









基础概念简述:
ES底层基于lucene实现,存储数据的基本单位是索引;
索引:index -> type -> mapping -> document -> field
ES架构:一般三个node节点,然后里面都是两两互备,如图:12, 13, 23形式。
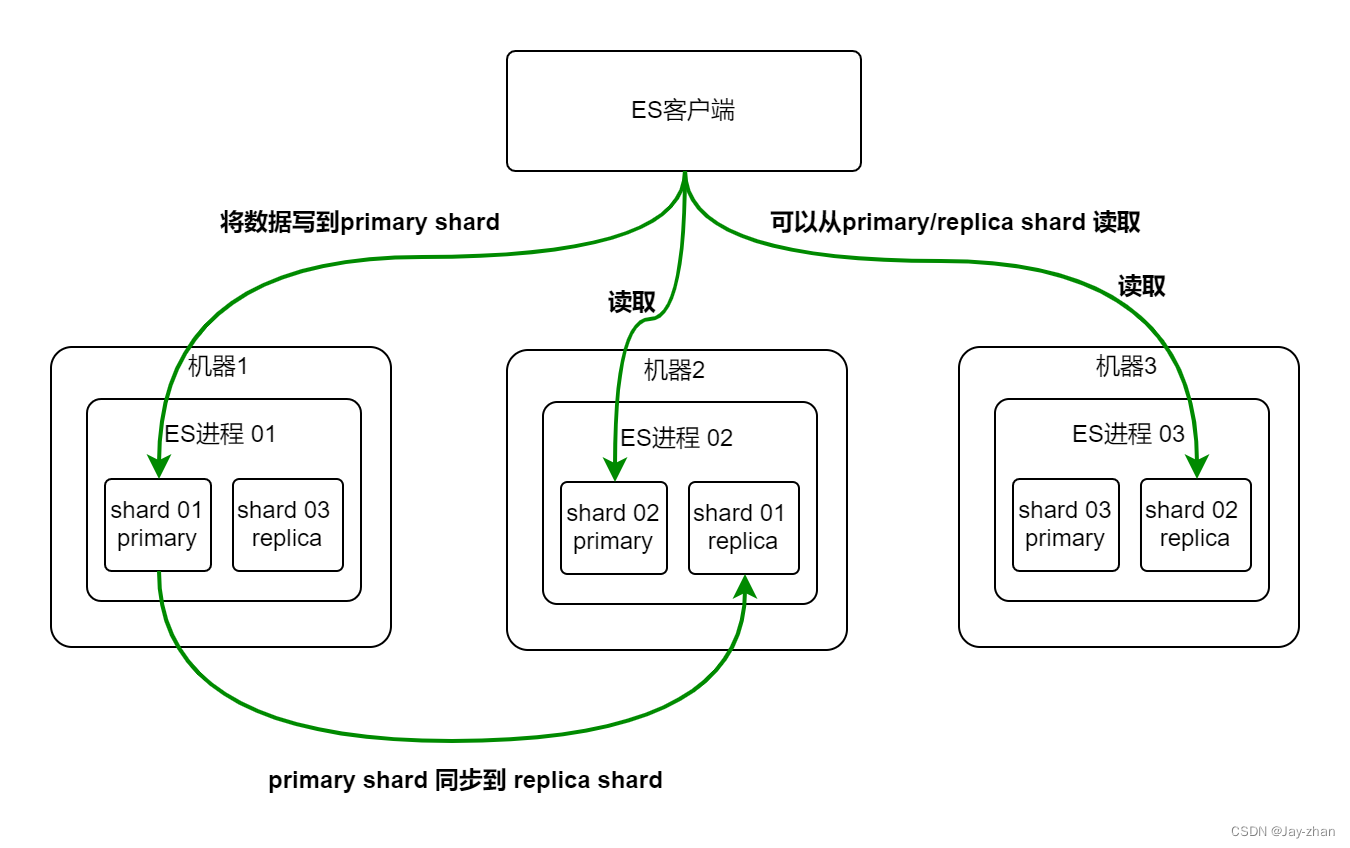
ES的写过程:
客户端随机挑选一个Node节点,该节点被称为代理(协助)节点,然后代理节点根据document进行路由到对应的node上,等待主shard写入完成,并且从shard也同步完成,即CP模型完成,返回给客户端。
底层原理:
1、随着数据不断进入buffer 和translog,不断将buffer 数据写入一个又一个新的segment file(内存) 中去,每次refresh 完buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当translog 达到一定长度的时候,就会触发commit 操作。
2、commit 操作发生第一步,就是将buffer 中现有数据refresh 到os cache 中去,清空buffer。然后,将一个commit point 写入磁盘文件,里面标识着这个commit point 对应的所有segment file,同时强行将os cache 中目前所有的数据都fsync 到磁盘文件中去。最后清空现有translog 日志文件,重启一个translog,此时commit 操作完成。
如果服务器宕机的话,也只是丢失5s的translog的日志,segment file cache可通过translog恢复。

ES的读过程:
客户端随机挑选一个Node节点,该节点被称为代理(协助)节点,然后通过doc id进行hash路由获取到主shard及所有的从shard,进行round-robin 随机轮询算法,负载到任意一个shard上获取document,返回到代理(协助)节点,然后再回到客户端。
倒排索引:
倒排索引是根据分词的属性的值来查找记录,也就是说,不是由记录来确定属性值,而是由属性值来确定记录,因而称为倒排索引。
注意倒排索引的两个重要细节:
1、倒排索引中的所有词项对应一个或多个文档;
2、倒排索引中的词项根据字典顺序升序排列
优化技巧:
面对超大数据量检索优化--- 合理使用 文件系统缓存(filesystem cache),性能优化的杀手锏。
原理:在大数据量,上亿或者十亿基本查询时,第一次的查询由于走的磁盘检索,所以会很慢,之后会将数据放到filesystem cache 内存,过程: 客户端 -> shard -> filesystem cache -> segment file。
方案:多机部署的时候,尽量你的机器的内存,至少可以容纳你的总数据量的一半。 例如:3台64G服务器,每台机器给es jvm heap 是32G,那么剩下来留给filesystem cache 的就是每台机器才32G,
总共集群里给filesystem cache 的就是32 * 3 = 96G 内存,整个磁盘上索引数据文件,在3台机器上一共占用了1T 的磁盘容量,es 数据量是1T,那么每台机器的数据量是300G,十分之一的数据放缓存,其余的都走磁盘,性能自然很差了。
还有关于无关的检索字段,就不要丢进ES了,白白占用内存,只丢需要搜索的字段可大大提高速度,其余的字段后你可以把他存在mysql/hbase 里,我们一般是建议用es +hbase 这么一个架构。
hbase的特点是适用于海量数据的在线存储,就是对hbase可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据id或者范围进行查询的这么一个操作就可以了。从es中根据name和age去搜索,拿到的结果可能就20 个doc id,然后根据doc id 到hbase 里去查询每个doc id 对应的完整的数据,给查出来,再返回给前端。写入es 的数据最好小于等于,或者是略微大于es 的filesystem cache 的内存容量。然后你从es检索可能就花费20ms,然后再根据es返回的id去hbase里查询,查20条数据,可能也就耗费个30ms,可能你原来那么玩儿,1T数据都放es,会每次查询都是5~10s,现在可能性能就会很高,每次查询就是50ms。
数据预热:如果进行了上述的方案,filesystem cache还是不够,那就只能预先进行冷热数据处理了,查询高频率的数据先load进去内存中。
冷热分离:es 可以做类似于mysql 的水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。最好是将冷数据写入一个索引中,然后热数据写入另外一个索引
中,这样可以确保热数据在被预热之后,尽量都让他们留在filesystem os cache 里,别让冷数据给冲刷掉,不同的机器放不同的index,互不干扰(不过个人感觉有点浪费内存。。)。
Tips:
1、document 模型设计越简单越好,别搞的像MySQL一样,各种关联查询,ES存的数据要最直接、简单、经过处理的结果集;
2、分页性能优化:默认深度分页性能很差,不允许(撒花~),类似下拉追加查看的,可以使用scroll api(个人没用过,网上推荐做法)。














 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









