






 本文介绍了如何在Hadoop平台上搭建和管理单机及集群模式,包括启动虚拟机、配置连接、一键启动/关闭、HDFS操作、Hive数据仓库工具以及与Hadoop生态组件的关系。
本文介绍了如何在Hadoop平台上搭建和管理单机及集群模式,包括启动虚拟机、配置连接、一键启动/关闭、HDFS操作、Hive数据仓库工具以及与Hadoop生态组件的关系。
Hadoop集群搭建
大数据集群方案-单机模式
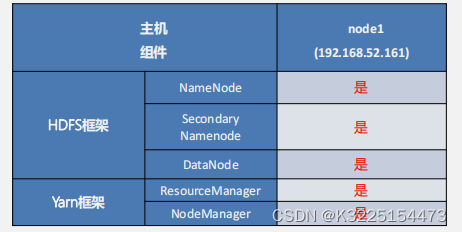
大数据集群方案-集群模式
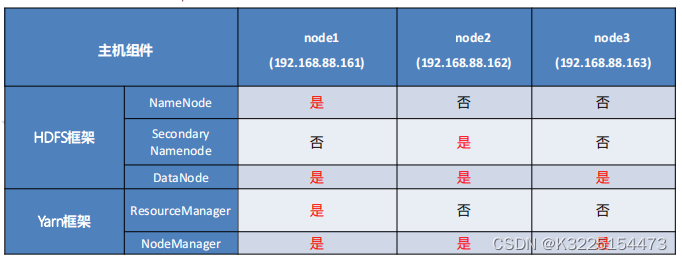
Hadoop启动和关闭-单节点模式
1
、启动虚拟机
2
、使用
Termius
连接虚拟机
3
、集群一键启动和关闭
•
一键启动大数据环境
/onekey/my-start-all.sh
•
一键关闭大数据环境
/onekey/my-stop-all.sh
Hadoop页面访问-集群模式
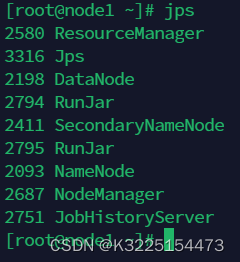
1.查看启动进程-jps
2.查看HDFS页面
一旦Hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
查看NameNode页面地址:http://192.168.52.161:50070
3.查看YARN页面
http://192.168.52.161:8088
4.
查看已经finished的mapreduce运行日志
http://192.168.52.161:19888
HDFS的概述
HDFS
(
Hadoop Distributed File System
)是
Apache Hadoop
项目的一个子项目
. Hadoop
非常适于存储大型
数据
(
比如
TB
和
PB),
其就是使用
HDFS
作为存储系统
. HDFS
使用多台计算机存储文件
,
并且提供统一的访问接口
,
像是访问一个普通文件系统一样使用分布式文件系统
.
HDFS的特点
HDFS
文件系统可存储超大文件,时效性稍差。
HDFS
具有硬件故障检测和自动快速恢复功能。
HDFS
为数据存储提供很强的扩展能力。
HDFS
存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
HDFS
可在普通廉价的机器上运行
HDFS的架构
HDFS
采用
Master/Slave
架构
一个
HDFS
集群有两个重要的角色,分别是
Namenode和Datanode
。
HDFS
的四个基本组件
:
HDFS Client、NameNode、DataNode和Secondary NameNode。
Shell命令介绍
可以执行
hdfs
相关的
shell
命令对
hdfs
文件系统进行操作,比如文件的创建、删除、修改文
件权限等。
ls命令
显示文件列表
mkdir命令
创建目录。使用
-p
参数可以递归创建目录
mv命令
删除参数指定的文件和目录,参数可以有多个,删除目录需要加
-r
参数
cp命令
将文件拷贝到目标路径中
cat命令
将参数所指示的文件内容输出到控制台
put命令
将单个的源文件或者多个源文件
srcs
从本地文件系统上传到目标文件系统中。
get命令
将
HDFS
文件拷贝到本地文件系统。
Hive概述
hive是基于Hadoop
的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce
任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
Hive与Hadoop生态系统中其他组件的关系
Hive依赖于HDFS存储数据,依赖MR处理数据;Pig可作为Hive的替代工具,是一种数据流语言和运行环境,适合用于在Hadoop平台上查询半结构化数据集,用于与ETL过程的一部分,即将外部数据装载到Hadoop集群中,转换为用户需要的数据格式;HBase是一个面向列的、分布式可伸缩的数据库,可提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,Hive的初衷是为减少复杂MR应用程序的编写工作,HBase则是为了实现对数据的实时访问。















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









