






robots.txt协议
- robots.txt,称之为君子协议,里面规定了那些信息可以爬取,那些信息不可以爬取.下面以淘宝为例,进行展示.
–
首先在浏览器输入 www.taobao.com/robots.txt 这个网址,点进去就可以查询到这个txt文件的内容,下面展示部分txt内容.

http协议
-
概念
—服务器与用户之间的一种进行数据交互形式 -
常用请求头信息
–Use-Agent ----请求载体身份标识
–Connection ----请求完毕之后是断开连接还是保存连接 -
常用响应头信息
–Content-Type ---- 服务器响应回客户端的数据类型
https协议
- 概念
–安全的http协议,传输数据进行加密. - 加密方式
–对称密钥加密
–非对称密钥加密
–证书密钥加密
| 了解完以上的基本信息,就要进入代码部分了|
requests模块
-基于python的网络请求模块,功能强大,简单便捷,效率高!!!
- 如何使用
–指定url
–发起请求
–获取响应数据
–持久化存储 - 环境安装
–pip install requests - 实战编码
–任务1:爬取搜狗首页的数据 www.sougou.com
# 1、指定url
url = 'https://www.sogou.com/'
# 2、发起请求,get会产生响应对象
response = requests.get(url=url)
# 3、获取相应数据
page_text=response.text
print(page_text)
# 4、持久化存储
with open('./sougou.html','w',encoding='utf-8') as fh:
fh.write(page_text)
print('爬取数据结束!!!')
–任务2:网页采集器
–UA反爬虫机制,创建一个heads,让服务器以为是浏览器发出的请求。
# UA伪装
#UA---Use-Agent
import requests
url='https://www.sogou.com/web'
# UA伪装
headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) CriOS/31.0.1650.18 Mobile/11B554a Safari/8536.25'}
# 处理url携带的参数:封装到字典中
kw = input('enter a word:')
params={
'query':kw
}
# 对指定的url发起请求
response = requests.get(url=url,params=params,headers=headers)
fileName=kw+'.html'
page_text = response.text
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(fileName,'爬取成功!!')
- 任务三:破解百度翻译
–post请求(携带参数)
–响应数据是一组json数据
"""
import requests
import json
# 1、指定URL
post_url ='https://miao.baidu.com/abdr?_o=https%3A%2F%2Ffanyi.baidu.com'
# 2、post请求参数处理
wd=input('enter a word :')
data = {
'kw':'wd'
}
#3、进行UA伪装
headers = {"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39'}
# 4、请求发送
response = requests.post(url=post_url,data=data,headers=headers)
# 5、获取响应数据
dic_obj=response.json()
#6、持久化保存
fp=open('./dog.json','w',encoding='utf-8')
json.dump(obj=dic_obj,fp=fp,ensure_ascii=False)
print('over!!!')
-任务四:豆瓣电影排行榜
import json
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
params = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start': '0', # 从库中的第几部电影开始取
'limit': '20' # 每次取多少个
}
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39'
}
response = requests.get(url=url,params=params,headers=headers)
list_data=response.json()
fp=open('./douban.json','w',encoding='utf-8')
json.dump(obj=list_data,fp=fp,ensure_ascii=False)
print('over!!!')
–然后在网页中输入json,可以获得json解释器,复制保存好的json文件的代码,就可以看到结果。结果展示在下方。
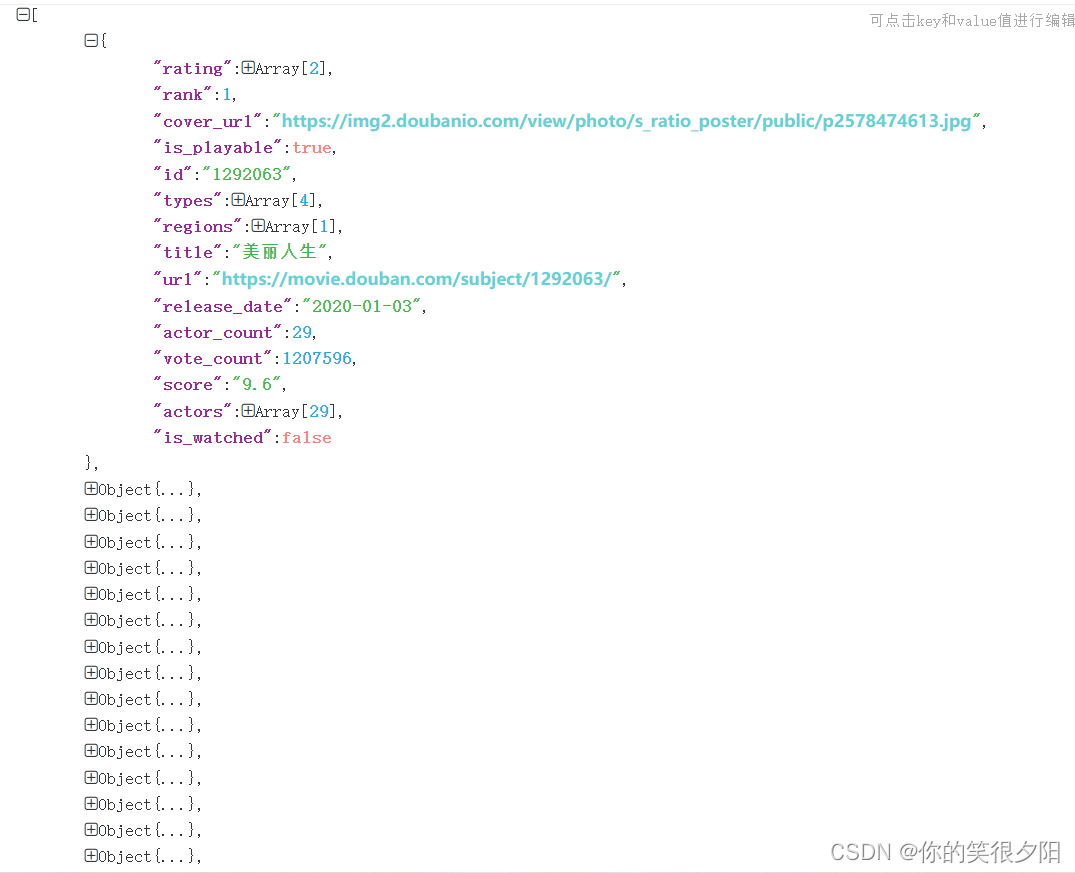
–第一部电影是美丽人生,一共爬取20部电影,改变爬取电影的多少,可以根据代码里面的limit参数来调节。
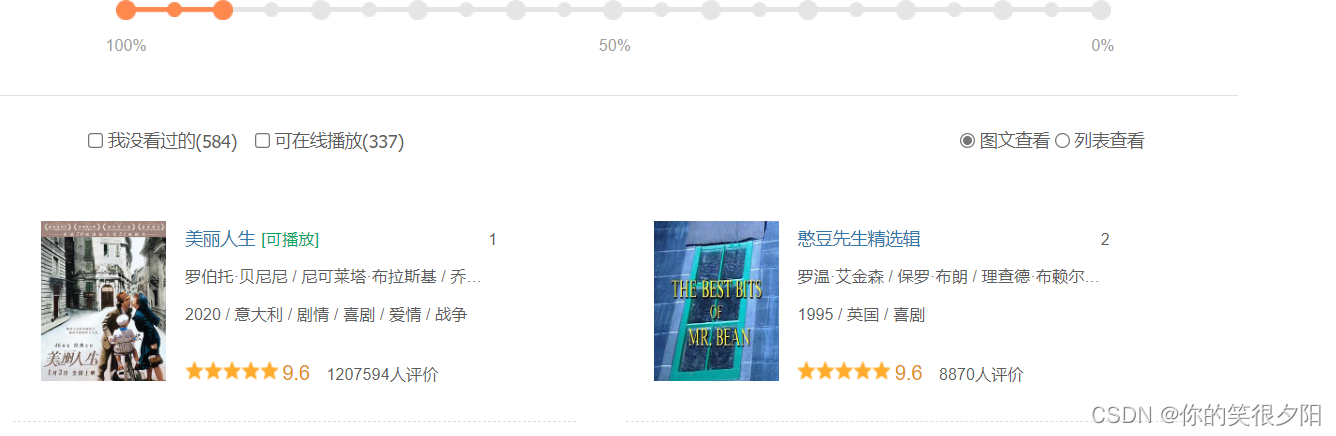
–爬取的数据与网页数据一致.















 6902
6902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











