






前言
影刀cto说过这么一句话:不迷信AI,也不忽视AI,我们要打造以AI驱动的RPA,AI对当前社会的影响真的不亚于一场战争的爆发
RPA(机器人流程自动化)作为一种已被广泛应用的技术,能基于预设规则自动执行重复性任务,有效提升效率、降低成本,但其局限性在于缺乏智能决策和处理复杂任务的能力。
打造以 AI 驱动的 RPA,是将两者优势融合,实现 “1 + 1> 2” 效果的明智之举。从效率提升角度看,RPA 能够不知疲倦地处理大量重复、规律性的工作流程,像数据录入、文件整理等基础任务。而 AI 的加入,能让 RPA 具备智能判断和灵活应变能力。例如在财务报销流程中,传统 RPA 可完成表单填写、数据核对等操作,但面对复杂报销场景,如特殊费用说明、模糊票据识别时往往力不从心。
从技术发展趋势来看,AI 与 RPA 的融合是自动化技术迈向更高阶段的必然路径。
使用RPA进行ppt的生成操作
在我们的日常生活中,ppt的制作时长会出现,并且我觉得制作一个ppt的步骤十分繁琐,所以我就思考是否能让rpa帮助我直接生成我想要的ppt呢?
RPA 可以自动化执行 PPT 生成过程中的重复性任务,如根据预设模板填充数据、插入图片、设置格式等。它能够以极快的速度完成这些操作,大大节省了人工制作 PPT 的时间,尤其是在处理大量类似 PPT 时,效率提升更为显著。
当需要生成大量 PPT 或对 PPT 生成的需求不断增加时,RPA 可以轻松应对,通过简单地调整配置或增加机器人数量,就能满足业务的增长需求,而无需大量增加人力成本。
我们直接从一大堆生成出来的ppt中选择自己喜欢的样式就行了,那么通过RPA实现ppt的生成确实对我们很有利,也适当的增加了工作摸鱼的时间
那么下面我们就介绍下如何进行这款ppt自动化机器人的生成吧
这里我们是通过一条魔法指令实现的
输入命令->“你读取我给你变量的信息,然后根据这个变量的信息进行读取需要生成的ppt的相关信息,然后 你进行生成,生成之前需要弹出一个弹窗,让我选择ppt的存储位置”
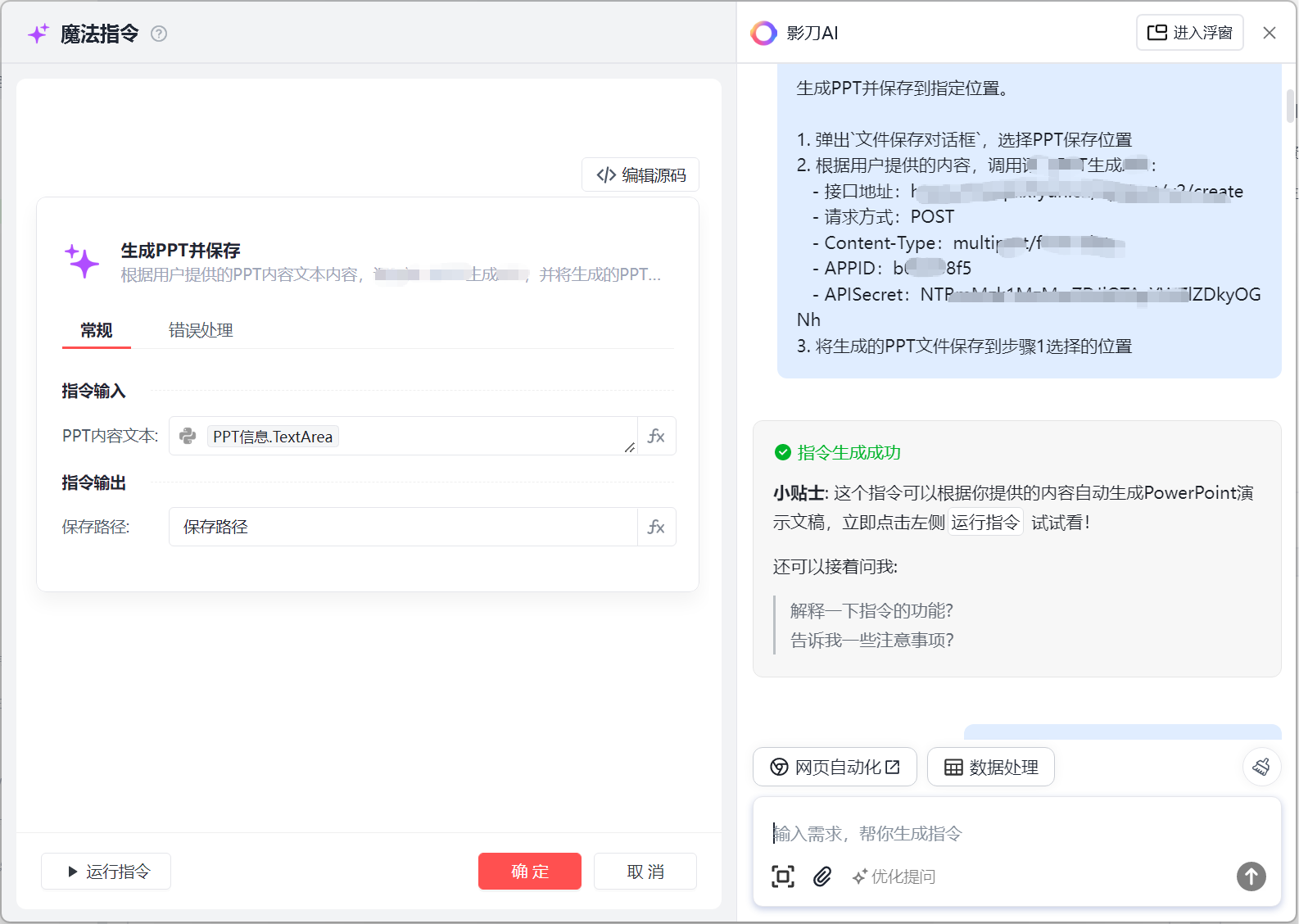
然后魔法指令就可以进行代码的生成
虽然经历了几次报错,但是我们直接将报错的信息发送给影刀ai,他就可以立马判断出错误的位置是哪里
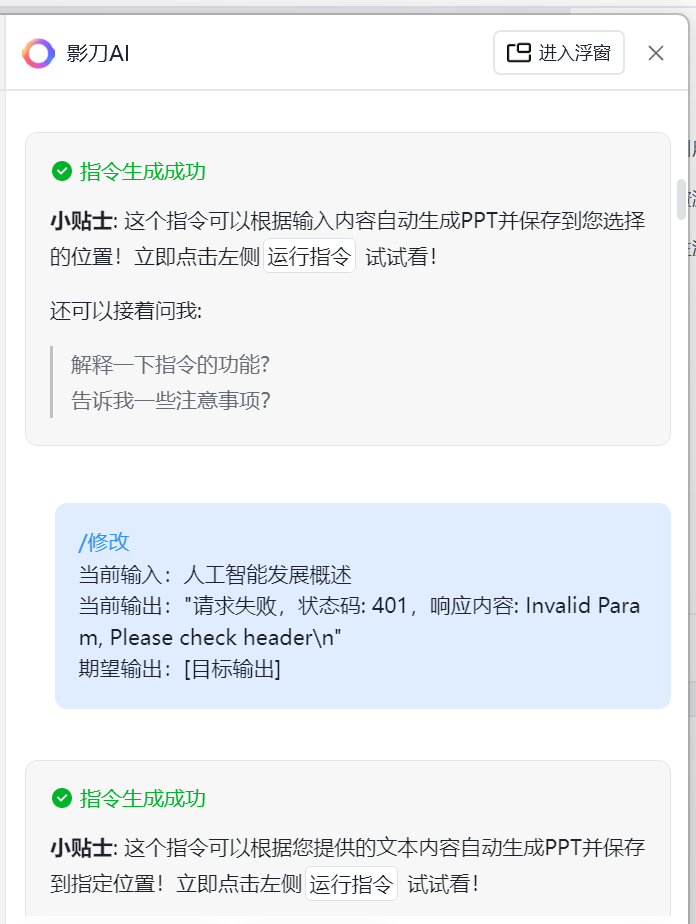
最后我们也是成功的生成出来了,我们可以进行一个测试操作
直接进行运行
这里我们随便输入一个ppt内容文本进行测试下
文本内容"人工智能发展概述"
可以看到左下角会有详细流程说明
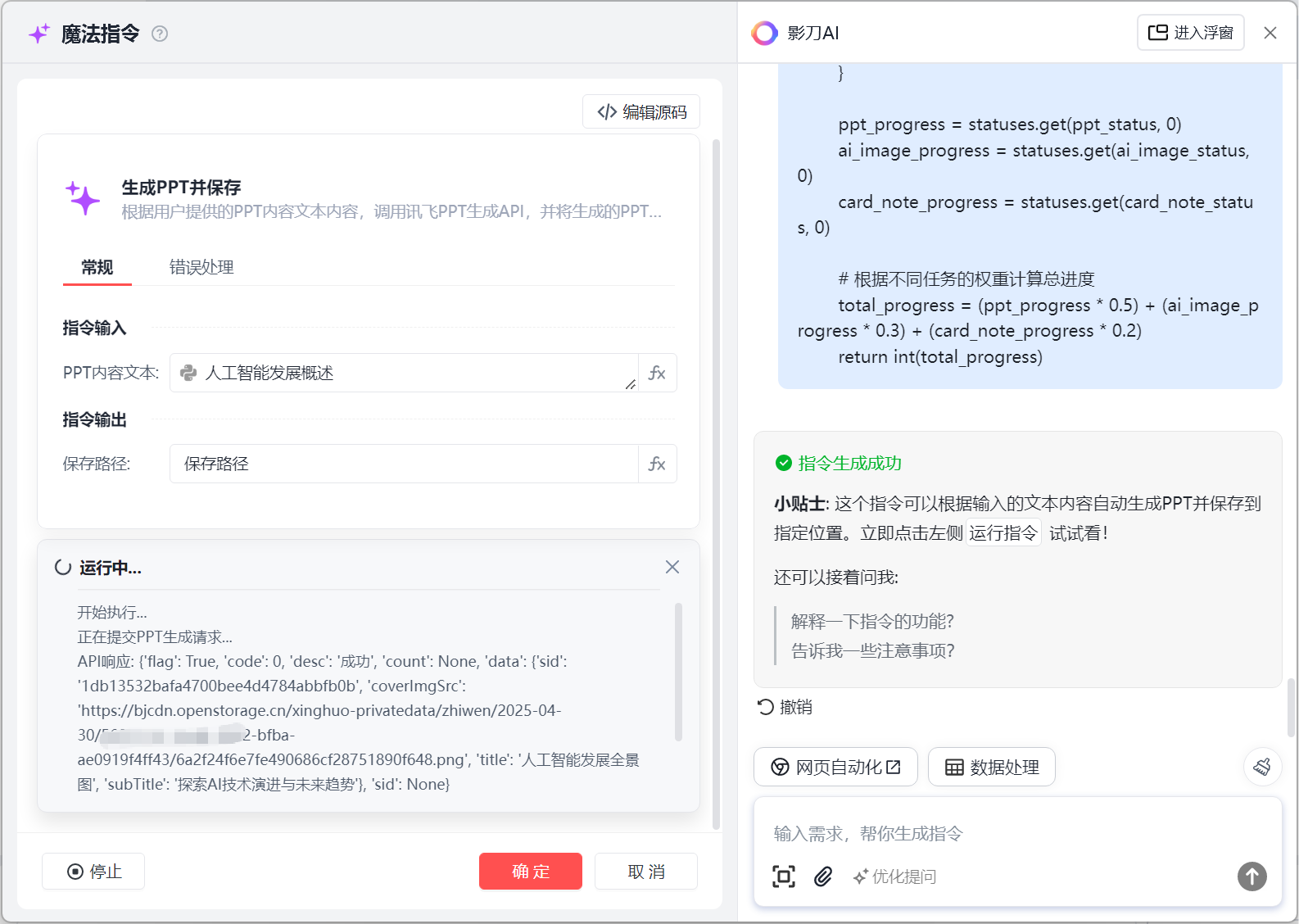
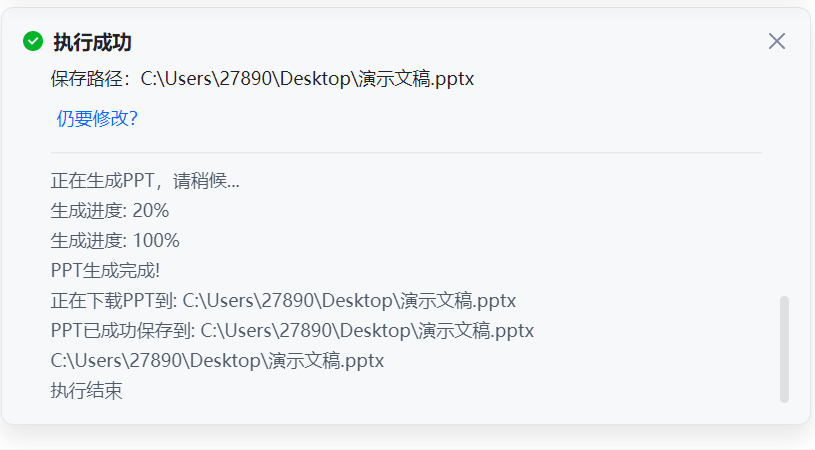
稍微等了30秒就生成好了,我们可以看下效果
ppt的基本内容都是没有缺少的,讲解的都是比较详细的
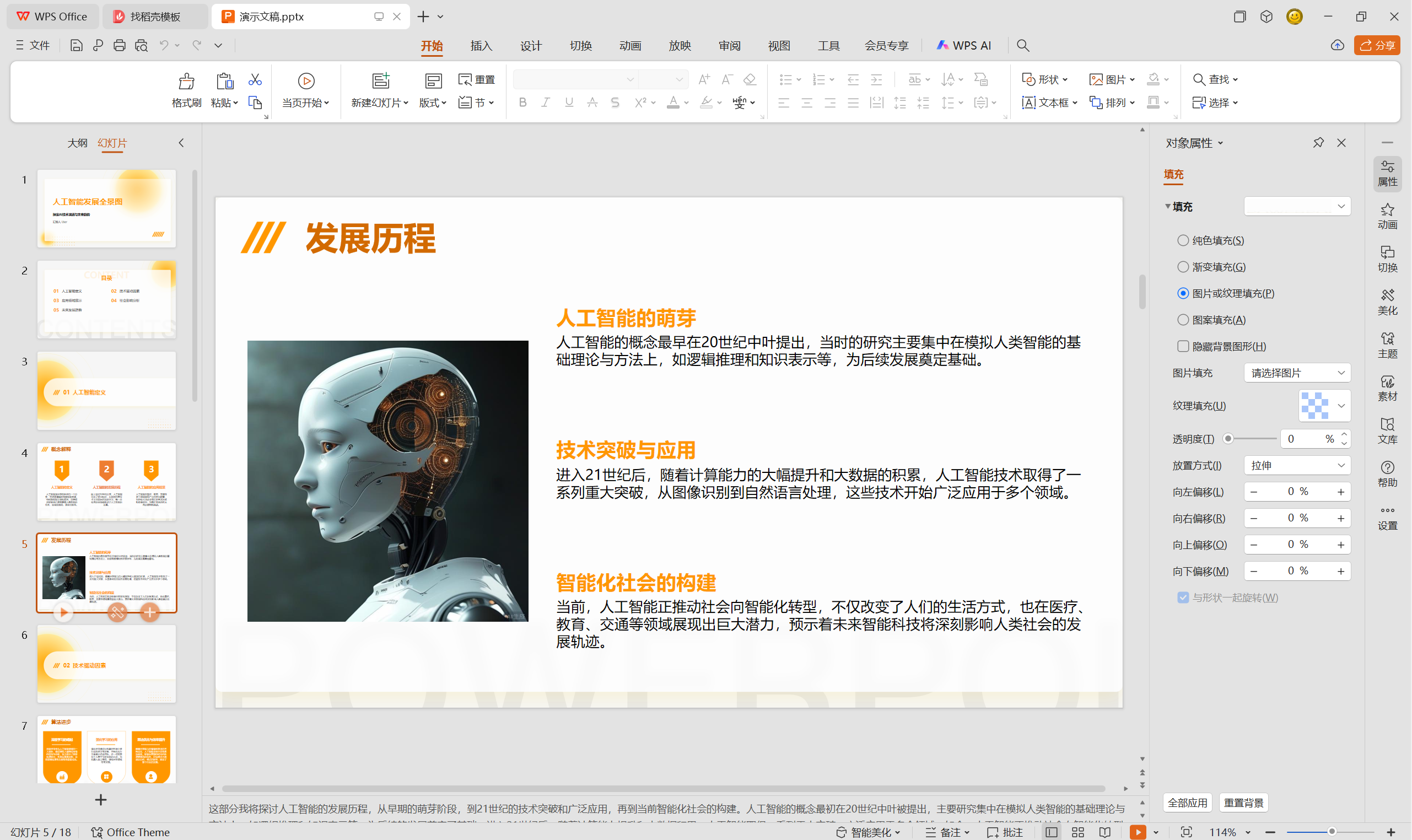
那么我们的核心魔法指令搞定了之后我们就进行外围指令的拼接
外围的话,为了美观整个流程的话,我们加上弹窗,提示我们需要将文件保存在哪个文件夹里面,以及加上消息通知:请输入你的文本信息
在开头加上一个自定义对话框设计器,为的是我们一运行程序,程序就可以进行让我们输入我们想要获取的ppt类型,就是让我们输入一段描述我们想生成ppt的描述就行了
我们这里选择文本域就行了
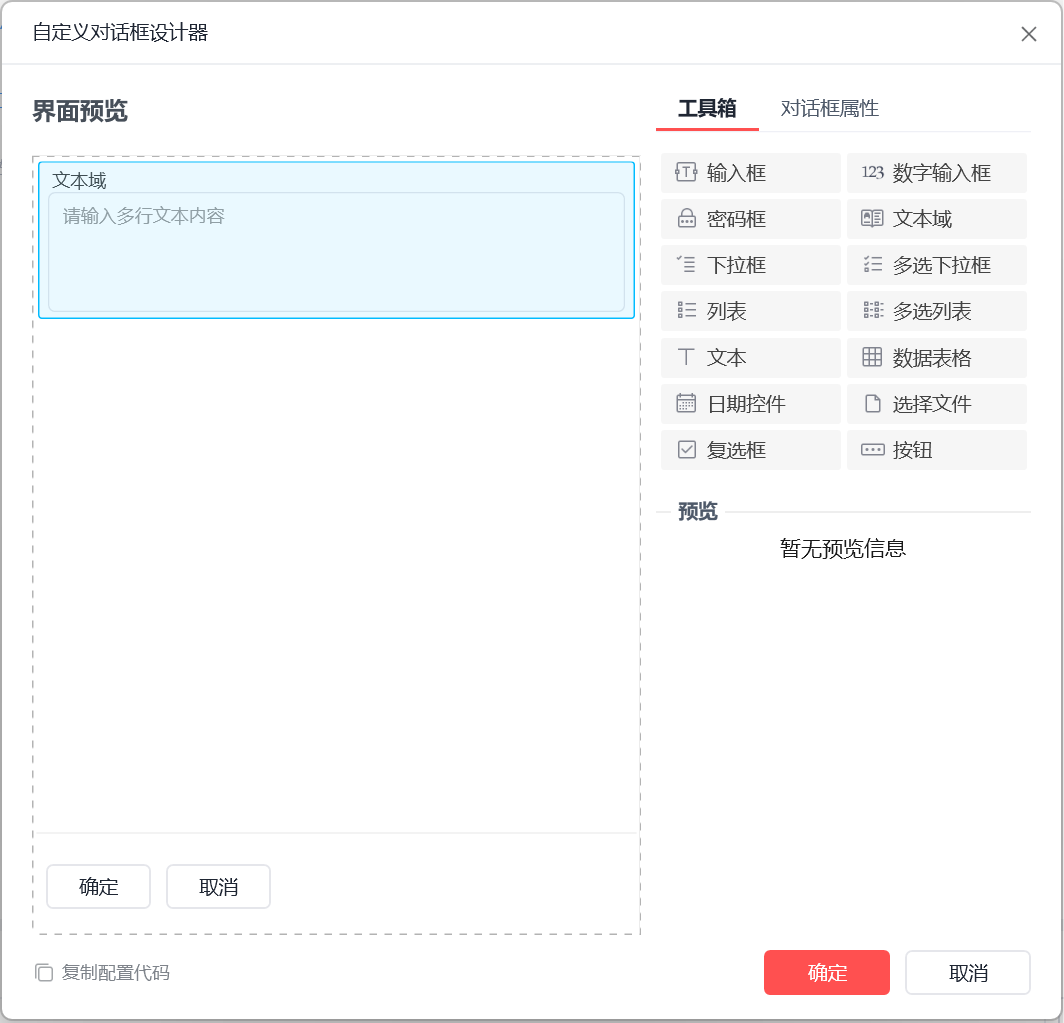
将获取到的信息保存在变量ppt文本内容里面就行了
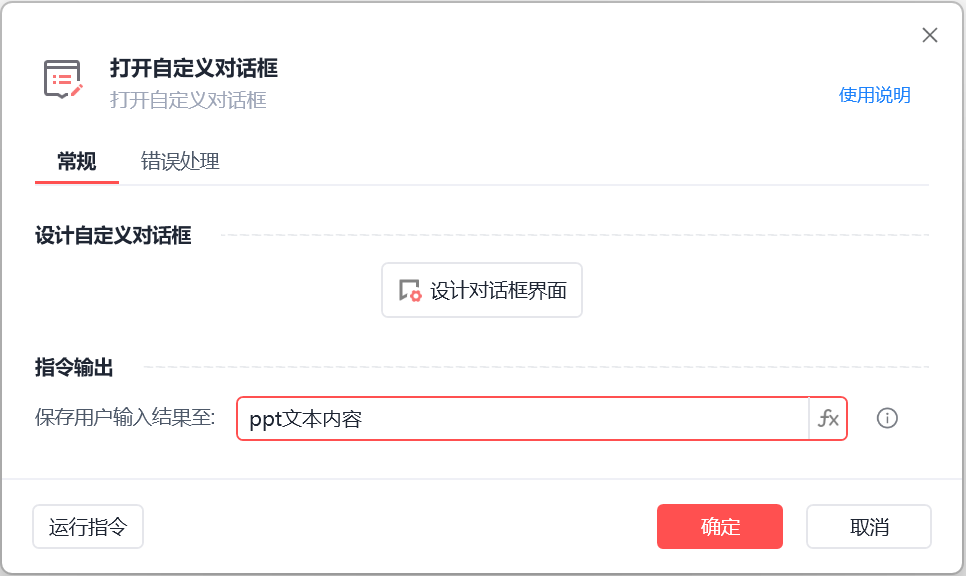
这个时候我们可以将魔法指令中的PPT内容文本改成刚刚设置的变量
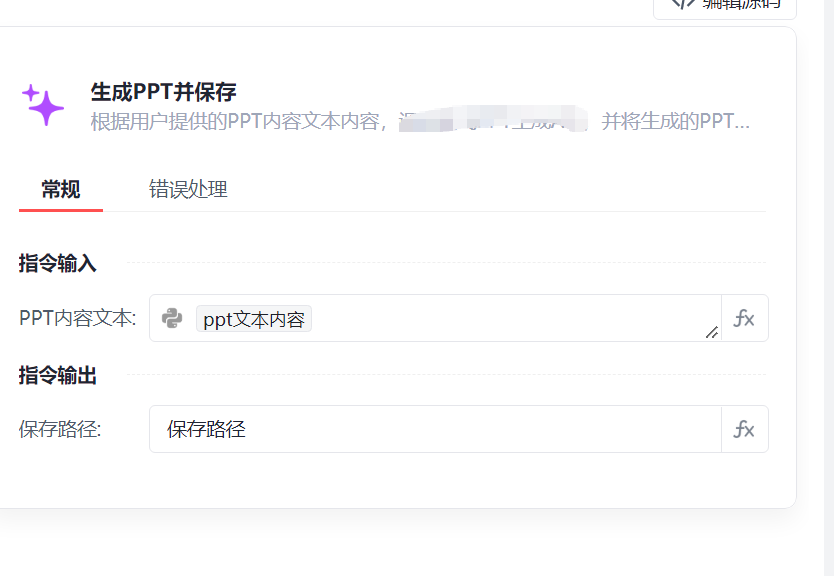
但是我们实际运行发现,并不能获取到我们输入信息
所以我们在外部调试下,估计是内容文本没有获取到我们将这两个都进行打印一下,看看谁是我们的输入的文本
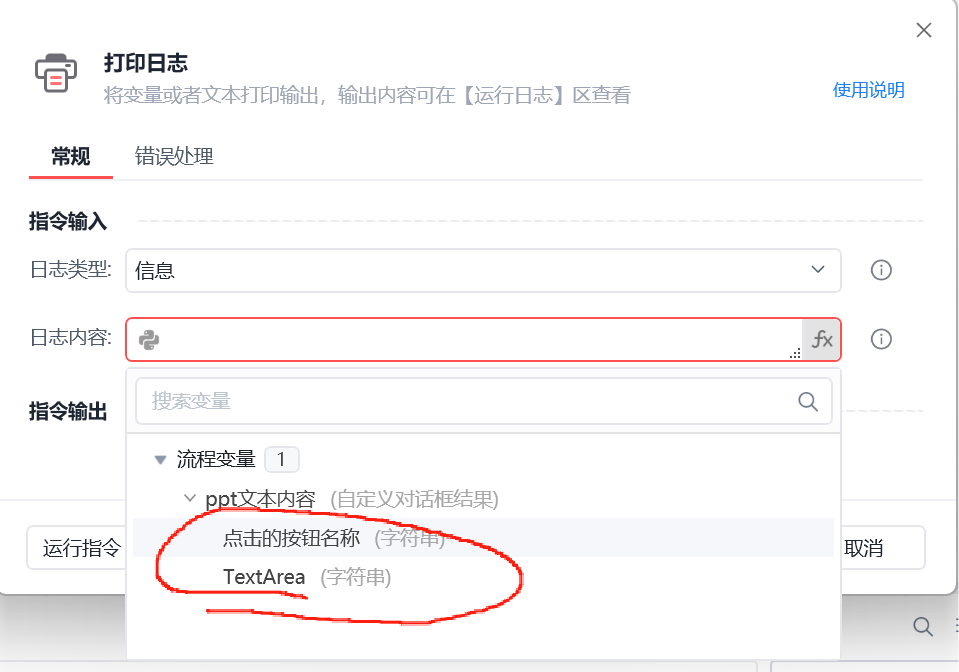
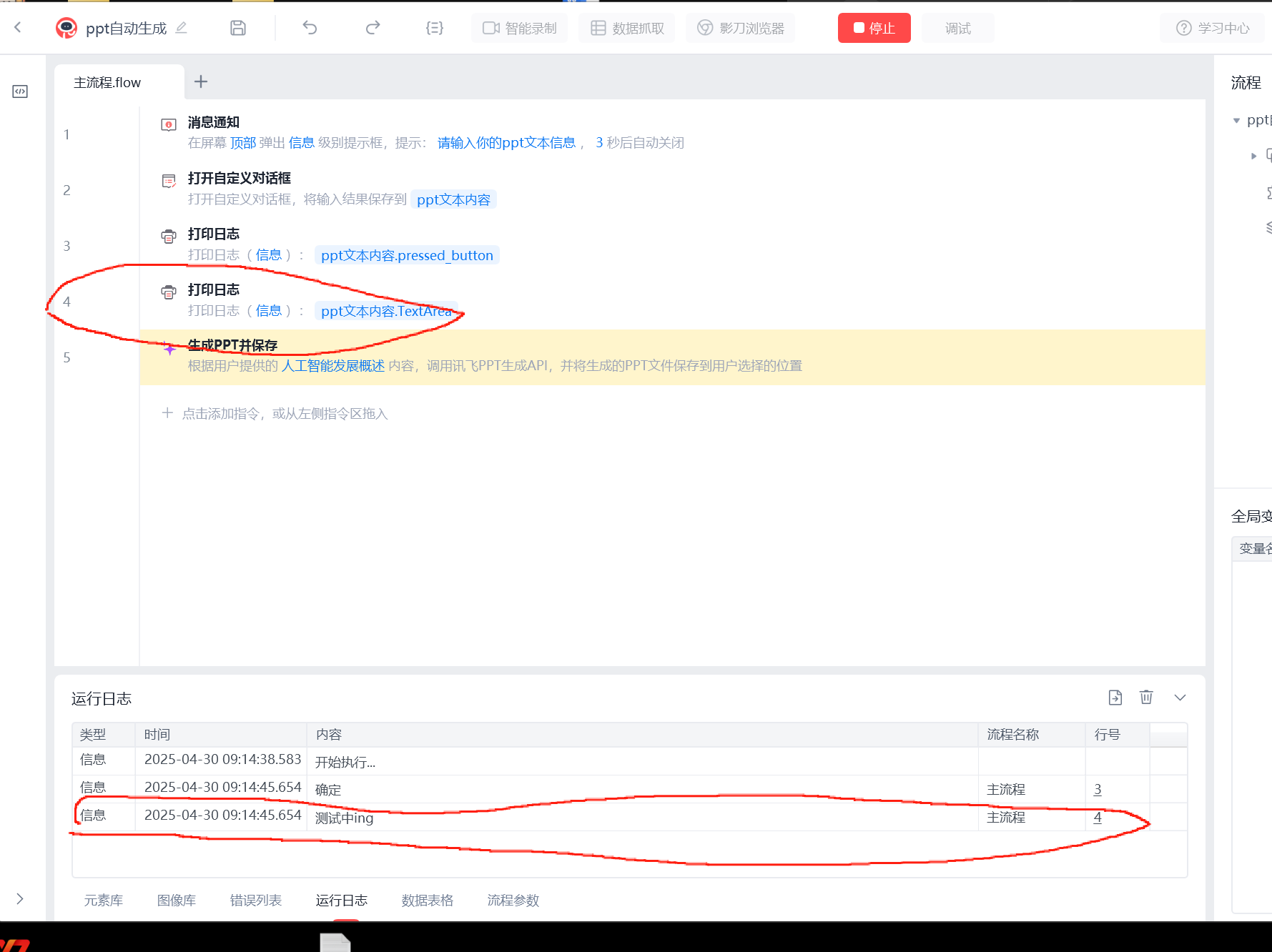
很明显可以看到是第四行输入的正确信息,那么我们就将这个变量输入进去
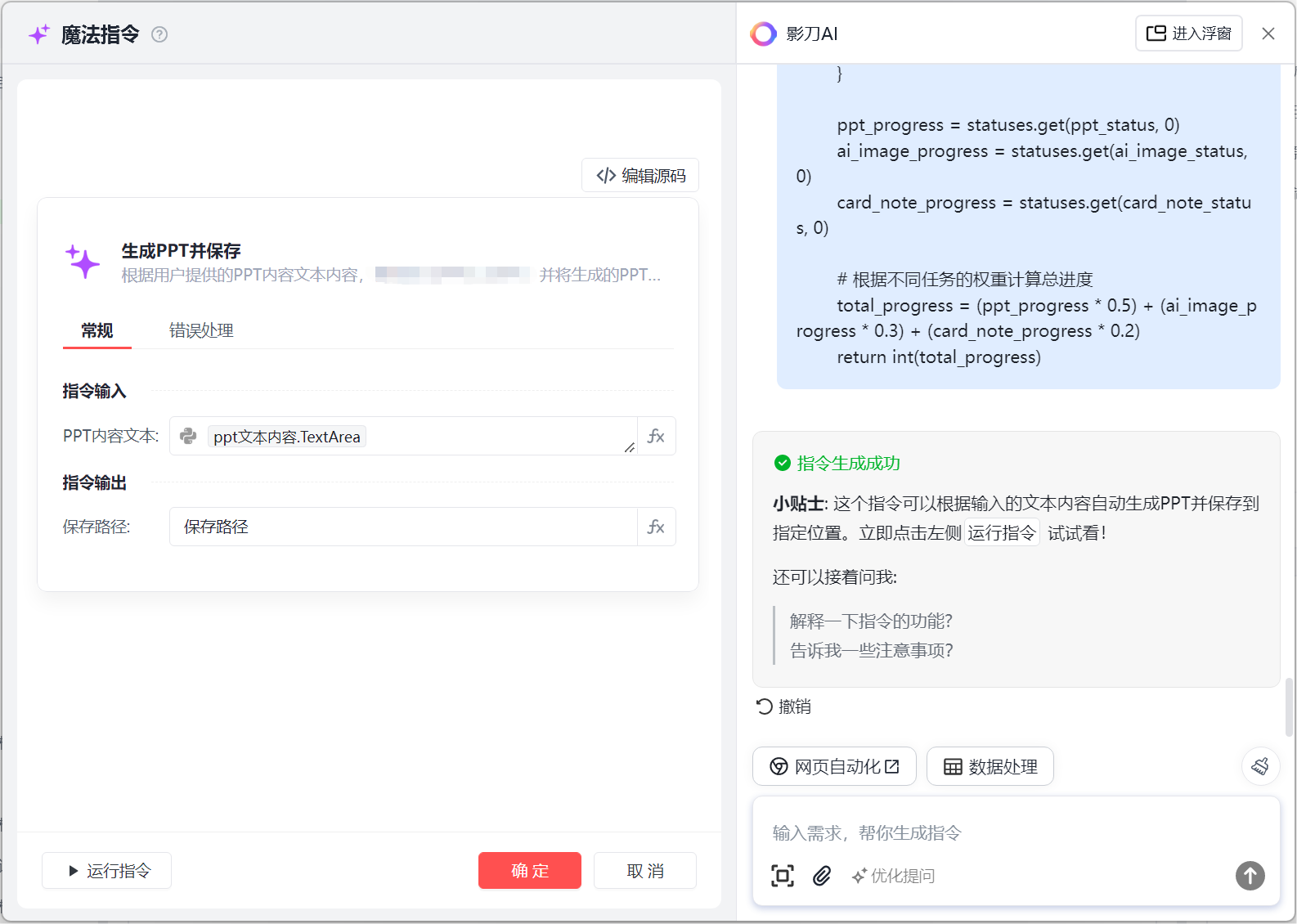
到这里我们的一系列的流程就搞定了
下面是整个流程的概括,大家可以参考下
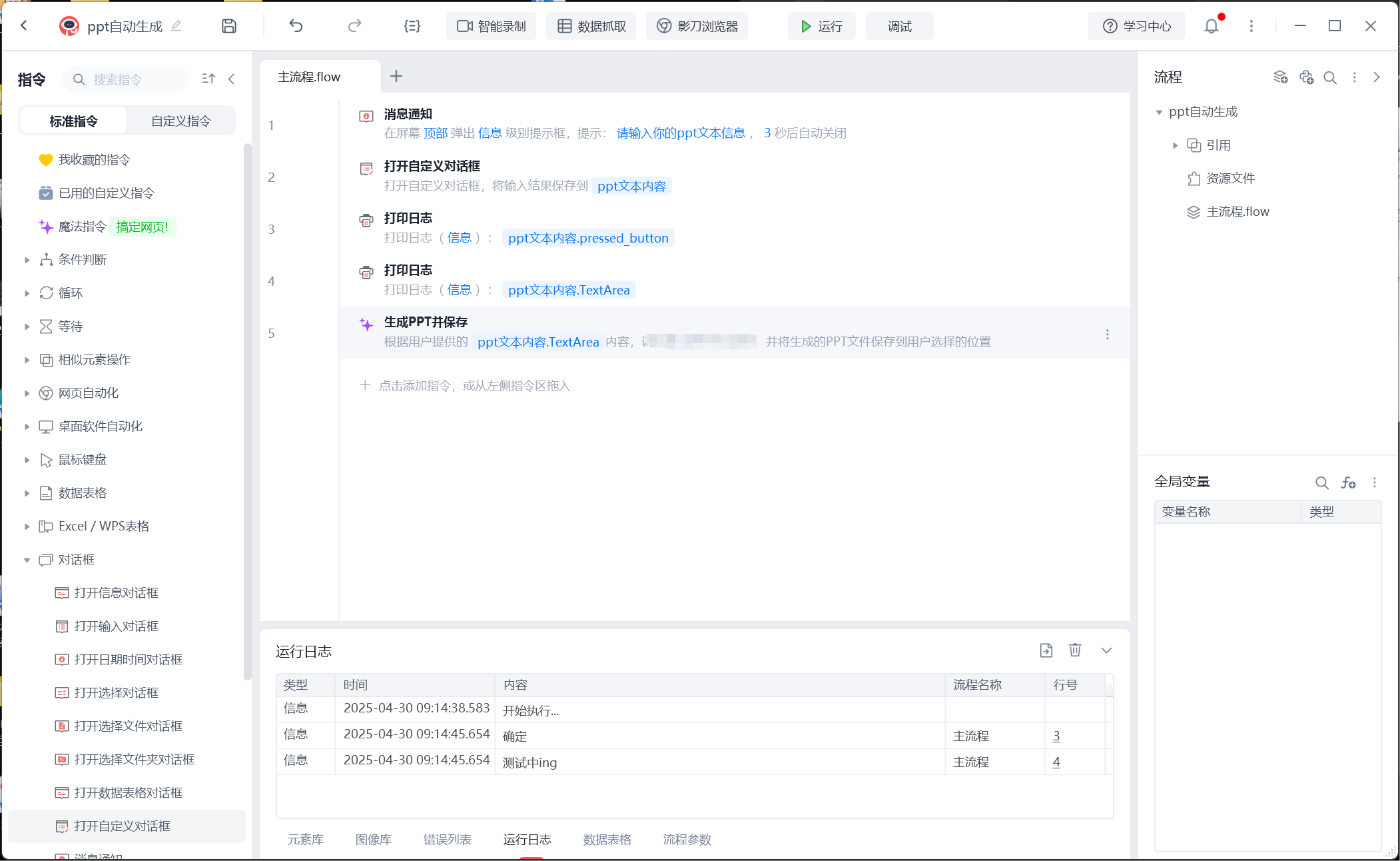
源码如下:
# 使用此指令前,请确保安装必要的Python库,例如使用以下命令安装:
# pip install requests requests-toolbelt
import requests
import tkinter as tk
from tkinter import filedialog
import os
import time
import base64
import hashlib
import hmac
import json
from requests_toolbelt.multipart.encoder import MultipartEncoder
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def generate_ppt(content):
"""
title: 生成PPT并保存
description: 根据用户提供的%content%内容,调用讯飞PPT生成API,并将生成的PPT文件保存到用户选择的位置。
inputs:
- content (str): PPT内容文本,eg: "人工智能发展概述"
outputs:
- save_path (str): 保存路径,eg: "C:/Users/Desktop/演示文稿.pptx"
"""
# 获取桌面路径作为默认保存位置
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
default_filename = "演示文稿.pptx"
default_save_path = os.path.join(desktop_path, default_filename)
# 1. 弹出文件保存对话框
root = tk.Tk()
root.withdraw() # 隐藏主窗口
save_path = filedialog.asksaveasfilename(
title="选择PPT保存位置",
filetypes=[("PowerPoint files", "*.pptx")],
defaultextension=".pptx",
initialdir=desktop_path,
initialfile=default_filename
)
# 如果用户取消选择,则使用默认路径
if not save_path:
save_path = default_save_path
# 2. 调用讯飞PPT生成API
app_id = "b0bd38f5"
api_secret = "XXXXXXXXXXXXXXXXXXXXXX"
template_id = "XXXXXXXXXXXXXXXXXXXXXxx" # 使用预定义的模板ID
try:
# 创建AIPPT辅助类对象
ppt_generator = _AIPPT(app_id, api_secret, content, template_id)
# 创建PPT生成任务并获取任务ID
task_id = ppt_generator.create_task()
if not task_id:
return "创建PPT任务失败,请检查网络连接和API凭据"
# 打印状态信息
print(f"PPT生成任务已创建,任务ID: {task_id}")
print("正在生成PPT,请稍候...")
# 获取PPT下载链接
ppt_url = ppt_generator.get_result(task_id)
if not ppt_url:
return "获取PPT下载链接失败"
# 下载PPT文件
print(f"正在下载PPT到: {save_path}")
response = requests.get(ppt_url)
# 保存PPT文件
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"PPT已成功保存到: {save_path}")
return save_path
except Exception as e:
error_msg = f"生成PPT过程中出错: {str(e)}"
print(error_msg)
return error_msg
# 辅助类:用于与讯飞PPT生成API交互
def _AIPPT(app_id, api_secret, text, template_id):
class AIPPT:
def __init__(self, app_id, api_secret, text, template_id):
self.APPid = app_id
self.APISecret = api_secret
self.text = text
self.header = {}
self.templateId = template_id
# 获取签名
def get_signature(self, ts):
try:
# 对app_id和时间戳进行MD5加密
auth = self.md5(self.APPid + str(ts))
# 使用HMAC-SHA1算法对加密后的字符串进行加密
return self.hmac_sha1_encrypt(auth, self.APISecret)
except Exception as e:
print(f"生成签名时出错: {e}")
return None
def hmac_sha1_encrypt(self, encrypt_text, encrypt_key):
# 使用HMAC-SHA1算法对文本进行加密,并将结果转换为Base64编码
return base64.b64encode(hmac.new(encrypt_key.encode('utf-8'), encrypt_text.encode('utf-8'), hashlib.sha1).digest()).decode('utf-8')
def md5(self, text):
# 对文本进行MD5加密,并返回加密后的十六进制字符串
return hashlib.md5(text.encode('utf-8')).hexdigest()
# 创建PPT生成任务
def create_task(self):
url = 'https://zwapi.xfyun.cn/api/ppt/v2/create'
timestamp = int(time.time())
signature = self.get_signature(timestamp)
# 准备multipart/form-data数据
form_data = MultipartEncoder(
fields={
"query": self.text,
"templateId": self.templateId,
"author": "User",
"isCardNote": str(True),
"search": str(False),
"isFigure": str(True),
"aiImage": "normal"
}
)
# 设置请求头
headers = {
"appId": self.APPid,
"timestamp": str(timestamp),
"signature": signature,
"Content-Type": form_data.content_type
}
self.header = headers
# 发送请求
print("正在提交PPT生成请求...")
response = requests.post(url=url, data=form_data, headers=headers)
# 检查请求是否成功
if response.status_code != 200:
print(f"API请求失败,状态码: {response.status_code}")
print(f"响应内容: {response.text}")
return None
# 解析响应
try:
resp = response.json()
print(f"API响应: {resp}")
if resp.get('code') == 0:
return resp['data']['sid']
else:
print(f"创建PPT任务失败: {resp.get('message', '未知错误')}")
return None
except json.JSONDecodeError:
print(f"API返回非JSON格式响应: {response.text[:200]}")
return None
# 轮询任务进度
def get_process(self, sid):
if sid is None:
return None
response = requests.get(
url=f"https://zwapi.xfyun.cn/api/ppt/v2/progress?sid={sid}",
headers=self.header
)
return response.text
# 获取PPT下载链接
def get_result(self, task_id):
if task_id is None:
return None
# 轮询任务进度
progress = 0
while True:
response = self.get_process(task_id)
if not response:
print("获取任务进度失败")
return None
resp = json.loads(response)
# 检查PPT生成状态
ppt_status = resp['data']['pptStatus']
ai_image_status = resp['data']['aiImageStatus']
card_note_status = resp['data']['cardNoteStatus']
# 计算总进度
current_progress = self._calculate_progress(ppt_status, ai_image_status, card_note_status)
if current_progress > progress:
progress = current_progress
print(f"生成进度: {progress}%")
# 检查是否所有任务都已完成
if ppt_status == 'done' and ai_image_status == 'done' and card_note_status == 'done':
ppt_url = resp['data']['pptUrl']
print("PPT生成完成!")
return ppt_url
else:
# 每3秒检查一次进度
time.sleep(3)
# 计算总进度百分比
def _calculate_progress(self, ppt_status, ai_image_status, card_note_status):
statuses = {
'waiting': 0,
'running': 50,
'done': 100
}
ppt_progress = statuses.get(ppt_status, 0)
ai_image_progress = statuses.get(ai_image_status, 0)
card_note_progress = statuses.get(card_note_status, 0)
# 根据不同任务的权重计算总进度
total_progress = (ppt_progress * 0.5) + (ai_image_progress * 0.3) + (card_note_progress * 0.2)
return int(total_progress)
return AIPPT(app_id, api_secret, text, template_id)
实验效果展示
运行程序输入ppt文本内容
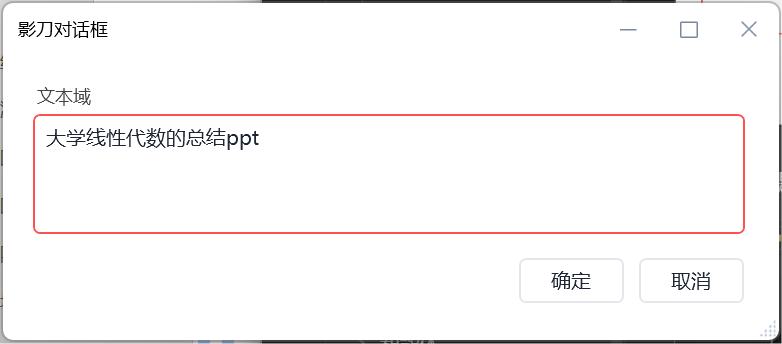
然后弹窗提示我们选择ppt保存位置,我们直接选择桌面就行了
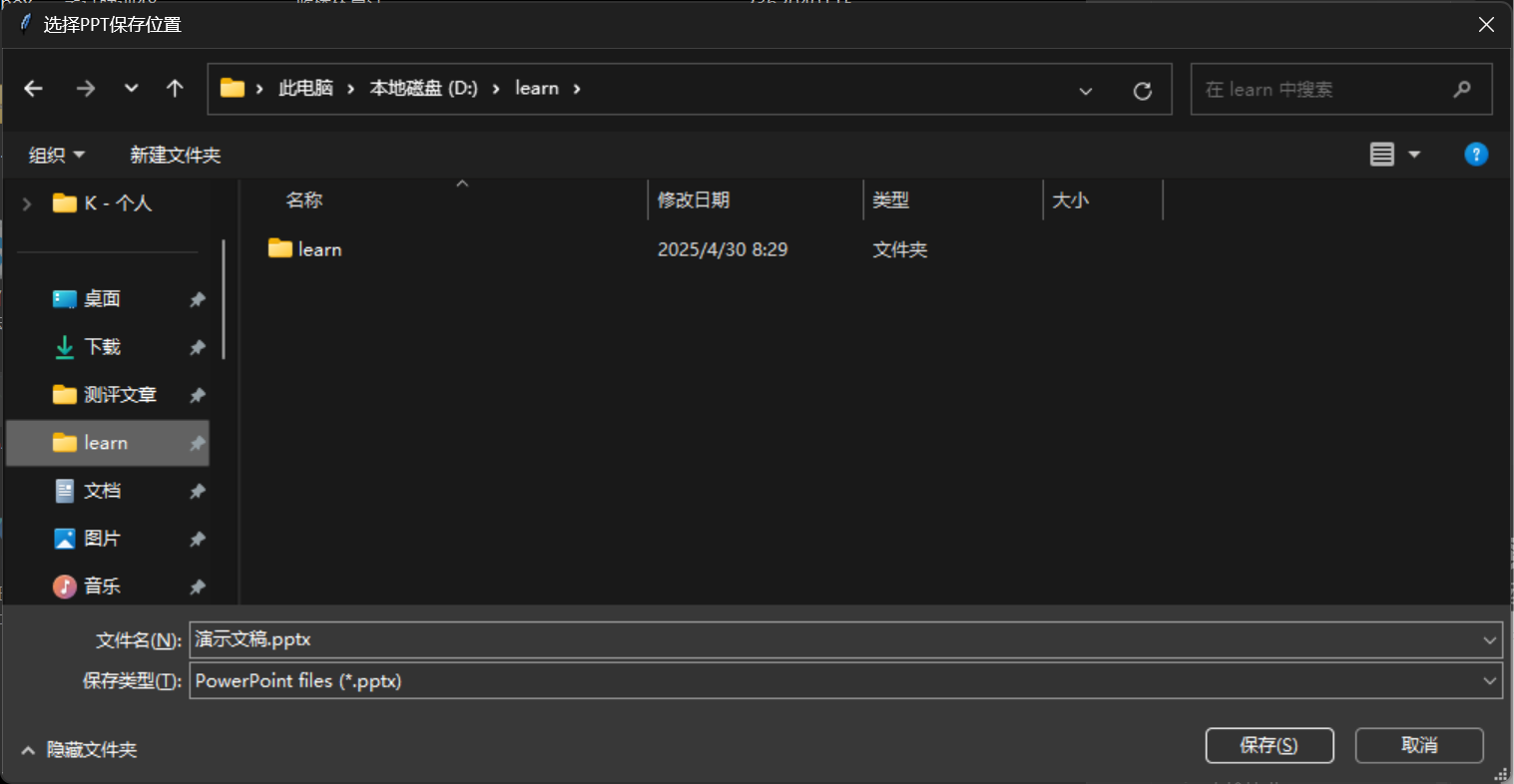
保存之后他会进行生成操作,我们稍等一会儿就好了
程序运行成功了
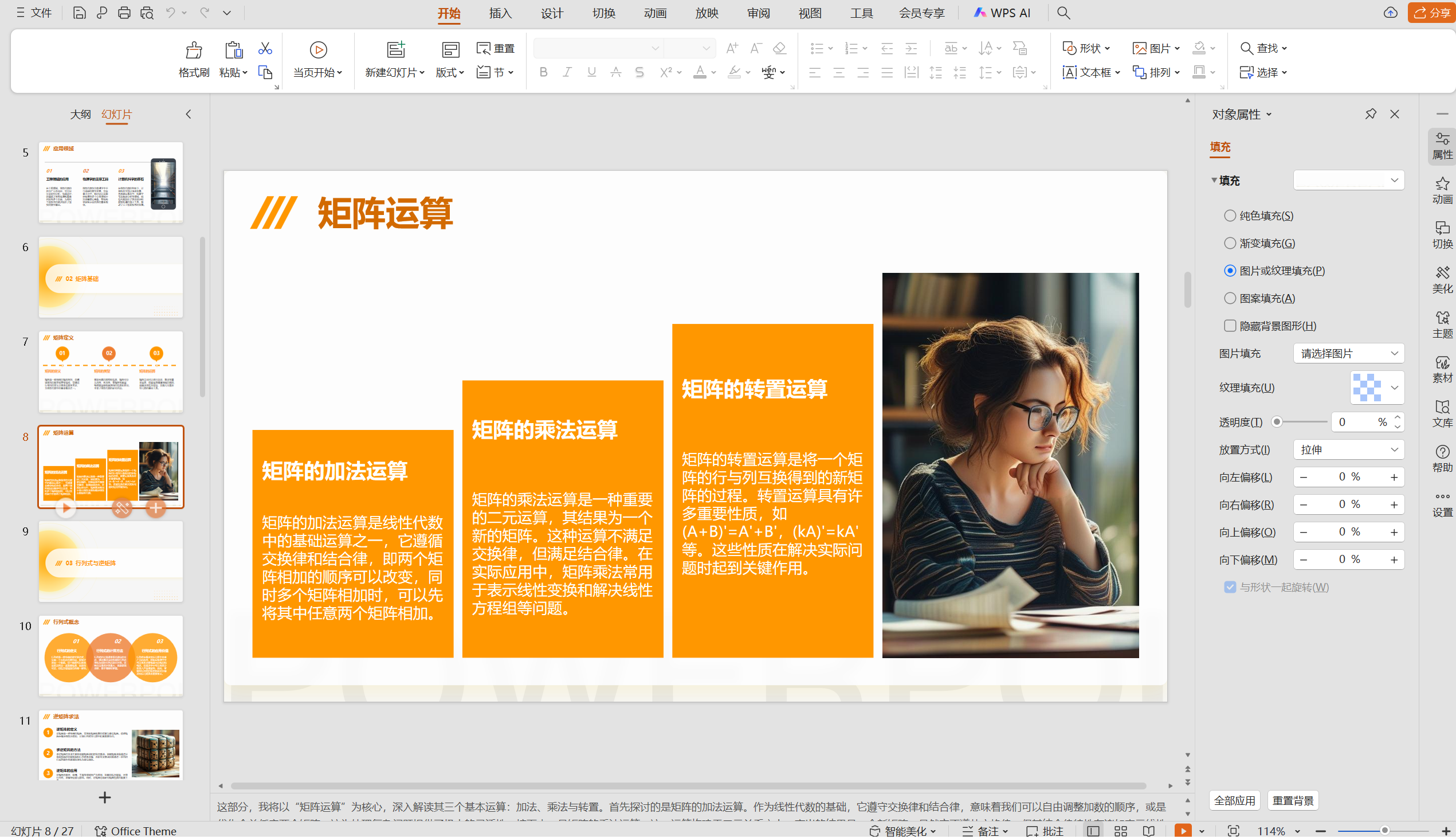
最后我们打开ppt文件,可见效果还是蛮不错的
总结
在信息爆炸、时间宝贵的当下,PPT 制作常因繁琐耗时成为诸多人士的困扰。影刀 RPA 的出现,为这一难题提供了高效解决方案。就如上,通过短短5条指令就能实现一整条自动化生成ppt的流水线操作,这难道不香吗?
想体验的可以来体验下
自动化生成ppt获取
密码是666666

















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









