







Elasticsearch分布式搜索引擎总结3
文章目录
一、数据聚合
1.DSL聚合基本语法
GET /索引名称/_search
{
"aggs": {
"my-agg-name": {
"AGG_TYPE": {}
}
}
}
2.聚合函数 – Bucket/Metric/pipeline
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/search-aggregations.html
①Bucket 桶聚合,用来对文档做分组
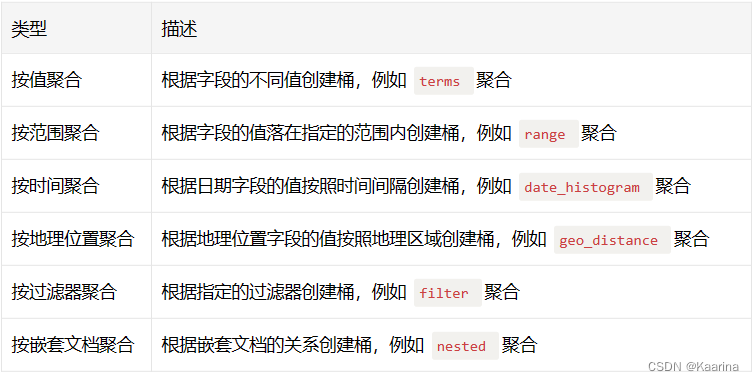
eg:
GET /indexName/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"_count": "asc"//升序
}
}
}
}
}
②Metric 度量聚合,用以计算一些值

eg:
GET /indexName/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": {//子查询
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}
eg:多字段聚合
GET /indexName/_search
{
"size": 0,
"aggs": {
"brandAgg": {//字段1
"terms": {
"field": "brand",
"size": 20,
"order": {
"_count": "asc"
}
}
},
"cityAgg": {//字段2
"terms": {
"field": "city",
"size": 20
}
}
}
}
③pipeline 管道聚合,其它聚合的结果为基础做聚合
3.在Java中RestClient的应用
searchRequest.source()
.aggregation(//相当于"aggs"
AggregationBuilders.terms("brandAgg")
.field("brand")
.size(20)
);
二、分词器
1.ik分词器
分词算法:
ik_smart :最少切分
ik_max_word:最细粒度划分
GET /_analyze
{
"text": ["哈哈哈"],//hhh、hahaha...
"analyzer": "ik_smart"//ik_max_word
}
2.拼音分词器
按拼音进行分词
GET /_analyze
{
"text": ["华为"],//huawei、hw...
"analyzer": "pinyin"
}
3.自定义分词器
必须在创建索引时声明才能使用
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {//索引库的创建
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
三、自动补全
1.DSL自动补全
①创建一个索引库music,并存在字段name支持自动补全
PUT /music
{
"mappings": {
"properties": {
"name": {
"type": "completion"
}
}
}
}
②插入文档数据
POST /music/_doc/1
{
"name": ["等", "等", "等"]
}
③查询自动补全

2.在Java中的自动补全应用
searchRequest.source()
.suggest(//补全字段
new SuggestBuilder()
.addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")//前缀
.skipDuplicates(true)
.size(10))
);
三、Java代码中实现数据同步
1.同步方案
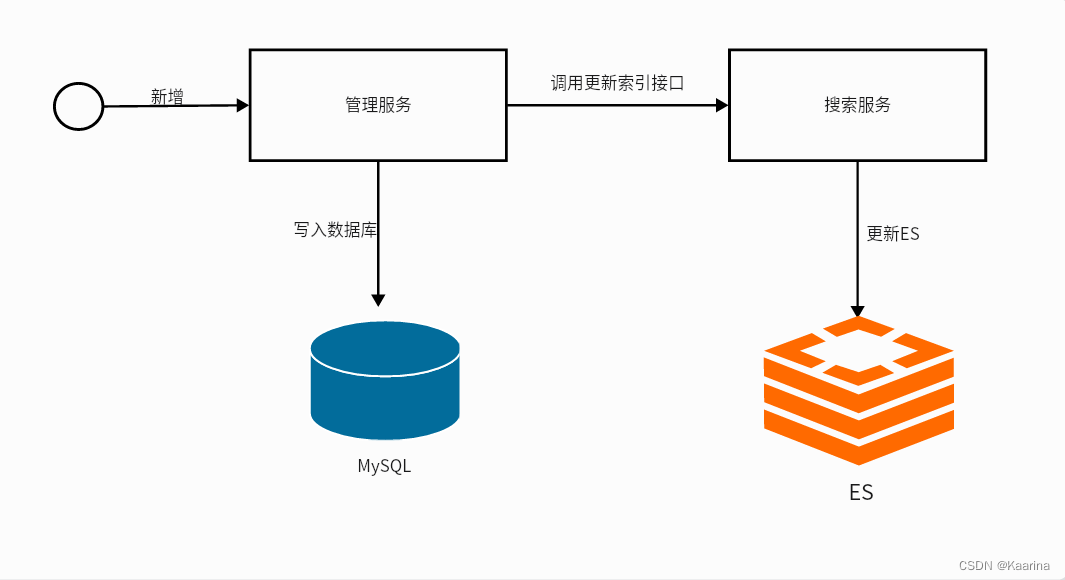
①同步调用
②异步通知
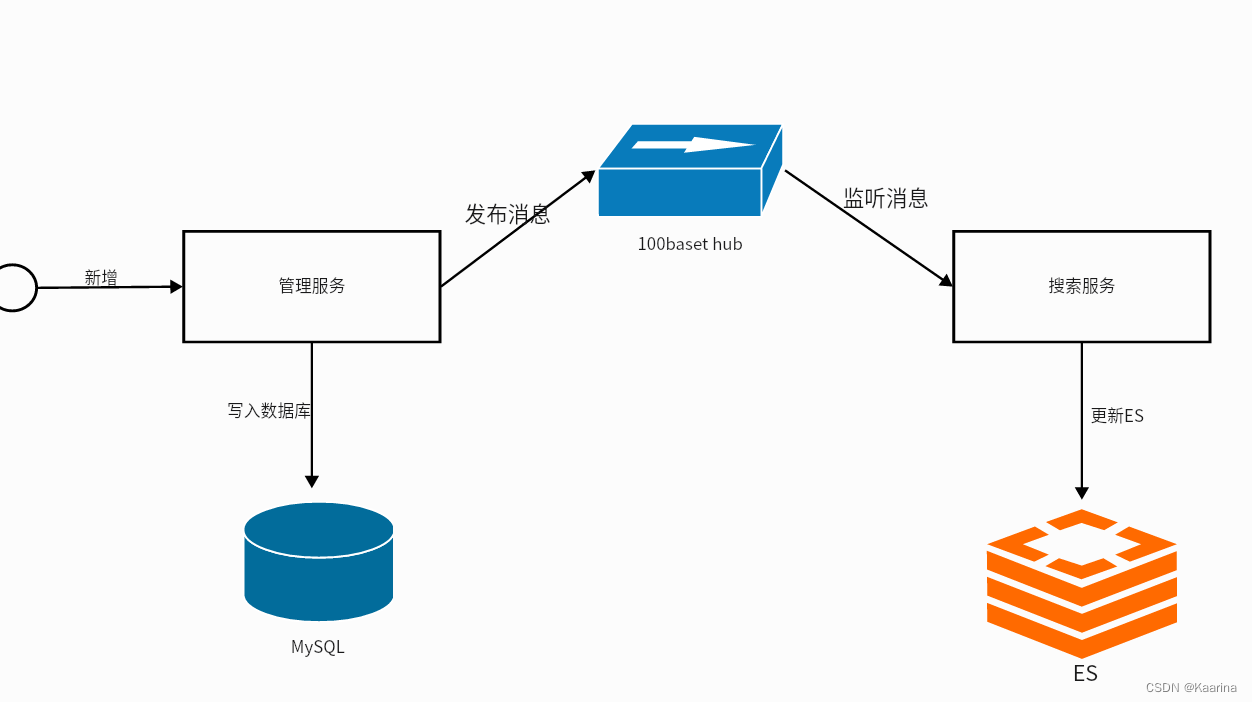
③监听Binlog
2.案例 – 异步通知的实现
1.在管理服务中发送MQ消息
/**
* 新增酒店
*
* @param hotel 酒店
*/
@PostMapping
public void saveHotel(@RequestBody Hotel hotel) {
hotelService.save(hotel);
rabbitTemplate.convertAndSend("hotel.direct", "hotel.insert_update", hotel.getId());
}
2.在搜索服务中监听MQ消息
/**
* 酒店插入或更新
*
* @param hotelId 酒店标识
*/
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(name = "hotel.insert_update.queue"),
exchange = @Exchange(name = "hotel.direct"),
key = "hotel.insert_update"
)
)
public void hotelInsertOrUpdate(Long hotelId){
try {
IndexRequest indexRequest = new IndexRequest("hotel").id(String.valueOf(hotelId));
Hotel hotel = hotelMapper.selectById(hotelId);
HotelDoc hotelDoc = new HotelDoc(hotel);
indexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("更新或新增失败", e.getMessage());
}
}















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









