







作者 | Y_yongqaing1
整理 | NewBeeNLP
推荐系统的传统召回方法是每个用户仅生成一个向量,会导致召回结果被最近的兴趣所主导。多兴趣召回方法旨在为每个用户生成多个向量,从而更精准的捕获用户兴趣。
下面,我调研了学术界以及工业界最近的多兴趣召回论文进展,内容以PPT格式呈现~由于本人水平有限, 希望各位大佬在评论区多多拍砖指正, 也希望有机会和各位老师交流学习。
CIKM 2019 阿里 MIND模型
KDD 2020 阿里 ComiRec模型
WSDM 2021 阿里 SINE模型
SIGIR 2020 微软亚洲研究院 Octopus模型
总结
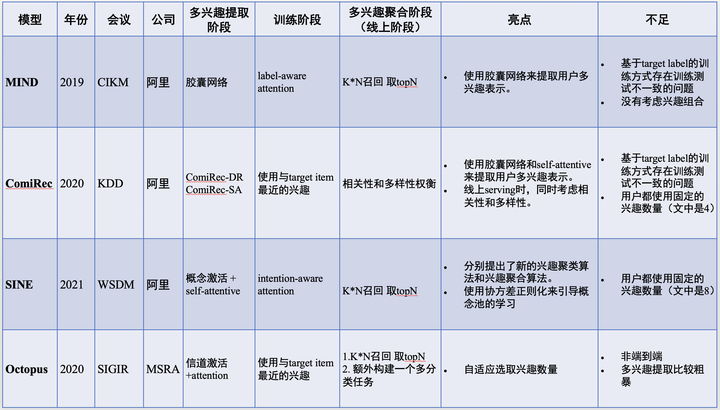
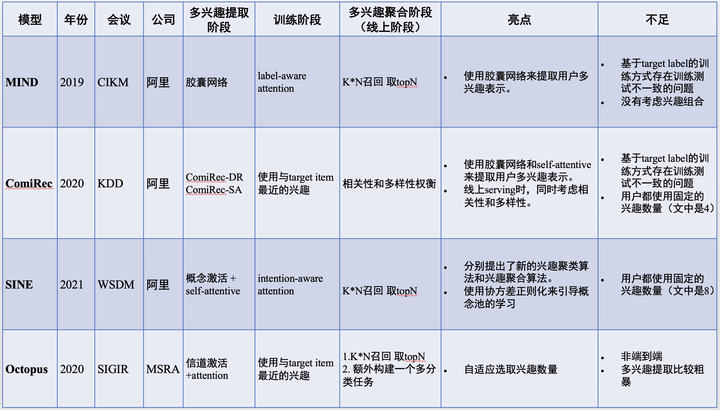
1 MIND模型(2019,CIKM,阿里)
MIND模型已经有众多前辈讲解过,您可以参考这篇知乎大佬的博客[俊俊:深度模型\] 阿里MIND网络:天猫首页是怎么给用户做多兴趣embedding的[1]。其中,如果想要了解胶囊网络的基础知识,可以读一读这篇:揭开迷雾,来一顿美味的Capsule盛宴[2]。
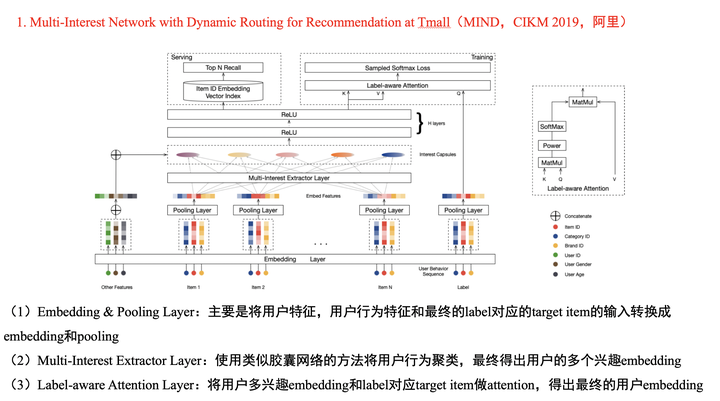



MIND是简单易懂且可解释性强的模型。
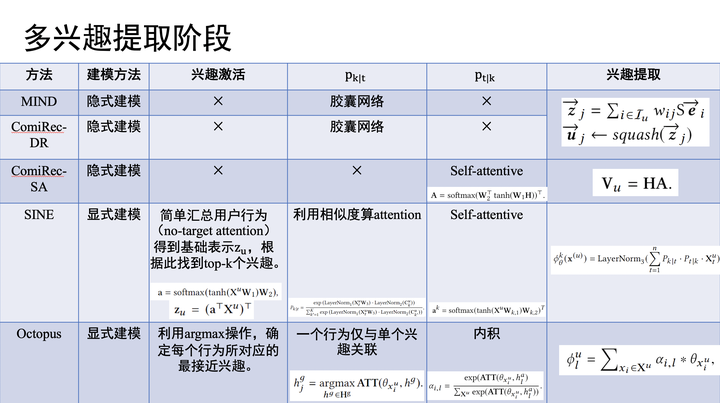
多兴趣提取阶段,第一,用户的每个历史行为分配给多个兴趣的总和为1。第二,在每个兴趣上,用户行为的贡献程度一致。
训练阶段,使用label-aware attention机制来考虑与目标item的相关程度,论文指出,通过调节超参数,让目标item只选择最近的兴趣向量,这样会加快收敛速度。
线上预测阶段,将K个用户兴趣向量都过ANN,然后选取top-N结果。
2 ComiRec模型(2020,KDD,阿里)
ComiRec模型的解读也可以参考相同的大佬的博客[俊俊:深度模型\] 阿里KDD2020多兴趣召回模型ComiRec[3]。
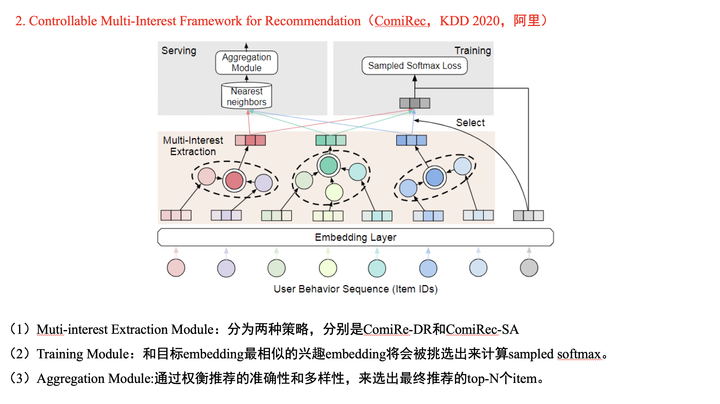



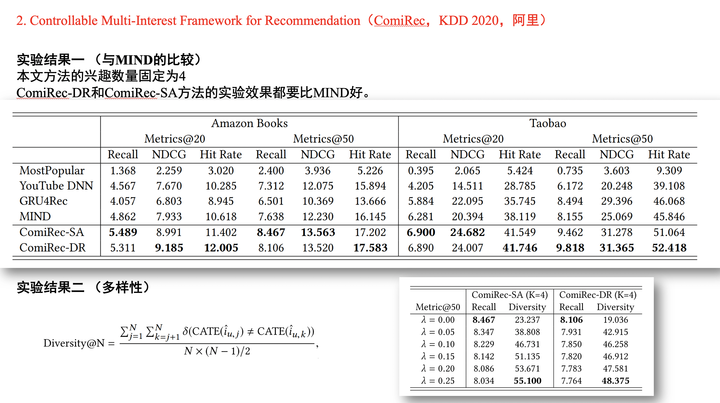

ComiRec是阿里和唐杰老师的一位博士合作的论文。在多兴趣提取阶段,论文使用了两种方法,分别是「胶囊网络」和「self-attentive」。其中,由于每个用户都使用固定的兴趣数量,所以胶囊网络方法可以使用原始的胶囊网络;而self-attentive方法可以说是本文的一大亮点,self-attentive机制出自论文A Structured Self-Attentive Sentence Embedding[4],有兴趣的可以读一读这篇博客[5]。
本文使用self-attentive的想法是通过关注不同的用户行为,来生成不同的用户兴趣。您可以看作:每个兴趣分配给所有用户行为的总和为1。训练阶段采用和MIND模型类似的方法。线上预测阶段,首先提取K*N个候选item,然后使用简单的贪心算法来兼顾召回结果的相关性和多样性。
值得一提的是,self-attentive和self-attention区别还蛮大的。之后,我会对它们的区别进行总结,有兴趣的可以关注我的知乎[6]哦~
3 SINE模型(2021,WSDM,阿里)
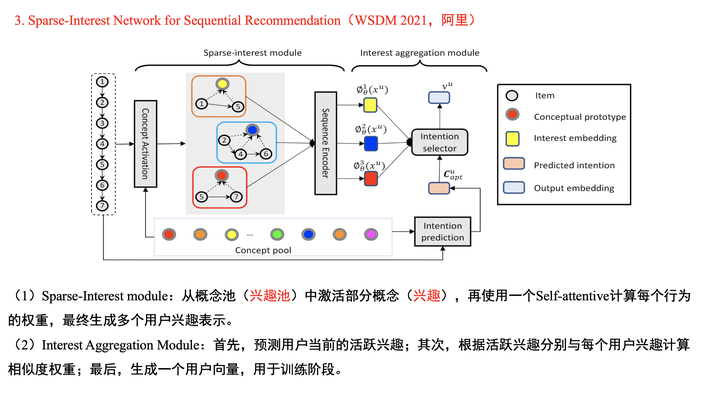



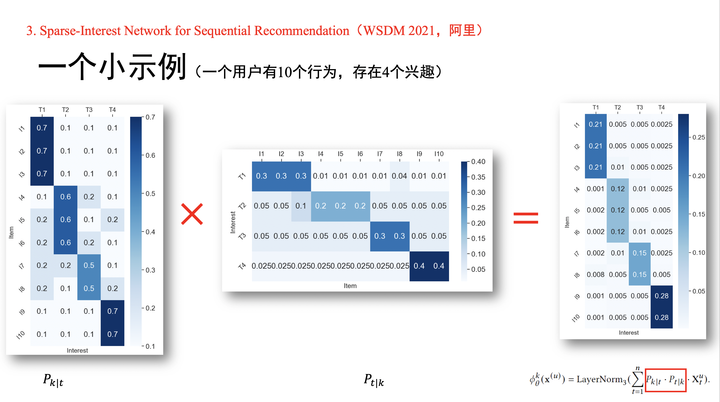




虽然Octopus模型发表时间比SINE模型要早,但是为了让大家对阿里的多兴趣召回工作有更深入的了解,所以就先讲解SINE模型。
在引言中,论文提出多兴趣的两种方法,分别是隐性建模和显性建模。我们今天讲的四篇论文中,前两篇是隐性建模,后两篇是显性建模。在多兴趣生成模块中,首先,通过用户的一个兴趣向量,在兴趣池中筛选出K个兴趣。然后,从两个不同的角度来计算用户行为和兴趣之间的权重信息(可以参考PPT中的小示例)。最后,生成出用户的K个兴趣向量。
值得一提的是,本文通过协方差正则化技术来引导兴趣池中的兴趣更加分散,进而具备差异化。本文的训练阶段和线上预测阶段都和MIND模型一致,就不在此赘述。
4 Octopus模型(2020,SIGIR,WSRA)
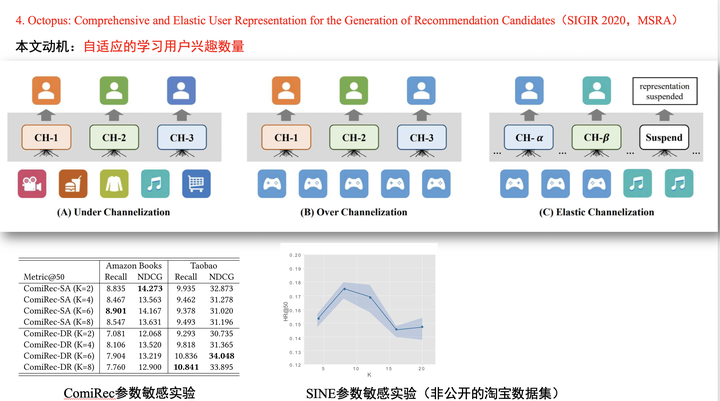
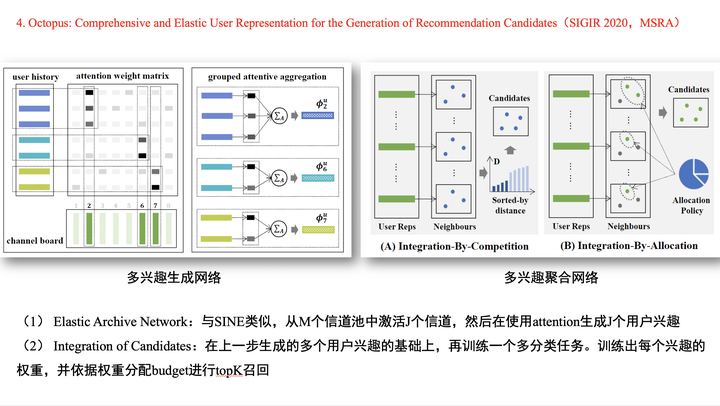




Octopus模型是微软亚洲研究院的关于召回多兴趣的工作,其主要动机就是自适应的选择用户兴趣数量。
在多兴趣提取阶段,直接将每个行为关联到兴趣池中最近的兴趣,这样关联的兴趣综合就是这个用户的兴趣数量。
进而,针对单个兴趣中的多个行为,使用一个简单的attention机制计算每个行为的权重。- 最终,我们就能得到用户的K的兴趣向量。
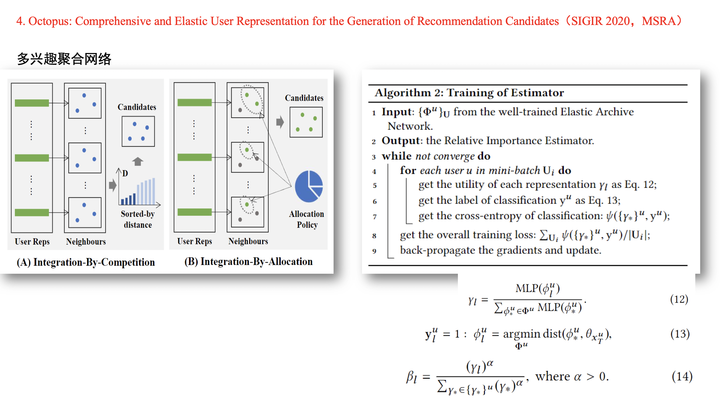
在训练阶段,使用与SINE模型类似的方法。在线上预测阶段,通过非端到端的再训练一个全连接网络,目的是想要计算不同兴趣向量的权重,最终根据这个权重来划分召回结果的bucket。
5 总结


一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

本文参考资料
[1]
俊俊:[深度模型] 阿里MIND网络:天猫首页是怎么给用户做多兴趣embedding的: https://zhuanlan.zhihu.com/p/140989406
[2]揭开迷雾,来一顿美味的Capsule盛宴: https://spaces.ac.cn/archives/4819
[3]俊俊:[深度模型] 阿里KDD2020多兴趣召回模型ComiRec: https://zhuanlan.zhihu.com/p/246582815
[4]A Structured Self-Attentive Sentence Embedding: https://arxiv.org/pdf/1703.03130.pdf
[5]博客: https://www.cnblogs.com/wangxiaocvpr/p/9501442.html
[6]知乎: https://www.zhihu.com/people/zha-zha-hui-88-86
- END -
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









