






进入网站后,酷游红色开启浏览器开发者模式(F12),QA9观察8点CC下一页按钮的HTML标签内容
- 发现上一页按钮的a标签中有上一页的网址为「/bbs/MobileComm/index6520.html」
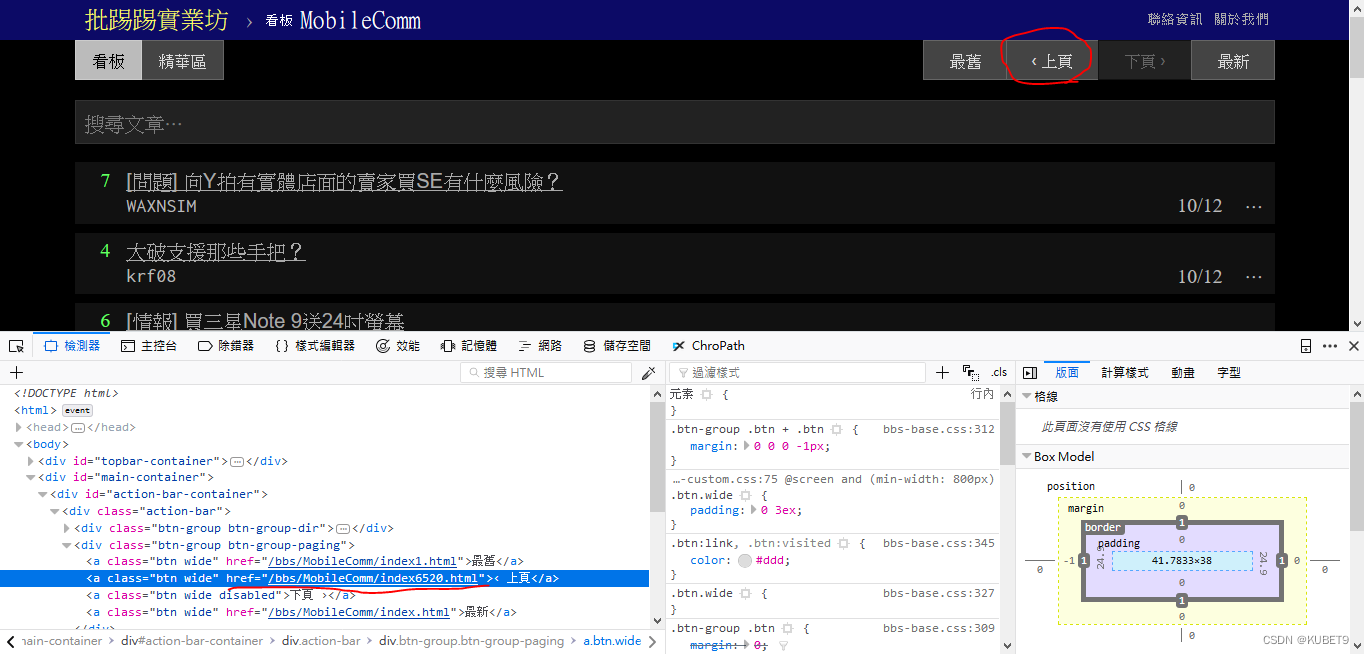
那我们就可以藉由撷取上一页a标签里的网址来GET上一页的网页下来了!!
r = requests.get("https://www.ptt.cc/bbs/joke/index.html")
汤 = BeautifulSoup(r.text,"html.parser")
u = soup.select("div.btn-group.btn-group-paging a")#上一页按钮的a标签
url = "https://www.ptt.cc"+ u[1]["href"] #组合出上一页的网址因为我们需要撷取多页(ex:3页),所以需要重新撰写程式码,藉由回圈来重复GET网页
import requests
from bs4 import BeautifulSoup
url = "https://www.ptt.cc/bbs/joke/index.html"
for i in range(3): #往上爬3页
r = requests.get(url)
soup = BeautifulSoup(r.text,"html.parser")
sel = soup.select("div.title a") #标题
u = soup.select("div.btn-group.btn-group-paging a") #a标签
print ("本页的URL为"+url)
url = "https://www.ptt.cc"+ u[1]["href"] #上一页的网址
for s in sel: #印出网址跟标题
print(s["href"],s.text)
遇到按钮
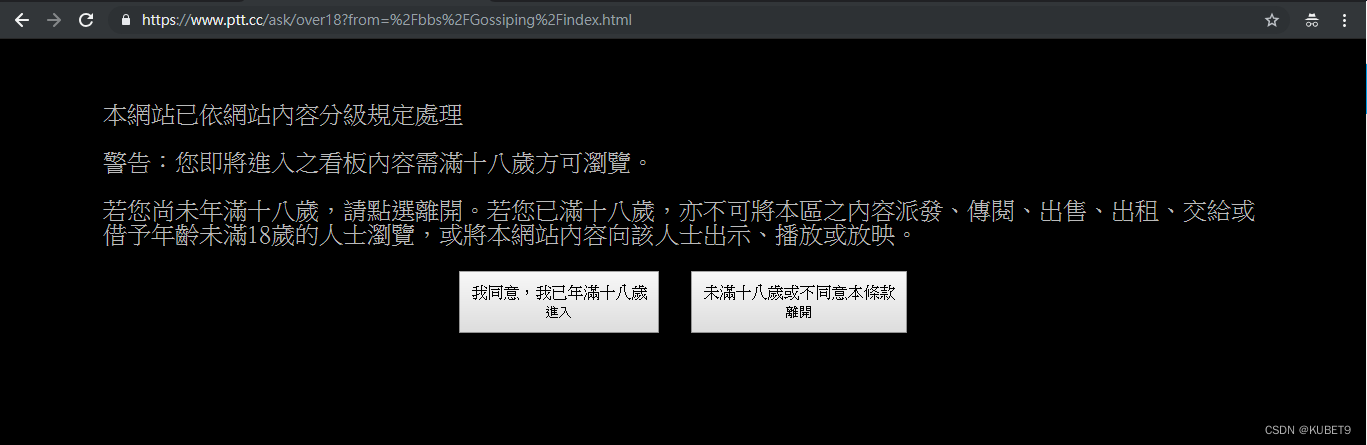
进入网站后会看到让使用者点选「是否已满18岁」按钮
此时可先开启浏览器开发者模式(F12),并点选至network(网路),观察点选「已满18岁」后,会送给伺服器之封包内容。

发现封包以POST发送,并且封包内容有cookie和参数

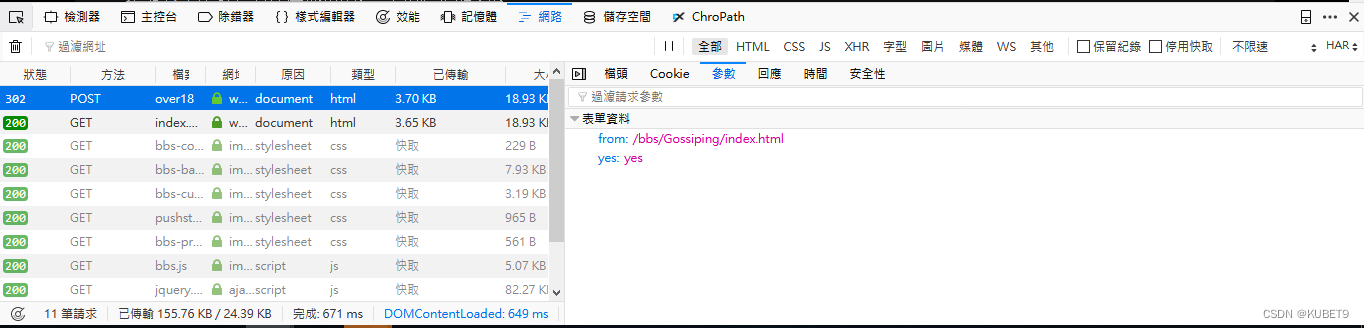
- 就表示说我们的程式码需要以POST的方式,并且要有送出cookie和特定的参数
- 如何储存自身的cookie?答案是可以藉由requests的一个参数来储存Session会将你送出的requests所收到的cookies全部储存起来并且在发送下一次请求时送出对应的参数。
requests.Session()
而封包内的参数,则可以加在POST后面,由前述可得知参数为from和yes,并得知参数内容。
payload={ #須送之參數
'from':'/bbs/Gossiping/index.html',
'yes':'yes'
}
requests.post("https://www.ptt.cc/ask/over18",data=payload) #將參數寫至data加上上一次写的程式码,成功爬到八卦版的网页
import requests
r = requests.Session()
payload ={
"from":"/bbs/Gossiping/index.html",
"yes":"yes"
}
r1 = r.post("https://www.ptt.cc/ask/over18?from=%2Fbbs%2FGossiping%2Findex.html",payload)
r2 = r.get("https://www.ptt.cc/bbs/Gossiping/index.html")
print(r2.text)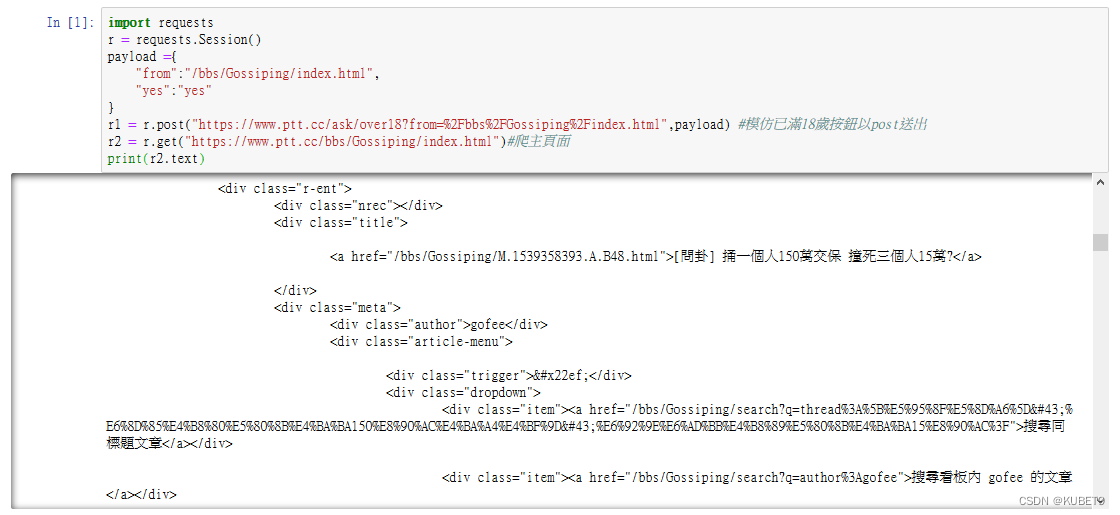















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









