






在DIN: 阿里点击率预估之深度兴趣网络DIEN: 阿里点击率预估之深度兴趣进化网络
Overall
目前在DIN和DIEN上,使用了注意力机制,让候选item,attend到用户的行为序列上。但这样有一个问题,就是由于latency的原因,用户序列不能太长,所以只能attend到用户最近的行为序列上。
而我们知道,一个用户在淘宝上的行为序列是很长的,比如23%的用户最近5个月会点击超过1000个产品。如果只是使用用户最近的行为序列,那么信息会有丢弃,导致效果变差。
那么,用什么办法解决呢?
注意到在DIN中的使用attention的动机是用户的兴趣是多元的,为了触发用户的某个兴趣点,才做了attention,那么attention得到的权重中必然是那些跟候选item相近的产品才会权重比较大。比如,候选商品是包,那么用户行为序列中和包相关才会得到比较大的权重。
因此,可以考虑使用search的方法,在用户行为序列中进行初步筛选,得到相关的item再去做attention。也因此,本文的标题是Search-based user interest modeling。
两步策略
由上一节中,我们知道,需要先做初步筛选,然后再做类似DIN的模型处理。如下图所示:
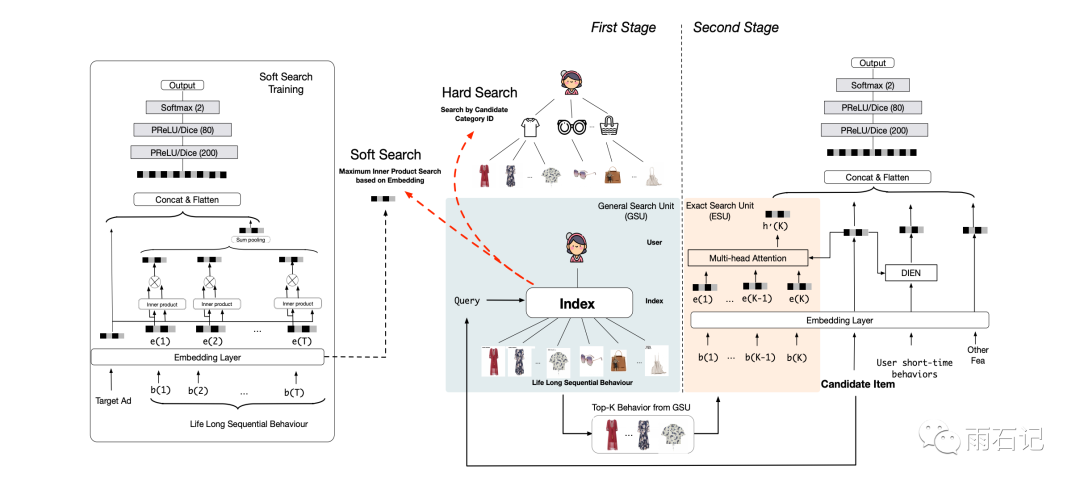
上图左侧是第一个阶段,即初步筛选。这里分为两个策略,第一个是soft search, 第二个是hard search。soft search是用候选item的embedding去和用户行为序列中的每一项的embedding去做点积,然后去top-K。这里可以使用的是一些高效方法是ALSH和MIPS的,都是已有的方法,咱们在基于Delaunay图的快速最大内积搜索算法
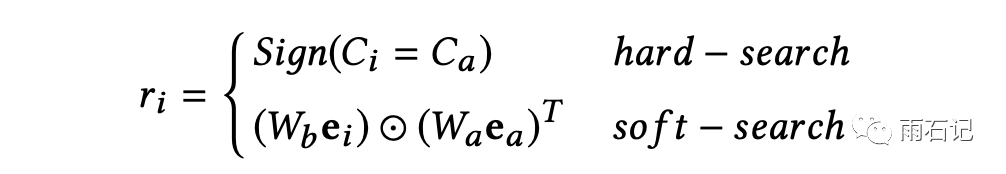
实验表明,hard search虽然结果会稍微差一些,但是会快很多。
无论是soft search还是hard search,在获取序列后都是用前面所提到的DIN或者DIEN进行处理,得到点击率预估的值。
特别注意一点,那就是虽然在serving的时候分了两步,但是在训练的时候,是同时训练的。之所以这样,是因为第一步和第二步所需要的用户序列是不一样的,第一步是用户的全部序列,第二步是选择后的序列,所以,想要在第一步中的序列的embedding效果好,需要在第一步中添加一个Auxulary loss。
第一步被称之为General Search Unit, 简称GSU。第二步被称为Exact Search Unit,简称ESU。
GSU也是google股票的简写。
GSU做完后,就得到了用户行为序列中相对于候选item的序列子集,然后对于序列子集中的每个item,提取了两种特征,第一种是item的embedding,第二种是item相对于候选item的时间差,即时间信息。这两种信息拼接起来,得到的embedding去做DIEN。
线上实现
实现要求,每个请求需要在30ms内响应,峰值用户数是1M。实现图如下,包含两个关键模块,计算节点和Real-time预测服务器。
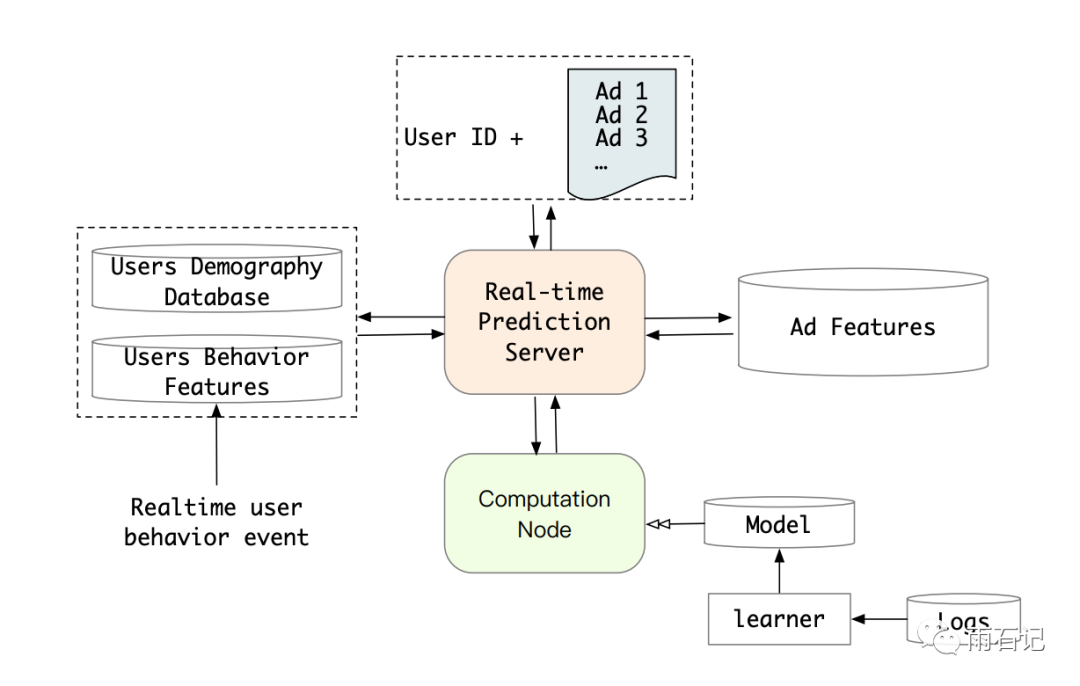
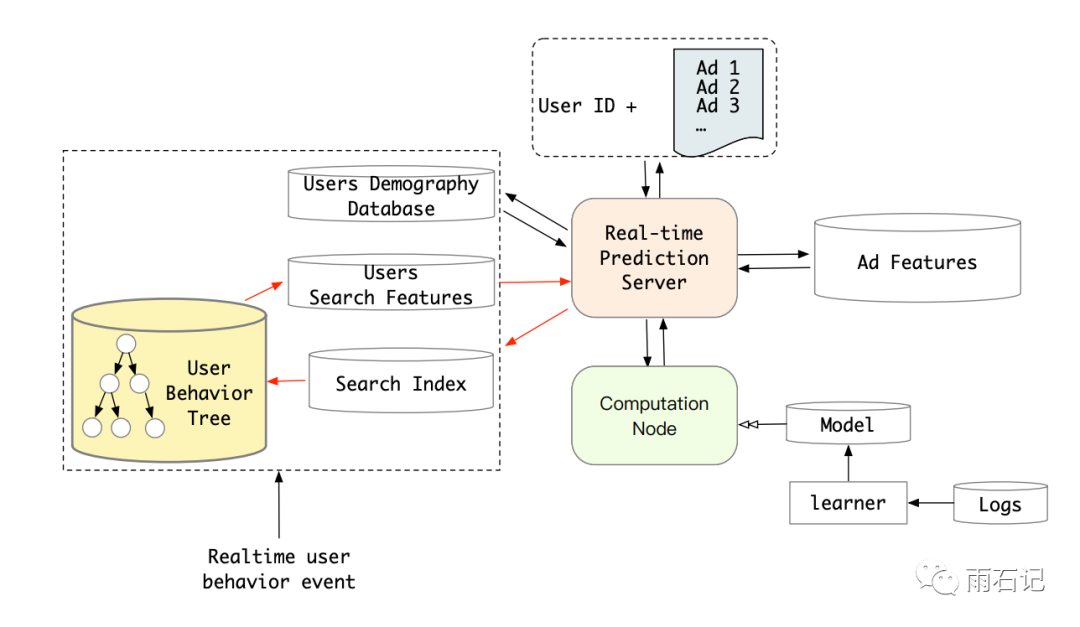
注意到,soft-search往往和hard-search的结果类似,因为相似的item往往是同品牌,同类别的。所以,为了latency考虑,线上使用了hard-search。
为了快速索引,建立了一个树结构,Key-Key-Value结构,对用户的行为序列进行存储,第一个key是用户id,第二个key是类别,value则是具体的item。这个树结构足有22TB,放在分布式系统上。
实验
在线下实验中的industrial 数据集上结果如下:
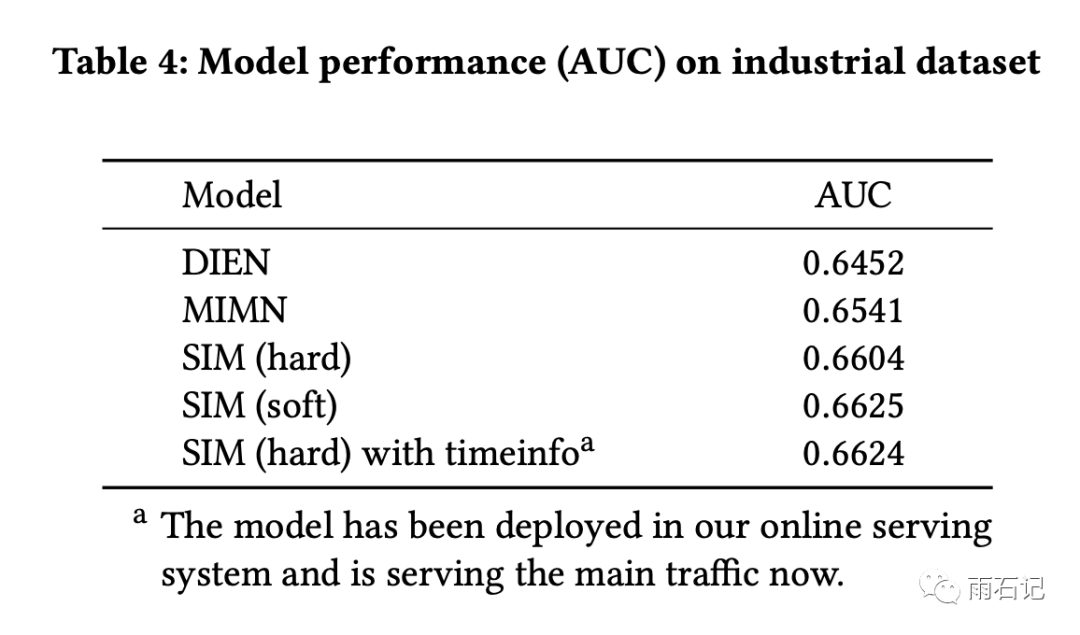
可以看到,hard和soft-search的差别挺小,但相对于之前的系统,都有较为明显的提升。
在线上则是带来的7.1%的CTR提升和4.4%的RPM提升。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

参考文献
[1]. Pi, Q., Zhou, G., Zhang, Y., Wang, Z., Ren, L., Fan, Y., ... & Gai, K. (2020, October). Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (pp. 2685-2692).
- END -























 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









