






AI自动化落地1 利用playwright+autoit 自动把markdown 转为微信公众号文章
直接看结果
markdown 自动转成微信公众号文章
实现的具体步骤(操作系统 windows)
第一步:安装git 安装Markdown Nice(墨滴)
它实现了 把markdown 转换为 微信公众号,知乎的功能
git clone https://github.com/zhaoqingyou/markdown-nice.git
我用的node 版本:18.17.1
注意事项:
- 直接 yarn 来安装依赖包
- 设置环境变量 避免openssl错误
$env:NODE_OPTIONS = "--openssl-legacy-provider"
- yarn start
第二步:安装autoid 模拟文件上传功能
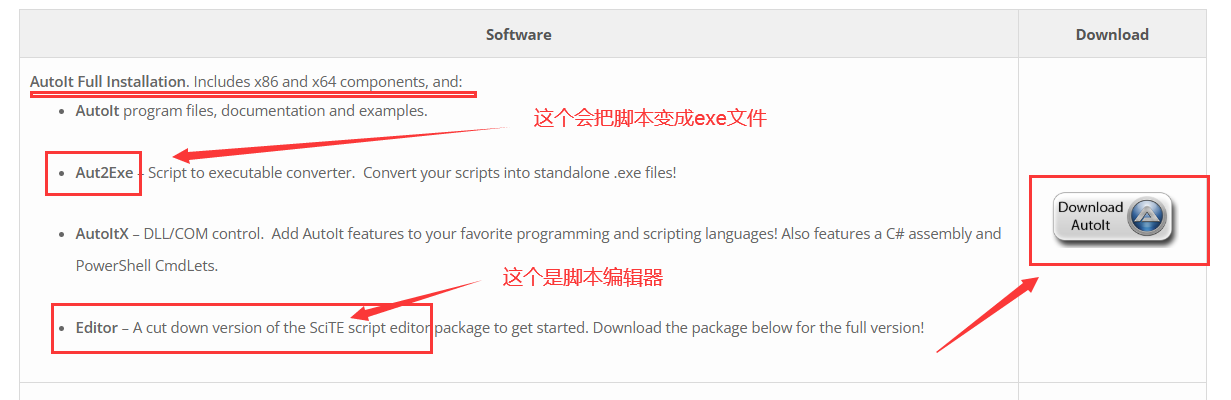
- 去官方下载 完全安装版本包括脚本编辑器:
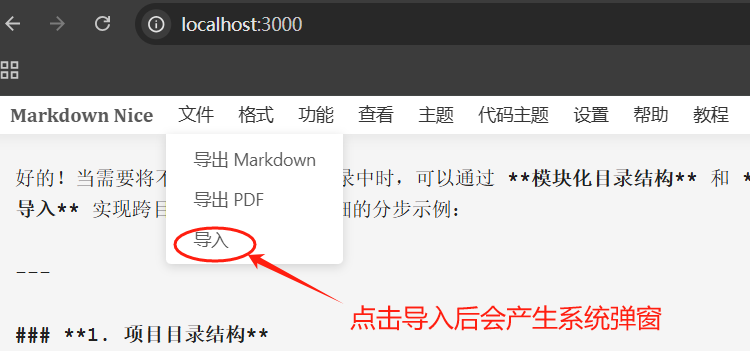
- 编辑脚本 用于模拟 点击浏览器里面 “导入” 按钮的时候,系统弹框 让选择markdown文件的操作。就是下面的这个图片
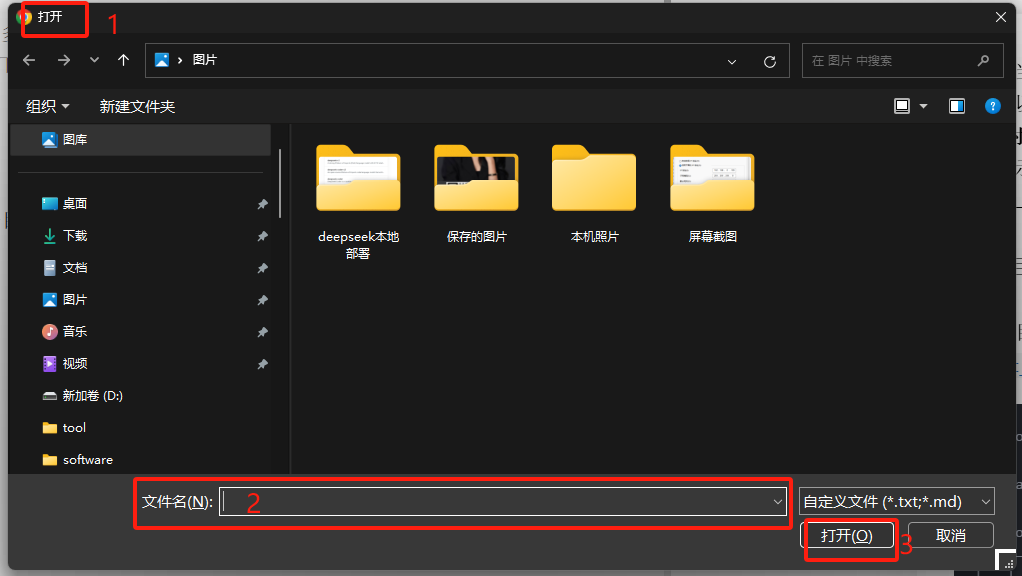
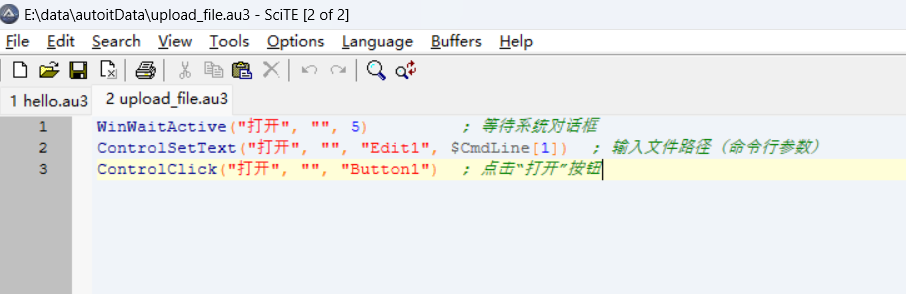
编辑的脚本代码:
WinWaitActive("打开", "", 5) ; 等待系统对话框
ControlSetText("打开", "", "Edit1", $CmdLine[1]) ; 输入文件路径(命令行参数)
ControlClick("打开", "", "Button1") ; 点击“打开”按钮
点击菜单 Tools->compile 就可以看到编译后的exe文件了
第三步:安装 playwright 实现浏览器获取页面元素操作
- playwright 安装版本
pip install playwright #默认1.51.0
- 浏览器驱动安装(因为安装源在国外 需要换成国内的安装源)
我会把安装脚本放到git 里面方便大家下载 - 最后的python 文件用 playwright 把Markdown Nice 和autoit 串联起来,把deepseek生成的markdown
文档自动转化为微信公众号文章,最后保存成html文件
playwright_and_autolt_modi.py 文件内容
import os
import subprocess
from playwright.sync_api import sync_playwright
from pathlib import Path
from datetime import datetime
file_path = r"E:\t\temp\md\module.md"
autoit_exe = r"E:\data\autoitData\upload_file.exe"
# 把markdown 自动转成微信公众、知乎文章
def get_webchat_content():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False, slow_mo=500)
# context =browser.new_context()
# 创建上下文并授予剪切板权限 避免下面复制剪切板内容的时候,出现弹框要求点允许分享
context = browser.new_context(
permissions=['clipboard-read', 'clipboard-write']
)
page = context.new_page()
# page = browser.new_page()
page.goto("http://localhost:3000/")
# 关闭弹框
# page.pause()
page.wait_for_timeout(1000)
page.get_by_role("button", name="确 认").click()
# 点击文件
page.click("#nice-menu-file")
# page.set_input_files("#importMarkdown", file_path)
page.wait_for_timeout(1000)
# 点击导入
page.click("#nice-menu-import-file")
page.wait_for_timeout(1000)
# 指定上传文件
subprocess.run([autoit_exe, file_path], check=True)
# page.pause()
page.wait_for_timeout(1000)
# page.click('xpath=//button[contains(text(), "复制")]')
# 点击复制按钮, 把markdown 变为公众号的内容
page.click("#nice-sidebar-wechat")
# page.get_by_role("button", name="复制").click()
page.wait_for_timeout(2000)
# 获取剪切板内容
# contents_value = page.evaluate('navigator.clipboard.read()')
contents_value = page.evaluate('navigator.clipboard.readText()')
print("剪切板内容", contents_value)
# page.pause()
page.wait_for_timeout(1000)
page.close()
browser.close()
# 保存剪切板内容到文件
save_clipboard_html_to_file(contents_value)
def save_clipboard_html_to_file(html_content):
# 保存到文件
html_file_path = create_date_dir(r"E:\t\temp\html")
file_name = file_path.split("\\")[-1]
split_first_name, ext = os.path.splitext(file_name)
final_name = os.path.join(html_file_path, split_first_name + ".html")
Path(final_name).write_text(html_content, encoding="utf-8")
print(f"HTML 内容已保存至 {final_name}")
def create_date_dir(base_path: str = "./data") -> str:
today = datetime.now()
year = today.strftime("%Y")
month = today.strftime("%m")
day = today.strftime("%d")
y_m_d = year + "_" + month + "_" + day
full_path = os.path.join(base_path, y_m_d)
os.makedirs(full_path, exist_ok=True)
return full_path
if __name__ == '__main__':
get_webchat_content()
最后总结
等deepseek 在根据我们的提示词模版 自动生成markdown 后再 自动调用我们这个python 脚本,就可以完全实现自动化的 产生文章了,
待定后续 第二片 deepseek的完全自动化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









