






KMP算法
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
KMP有什么用
KMP主要应用在字符串匹配上。
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
(重点)next数组里的数字表示的是什么,为什么这么表示?
什么是前缀表?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
正确理解什么是前缀什么是后缀很重要!
如何计算前缀表
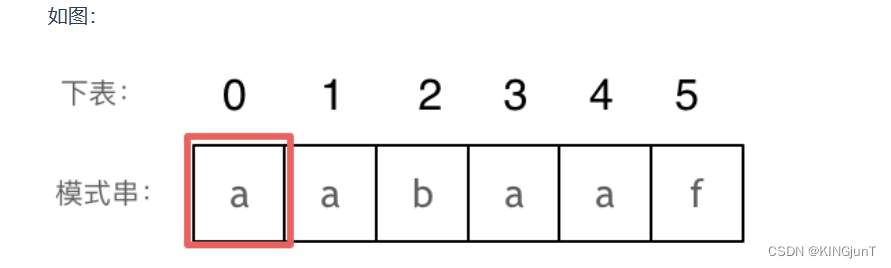
长度为前1个字符的子串a,最长相同前后缀的长度为0。(注意字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。)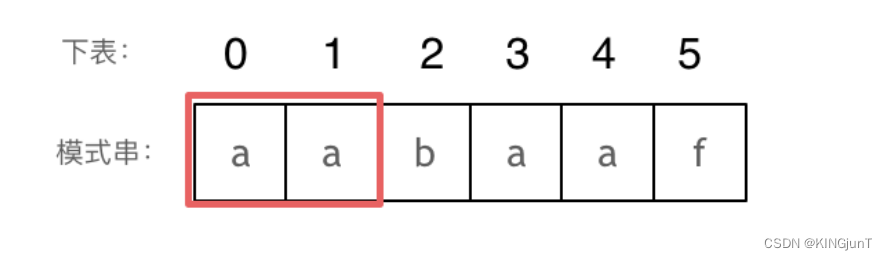
长度为前2个字符的子串aa,最长相同前后缀的长度为1。
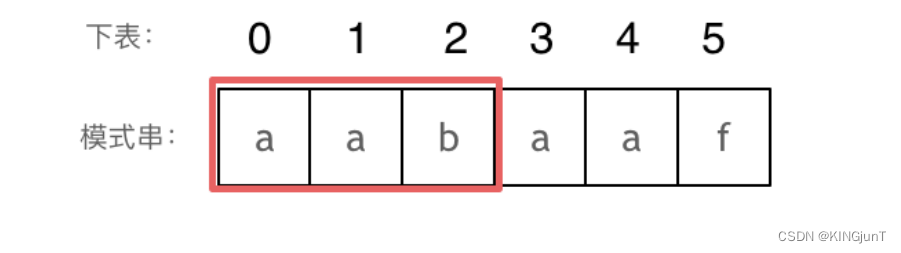
长度为前3个字符的子串aab,最长相同前后缀的长度为0。
以此类推: 长度为前4个字符的子串aaba,最长相同前后缀的长度为1。 长度为前5个字符的子串aabaa,最长相同前后缀的长度为2。 长度为前6个字符的子串aabaaf,最长相同前后缀的长度为0。

可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
前缀表与next数组
next数组就可以是前缀表
如何求next数组
设置i,j
i: 后缀末尾
j: 指向前缀末尾,同时也是 i(包括i)之前这个字串最长相等前后缀长度
分步骤实现
1.初始化
int j = 0;
int next[0] = 0;
for (int i = 1; i < s.size(); i++) 这里初始化i等于1 是为了能够于j做判断
2.前后缀不相等的情况
while (j > 0 && s[i] != s[j]) {
j = next[j - 1] 将next数组的前一个坐标给j,让j 回退
}
3.前后缀相等的情况
if (s[i] == s[j]) {
j++;
}
4.更新next数组
next[i] = j;
整体的代码如下:
void getNext(int* next, string &s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) { // 一直往前走,直到找到相同的
j = next[j - 1]; //返回next数组前一个值对应的下标索引
}
if (s[i] == s[j]) { //前后缀相同的情况,j向后移动
j++;
}
next[i] = j; //更新当前next数组
}
}
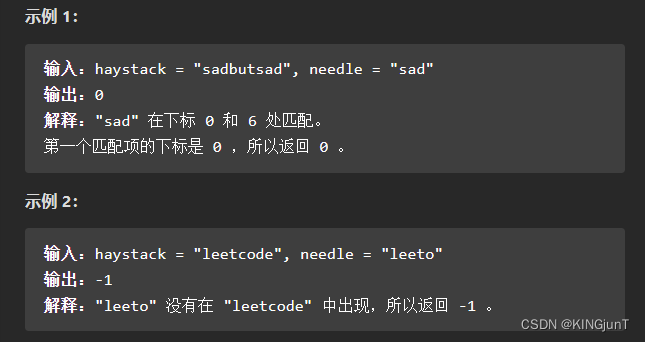
28. 实现 strStr()
题目链接 lc.28
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
思路:
- needle是模式串,haystack是文本串
- 用KMP算法解决本问题
- 先求出模式串的next数组,然后再同时去遍历两个字串
- 文本串用
i遍历,模式串用j遍历,再按照求next数组那样去求解 - 当
j == neddle.size()的时候,证明文本串里面出现了模式串,返回对应的下标
class Solution {
public:
void getNext(int* next, string &s) {
// 1、初始化
int j = 0;
next[0] = 0;
for (int i = 1; i < s.size(); i++) {
// 2、前后缀不想等的情况
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
// 3、前后缀相等的情况
if (s[i] == s[j]) {
j++;
}
//更新next数组
next[i] = j;
}
}
int strStr(string haystack, string needle) {
if (needle.size() == 0) {
return 0;
}
int next[needle.size()];
getNext(next, needle);
int j = 0;
for (int i = 0; i < haystack.size(); i++) {
while (j > 0 && haystack[i] != needle[j]) {
j = next[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == needle.size() ) { // 文本串s里出现了模式串t
// 返回起始位置坐标
return (i - needle.size() + 1);
}
}
return -1;
}
};
总结:
- KMP算法的使用很重要,要学会怎么构建next数组,然后用next数组辅助求解问题。
- 在达成条件的时候,返回起始坐标还需要再注意
459.重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
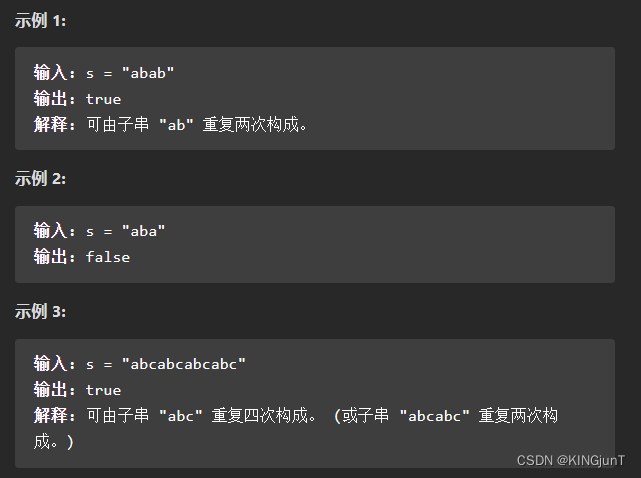
思路1:移动匹配
- 将字符串s+s组成新的ss,如果字符串能够由字串构成,那么一定能在ss里面找到s
- 掐头去尾很重要,防止找到前后两个原本的字符串
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string ss = s + s;
ss.erase(ss.begin());
ss.erase(ss.end() - 1); // 掐头去尾
if (ss.find(s) != std::string::npos) {
return true;
}
return false;
}
};
总结
- std::string::npos find函数在找不到指定值得情况下会返回string::npos。
- 去尾的时候记得是长度-1,索引从0开始
思路2:KMP算法
最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。
- 如果
next[len - 1] != 0,则说明字符串有最长相同的前后缀(就是字符串里的前缀子串和后缀子串相同的最长长度)。
其中len是字符串长度,len-1是末尾位置 - 如果
len % (len - next[len - 1]) == 0,则说明数组的长度正好可以被 (数组长度-最长相等前后缀的长度) 整除 ,说明该字符串有重复的子字符串。
class Solution {
public:
void getNext(int* next, string &s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if (s.size() == 0) {
return false;
}
int next[s.size()];
getNext(next, s);
int lenth = s.size();
if (next[lenth - 1] != 0 &&lenth % (lenth - next[lenth - 1]) == 0) {
return true;
}
return false;
}
};
总结2:
- 这个思路涉及到KMP算法,需要先明白KMP算法为什么可以解决这类问题是关键
- 需要自己去多模拟
- 最长相等前后缀的规则,当一个字符串由重复子串组成的,最长相等前后缀不包含的子串就是最小重复子串。
字符串总结
- 字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定
- string 重载了+,而vector却没有。
- 关于库函数:1.如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。 2.如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
- 双指针法:双指针法在数组,链表和字符串中很常用。
- 反转系列:当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
- KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
KMP的精髓所在就是前缀表,前缀表:起始位置到下标i之前(包括i)的子串中,有多大长度的相同前缀后缀。
前缀:指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀:指不包含第一个字符的所有以最后一个字符结尾的连续子串。
最重要的还是要理解 j = next[j - 1],这是构建next数组的关键
双指针回顾
这一部分就需要自己再从头梳理一遍了,结合 代码随想录网站的双指针法回顾章节,重新做一遍。














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









