






 本文围绕分布式SQL计算展开,介绍了Apache Hive这一工具,它能将SQL语句翻译成MapReduce程序。还阐述了Hive的Driver驱动程序、核心架构、元数据存储模式等。此外,对比了数仓和数据库的区别,介绍了数仓分层架构,以及Hive的数据库操作、表类型等信息技术相关内容。
本文围绕分布式SQL计算展开,介绍了Apache Hive这一工具,它能将SQL语句翻译成MapReduce程序。还阐述了Hive的Driver驱动程序、核心架构、元数据存储模式等。此外,对比了数仓和数据库的区别,介绍了数仓分层架构,以及Hive的数据库操作、表类型等信息技术相关内容。
分布式SQL的计算
对数据进行统计分析,SQL的是目前最为方便的编程工具。大数据体系中充斥着非常多的统计分析场景所以,用SQL的去处理数据,在大数据中也是有极大的需求的。Apache Hive是一款分布式SQL的计算的工具,其主要功能是:将SQL的语句翻译成MapReduce的程序运行。
分布式SQL的计算
以分布式的形式,执行SQL的语句,进行数据统计分析。
ApacheHive的用处:将SQL的语句翻译成MapReduce的程序,从而提供用户分布式SQL的计算的能力。
•传统MapReduce的开发:写先生代码->得到结果
•使用Hive开发:写SQL->得到结果
•底层都是先生在运行,但是使用层面上更加简单了。
Driver驱动程序
Driver:包括语法解析器、计划编译器、优化器、执行器
作用:完成HQL公司查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS的中,并在随后有MapReduce的调用执行。
Hive的核心架构
元数据管理:称之为元存储服务,推荐远程模式
SQL的解析器(Driver驱动程序),完成SQL的解析、执行优化、代码提交等功能
用户接口:提供用户和蜂房交互的功能
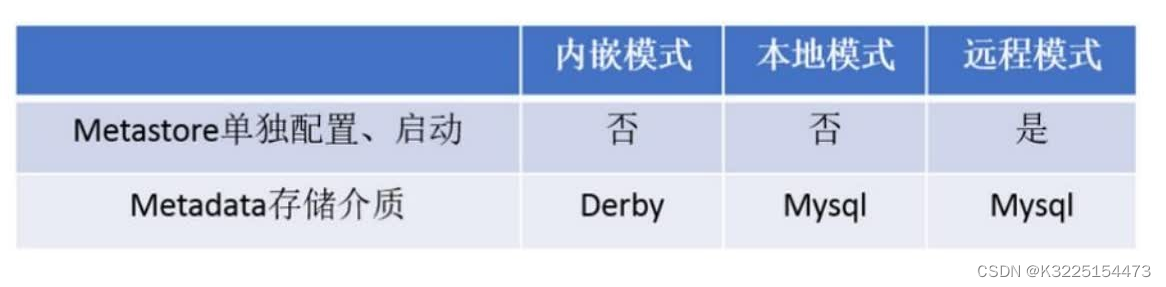
Hive元数据存储的三种模式:内嵌模式,本地模式,远程模式。
三种模式的区别
Hive体验
1.启动元存储服务
2.执行bin/hive,进入到蜂巢外壳环境中,可以直接执行SQL的语句
3.创建表
4.插入数据
5.查询数据
6.Hive的数据存储
7.验证SQL的语句启动的MapReduce的程序
数仓和数据库的区别
数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储业务数据,数据仓库存储的一般是历史数据。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的用户表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。
数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。数据仓库架构可分为三层——源数据层、数据仓库层、数据应用层
数仓的分层架构
源数据层(消耗臭氧层物质):此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW公司):也称为细节层,DW公司层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(大或应用程序):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。
数据库操作
1.使用location关键字,可以指定数据库在HDFS的的存储路径:
create database myhive2 location '/myhive2';2.创建库的语法为:
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position];
3.删除库的语法为:
DROP DATABASE db_name [CASCADE];
3. 数据库和HDFS的关系:
• Hive的库在HDFS上就是一个以.db结尾的目录
• 默认存储在:/user/hive/warehouse内
• 可以通过LOCATION关键字在创建的时候指定存储目录
Hive表的类型
内部表,外部表
二者区别:
删除内部表:直接删除元数据(metadata)及存储数据。
删除外部表:仅仅是删除元数据(表的信息),不会删除数据本身。
创建内部表语法:
create table [if not exists] 内部表名(
字段名 字段类型 , ...
)...;创建外部表:
create external table [if not exists] 内部表名(
字段名 字段类型 , ...
)...;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









