







 SIM模型采用召回+精排策略处理万级别序列行为数据,通过General Search Unit(GSU)和 Exact Search Unit(ESU)提取与候选AD相关的行为。GSU的hard-search和soft-search方法在处理长期用户兴趣时有效,而ESU利用时间状态属性改进了注意力机制。实验表明,该模型在淘宝线上及公开数据集上表现出色。
SIM模型采用召回+精排策略处理万级别序列行为数据,通过General Search Unit(GSU)和 Exact Search Unit(ESU)提取与候选AD相关的行为。GSU的hard-search和soft-search方法在处理长期用户兴趣时有效,而ESU利用时间状态属性改进了注意力机制。实验表明,该模型在淘宝线上及公开数据集上表现出色。
万级别:SIM《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》
到了万级别,序列行为可能考虑的事情就不再是提取用户兴趣了,而是“过滤对于当前预估的噪声”。

MIMN 虽然通过计算分离的方式确保了时延方面无压力,但也带来了更新频率不一致,行为序列无法与候选 AD 更好的交互等问题。线上使用时,作者发现当序列长度超过 1k 时,MIMN 效果会变差(也是因为无法与候选 AD 交互)。
这个时候干脆模仿起推荐系统的召回、精排方法,对序列特征再做一次“召回”和“精排”:第一阶段Genral Search Unit(GSU)通过相对粗略的搜索模式,提取行为序列中与候选 AD 较相关的节点,第二阶段Exact Search Unit(ESU)通过精准搜索的模式,得到序列与候选 AD 的关系,并形成 embedding 供 MLP 使用。这个模型能吃下的最大序列长度为 54000,能满足工业界提取长期用户兴趣的需求。
这种召回+精排的思想之前也在AlphaCode见过一次了。
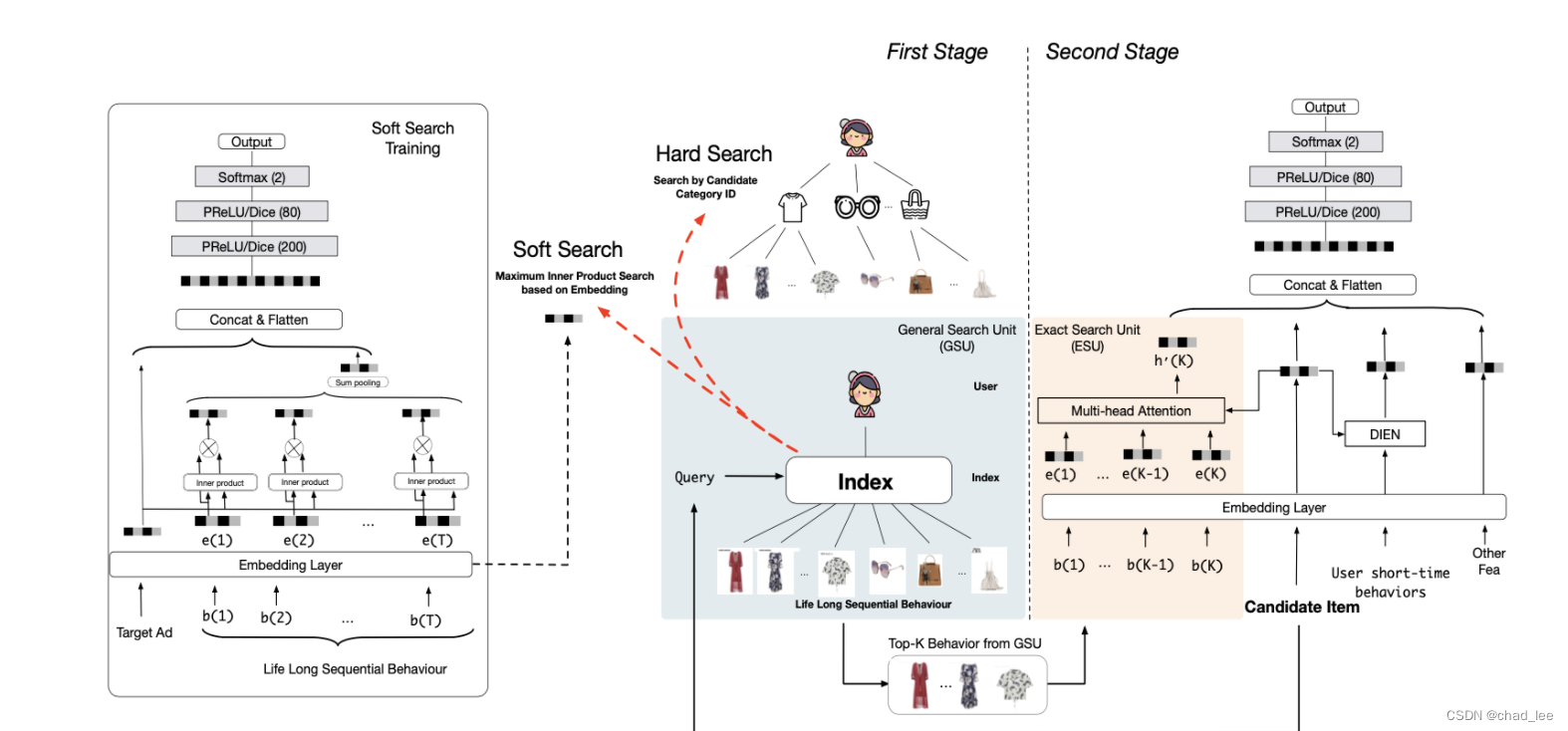
GSU
两种方案:hard-search 和 soft-search。给定用户行为 B = [ b 1 ; b 2 ; ⋯ ; b T ] \mathbf{B}=\left[\mathbf{b}_{1} ; \mathbf{b}_{2} ; \cdots ; \mathbf{b}_{T}\right] B=[b1;b2;⋯;bT],GSU给每一个用户行为计算一个相关性分数 r i r_i ri,然后根据 r i r_i ri 从B中选出Top-K相关行为:
r i = { Sign
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









