







背景
因工作需要,要统计一些使用400客服电话的企业名单,百度的号码验证平台提供了一个查询的能力,对于已经收录的400电话,可以查询到对应的企业名称,但是直接request会遇到 ① url形式爬取到全是JS代码;② 使用post方法返回403 的两个问题。
解决过程
1、解决爬取到的全是JS代码的问题
问题:直接从url出手取到的全是JS代码
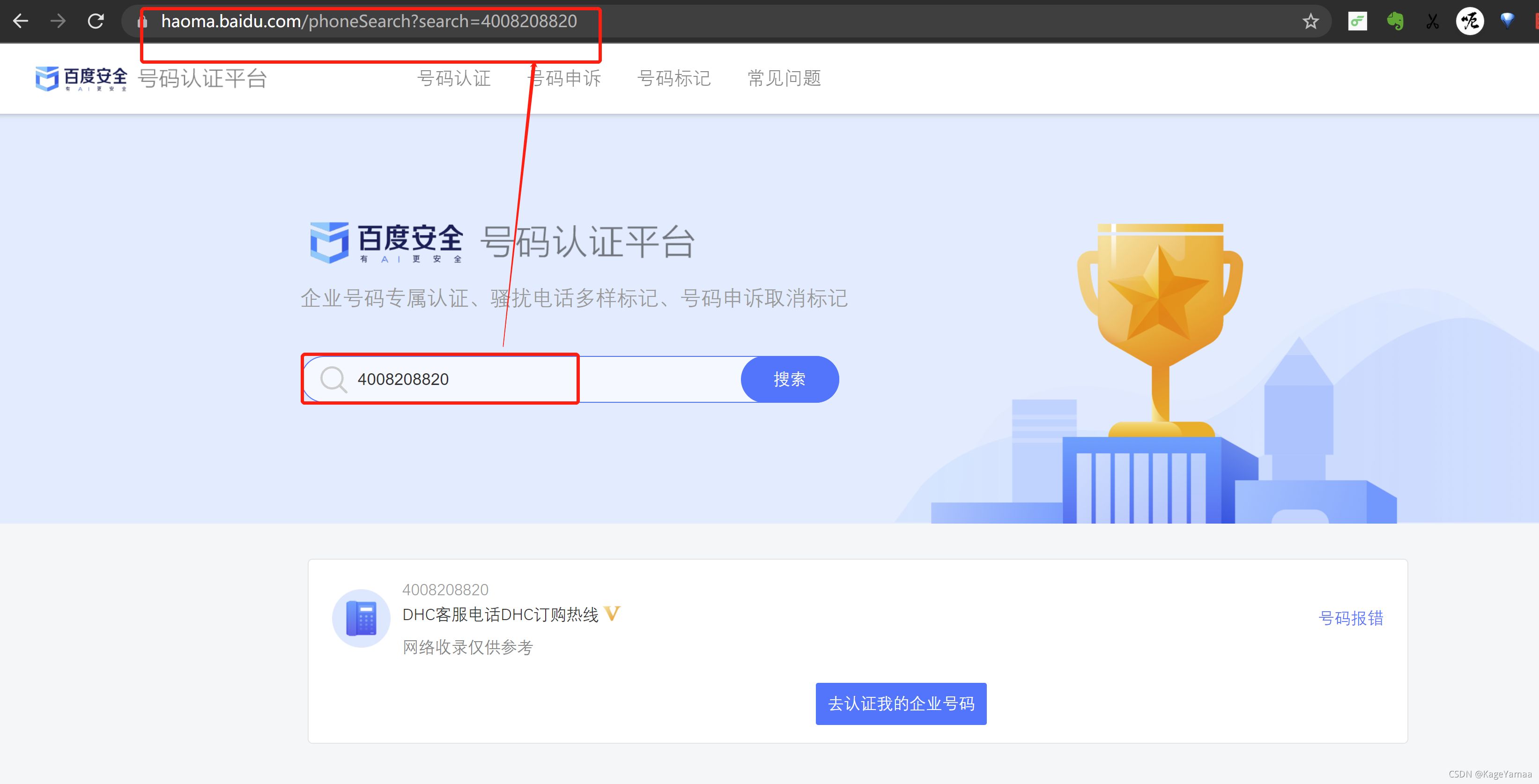 从截图可以看出,每次查询,顶部url中的search参数会切换为对应的搜索关键词,如 在输入框中输入“4008208820”,那么会url会变成:号码认证平台.
从截图可以看出,每次查询,顶部url中的search参数会切换为对应的搜索关键词,如 在输入框中输入“4008208820”,那么会url会变成:号码认证平台.
因此第一反应是,直接用get方法,每次切换电话号码时,修改对应的url参数。
# 切换电话号码时,修改对应的url参数
import requests as re
# 省略headers的配置环节
for each_number in range(起始号码,结束号码):
response = re.get(url + str(each_number))
print(response.text)结果意料之中,全是JS代码,意味着这条路走不通。

不过看到JS代码,我们应该想到,下方查询的结果肯定是从某个接口请求到的,我们如果能找到对应的api接口,并且构造以假乱真的请求,也许能从接口中拿到数据。
通过分析执行查询时检查模式下network变化找到数据请求的接口api</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2445
2445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









