers] #添加报头
content = opener.open(url).read().decode('utf8') # 获取网页内容
raw_hrefs = re.findall(pattern, content, re.IGNORECASE) # 构造正则表达式,从content中匹配关键词pattern
hset = set(raw_hrefs) # set函数消除重复元素
"""
urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None)
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调python自动化运维工资。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
"""
"""
关于urllib.request.Request()
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
url:url 地址。
data:发送到服务器的其他数据对象,post请求时使用,默认为 None。
headers:HTTP 请求的头部信息,字典格式。(重点要知道UA,cookie,Referer)
origin_req_host:请求的主机地址,IP 或域名。
unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是False。。
method:请求方法, 如 GET、POST、DELETE、PUT等
"""
# 下载链接
for href in hset:
# 之所以if else 是为了区别只有一个链接的特别情况
if (len(hset) > 1):
link = url + href[0]
filename = os.path.join(Directory, href[0])
print("正在下载", filename)
urllib.request.urlretrieve(link, filename)
print("成功下载!")
elif(len(hset) == 1):
link = url + href
filename = os.path.join(Directory, href)
print("正在下载", filename)
urllib.request.urlretrieve(link, filename)
print("成功下载!")
# 无sleep间隔,网站认定这种行为是攻击,反反爬虫
time.sleep(1)
BatchDownload('http://download.alleninstitute.org/informatics-archive/current-release/mouse_ccf/annotation/ccf_2017/structure_masks/structure_masks_10/',
'(structure_(\d+).nrrd)',
r'C:\Users\戚世兴\Desktop\Request_Module')
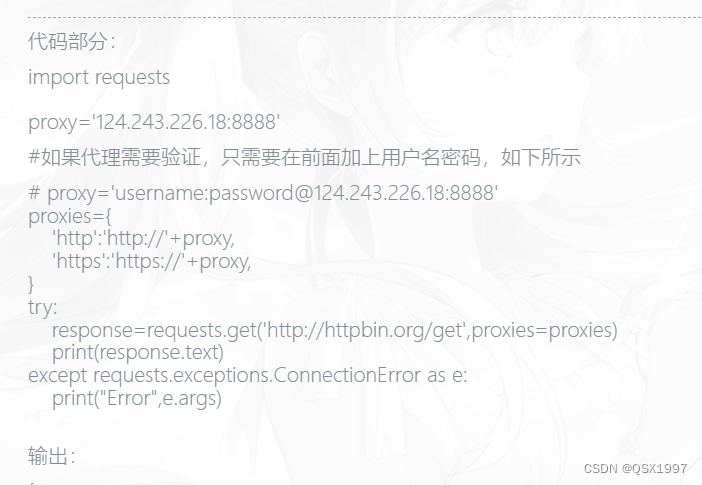
import requests
def BatchDownload(url, pattern, Directory):
#可在代理前面加上账号&密码
#proxies='username:password@127.0.0.1:9743'
proxies = {"http": "http://127.0.0.1:8080", "https": "http://127.0.0.1:8080"}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Cookie': 'JSESSIONID=B851AE4A99FB9222C81FE446688D4CBC; fxbdLocal=zh; islogin=true; username=F1243792; sign=sw0fLXElJRVJd2fmpL04UA==; zh_choose=n'
}
response = requests.request("GET", url, headers=headers,verify=False)
print(response.text)
print(requests.request("GET", "https://iedu.foxconn.com/public/user/userInfo",proxies=proxies, headers=headers,verify=False).text)
BatchDownload('https://iedu.foxconn.com/public/user/studyTask?',
'(structure_(\d+).nrrd)',
r'C:\Users\戚世兴\Desktop\Request_Module')
使用账号密码登录
def dologin(homepage_URL:str,username:str,password:str):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
session = requests.Session()
# 请求1:请求登录页面
session.auth = HttpNtlmAuth(username, password, str(session))
login_url = 'http://sfcweb.idpbg.efoxconn.com/LoginBak/Login.aspx'
try:
session.post(login_url)
except Exception as e:
print(e)
response = session.get(login_url)
if response.status_code == 407:
print("请关闭代理")
raise Exception(u"SFC Network Connected, Network Port Configuration Error")
# 解析1:解析登录后的页面
pyquery_obj = PyQuery(response.content)
data = {
"__VIEWSTATE": pyquery_obj.find('[name="__VIEWSTATE"]').val(),
'__VIEWSTATEGENERATOR': pyquery_obj.find("[name='__VIEWSTATEGENERATOR']").val(),
'btn_Login.x': random.randint(5, 100),
'btn_Login.y': random.randint(4, 40)
}
response = session.post(login_url, data=data)
# 登陆成功,爬取数据
data_query = {
"__EVENTTARGET": "btnQuery",
'__EVENTARGUMENT': "",
'__VIEWSTATE': "",
"ph_radio" : "AP",
"ctl05$ddlProduct" : "Spyder",
"ctl04$txb_WO" : "C07GV7000A900003QY",
}
try:
respone = session.get(url=homepage_URL, data=data_query, headers=headers, timeout=600)
if (respone.status_code == 200):
pyquery_obj = PyQuery(respone.content)
data_query["__VIEWSTATE"] = pyquery_obj.find('[name="__VIEWSTATE"]').val()
respone = session.post(url=homepage_URL, data=data_query, headers=headers, timeout=600)
print(respone.text)
except Exception as e:
print(e)
删除&移动文件
import os.path
import zipfile
import shutil
zip_file = zipfile.ZipFile(r'C:\Users\戚世兴\Desktop\新建文件夹.zip')
f_content = zip_file.namelist()
print(f_content)
f_size = zip_file.getinfo(r"新建文件夹/S3.xlsx").file_size
print(f_size)
zip_file.extractall(r"C:\Users\戚世兴\Desktop\11111")
zip_file.close()
size=0
for root, dirs, files in os.walk(r"C:\Users\戚世兴\Desktop\11111"):
for file in files:
if(os.path.isfile(root+"\\"+file)):
size+=os.path.getsize(root+"\\"+file)
# print(root+"\\"+file)
# os.remove(root+"\\"+file)
if(not os.path.exists(r"C:\Users\戚世兴\Desktop\11111\\"+file)):
shutil.move(root+"\\"+file,r"C:\Users\戚世兴\Desktop\11111")
print(size)
tell application "System Events"
try
tell window 1 of process "loginwindow"
repeat until not (value of static text 4 is equal to "")
set value of static text 4 to "this is a test"
delay 0.5
end repeat
end tell
end try
end tell
myPythonVariable = 10
cmd ="""
osa -e '
tell application"System Events"
set activeApp to name of first application process whose frontmost is true
if"MyApp" is in activeApp then
set stepCount to {0}
repeat with i from 1 to stepCount
-- do something
end repeat
end if
end tell
'
""".format(myPythonVariable)
打开对应的出错log文件,看到Could not create unix socket lock file的出错信息。这个socke文件从信息上看,是在tmp目录创建的,之前把这个目录的权限修改了,应该问题就是出在这里了。
在命令行窗口上,打开my.cnf配置文件,这是mysql的配置文件
sudo vim /etc/my.cnf
打开后,在文件后面添加一句: socket=/usr/local/mysql/mysql.sock
就是把sock文件创建到mysql的目录下,不再放到tmp目录里。
保存后就可以正常启动mysql服务了。
socket=/usr/local/mysql/mysql.sock















 4262
4262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









