







sql去重常用的基本方法
1.存在两条完全相同的纪录
select distinct * from table(表名) where (条件)
2.存在部分字段相同的纪录(有主键id即唯一键)
如果是这种情况的话用distinct是过滤不了的,这就要用到主键id的唯一性特点及group by分组
例子:
select * from table where id in (select max(id) from table group by [去除重复的字段名列表,..]
3.没有唯一键ID
m.*表示取m表的所有字段,然后其他的表不需要用到id,其他表只取特定字段,这样就不会发生id重复的问题了
例子:有成绩表和学生表
#成绩表
CREATE TABLE `SCORE` (
`SNO` varchar(3) NOT NULL,
`CNO` varchar(5) NOT NULL,
`DEGREE` decimal(10,1) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `SCORE` VALUES ('103','3-245',86.0),('105','3-245',75.0),('109','3-245',68.0),('103','3-105',92.0),('105','3-105',88.0),('109','3-105',76.0),('101','3-105',64.0),('107','3-105',91.0),('101','6-166',85.0),('107','6-106',79.0),('108','3-105',78.0),('108','6-166',81.0);
#学生表
CREATE TABLE `STUDENT` (
`SNO` varchar(3) NOT NULL,
`SNAME` varchar(4) NOT NULL,
`SSEX` varchar(2) NOT NULL,
`SBIRTHDAY` datetime DEFAULT NULL,
`CLASS` varchar(5) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `STUDENT` VALUES ('108','曾华','男','1977-09-01 00:00:00','95033'),('105','匡明','男','1975-10-02 00:00:00','95031'),('107','王丽','女','1976-01-23 00:00:00','95033'),('101','李军','男','1976-02-20 00:00:00','95033'),('109','王芳','女','1975-02-10 00:00:00','95031'),('103','陆君','男','1974-06-03 00:00:00','95031');
需求是查询所有选修“计算机导论”课程的“男”同学的成绩表
如果使用select * from table的方式会出现重复字段
SELECT * FROM score a,student b
WHERE a.sno = b.sno
AND b.ssex='男'
AND cno = (
SELECT cno FROM course WHERE cname='计算机导论'
)
查询结果如下
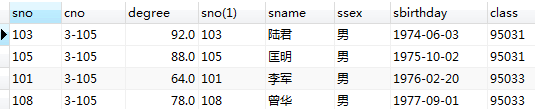
解决方案就是按需查询:
m.*表示取m表的所有字段,然后其他的表不需要用到id,其他表只取特定字段,这样就不会发生id重复的问题了
SELECT b.*,a.cno,a.degree FROM score a,student b
WHERE a.sno = b.sno
AND b.ssex='男'
AND cno = (
SELECT cno FROM course WHERE cname='计算机导论'
)
查询结果如下
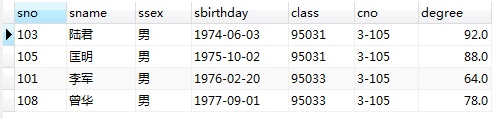
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









