







1.paper介绍
该模型于KDD2018上发表,由阿里妈妈广告技术团队推出。
文章题目-《Deep Interest Network for Click-Through Rate Prediction》
在广告点击率预估中,深度模型常见架构为Embedding&MLP。在模型的输入阶段,不管 ad_id 是什么,输入特征都会被压缩成一个定长的向量表达,这会使得模型遇到一个瓶颈:定长的向量无法从丰富的行为数据中捕捉到用户广泛的兴趣偏好。
DIN模型提出了局部兴趣单元的结构,来从历史行为数据中自适应的学习到用户对于广告的兴趣,提高了模型的表达能力。除DIN模型本身外,paper针对工业界深度模型的训练,提出了两个训练模型的trick:小批量感知的正则化技术、数据自适应激活函数。具体解释下小批量感知的正则化技术的原理:我们在模型的结构损失函数(例如常用的二分类的交叉熵函数)上一般会再加上一个正则化约束,常用的为l2正则,我们在训练每个mini_batch时候,计算当前batch的损失函数值时,在l2正则部分会计算上所有模型参数,对于复杂的模型,这会带来巨大的计算量,paper的小批量感知正则化只需要对当前的mini-batch中非零特征的参数计算其正则,这大大减少了计算量。
DIN在两个公开数据集以及阿里巴巴公开的真实生产数据集上的实验证明,DIN为当前最优的CTR预估模型。
用户的不同兴趣都是通过用户行为来表达的,但是用户的所有兴趣都被压缩成为一个定长的向量,这限制了Embedding&MLP模型的的表达能力。一个直接的解决方式是通过增加定长向量的长度来增加模型的表达能力,但是这会带来几个缺点:1)扩大参数数量,在有限的数据下增加了模型过拟合的风险;2)增加了计算和存储的压力,这在实际工业系统中是不可接受的。
基于给定的候选广告,通过考虑历史行为中的相关因素来自适应地计算用户兴趣的向量表达。DIN引入了局部激活单元,其作用是:基于给定候选广告,从用户历史相关的行为中软搜索出用户相关的兴趣,局部激活单元只关注与候选广告相关联的用户兴趣部分,并且计算用户各个兴趣的加权和来表达用户兴趣。其中与候选广告相关性越高的行为将会获得越高的机会权重并主导用户兴趣的表达。paper在实验部分可视化了对于不同的广告,用户不同的兴趣向量的表达情况,这种差异性增强了DIN模型的表达能力,帮助模型能够捕捉到用户不同的兴趣。
2.其他深度CTR模型
这一块,除了列举业界常见的DeepCTR模型,因为paper种引入了局部激活module,因此paper作者对于attention相关的技术也有过深入的调研和了解。paper种在DeepCTR技术、attention技术以及结合了attention的DeepCTR技术的实现上,举的例子有NNLM、LS-PLM、FM,以及Deep Crossing、Wide&Deep Learning、YouTube Recommendation CTR,这三个相似结构的模型对于LS-PLM 和 FM的改进是将transforming function替换为MLP 网络,哈哈哈,尤其注意的只,这里提到的了YouTube Recommendation CTR模型中,对于历史点击视频通过计算sum/avg pooling的方式将定长的向量输入到模型中,这种方式无法很多信息的丢失,例如无法捕获到局部行为的重要信息,而本paper中的DIN模型也很好的解决了这个问题。其他模型还包括PNN、DeepFM,NMT网络也是paper重点提到的模型,也算是本apper种的局部激活模块的思想来源,即注意力机制的权重加和。
3.要解决问题的背景
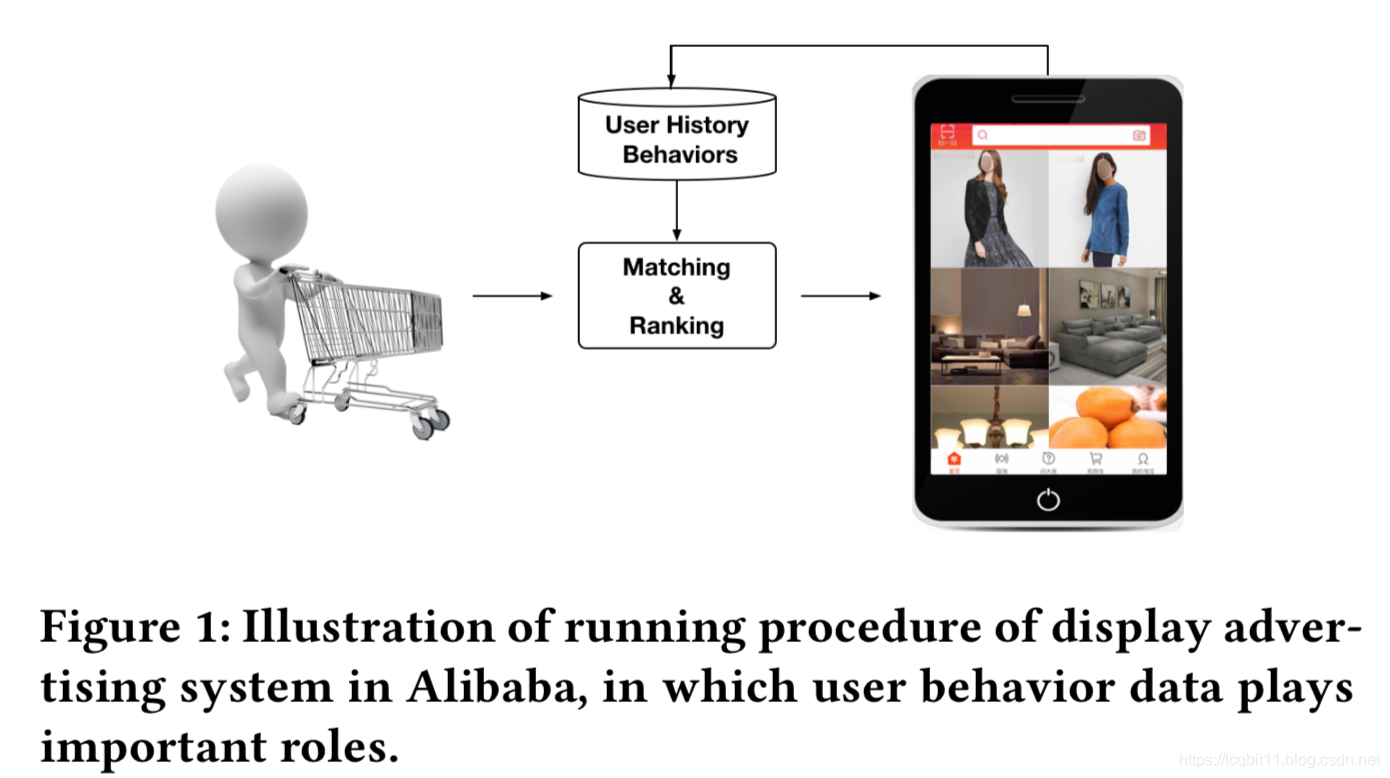
paper中提到的ads都是goods,阿里巴巴的展示广告系统分为match和ranking两个阶段,用户每天在网站上留下了丰富的行为数据,这些数据用在匹配模型和排序模型中发挥了很大的作用。一个比较值得注意的是,用户丰富的行为中包含了多种多样的兴趣爱好,paper中举了一个很容易理解的例子,一位妈妈历史浏览过羊绒大衣、耳环、T恤、宝宝外套等,而当她浏览网站时,系统只给她展示一个新款手提包的话,这对于她的多种兴趣而言,只展示一小部分她感兴趣的商品,比较有局限性。上面的bad case总结起来就是:一个具有丰富行为的用户,其兴趣爱好可能是多种多样的,而且每种兴趣是可以通过特定的广告去激活的(用户的兴趣可能很多,而一种广告只能激活其中一种兴趣或者少部分兴趣,所以兴趣是进行局部激活的)。
4.DIN
展示广告与搜索广告在点击率预估上的不同之处在于,展示广告无法感知用户明显的意图,因此从用户丰富的历史行为数据中挖掘出有效的特征至关重要,因此这部分paper首先介绍了DIN中的特征表达部分,然后是基模型,最后是对DIN模型的介绍。
4.1 特征表达
由于是深度网络,DIN网络的输入中不包含任何交叉特征,只通过深度网络模型来做交叉。
工业界CTR预估的数据集大多数是以多个离散(类别型)特征存在的。对于离散特征,paper中主要列出了one-hot和multi-hot这两种。
特征i的维度为K_i,即特征i包含K_i个不同的ids取值,对特征i进行编码之后的向量为t_i,如公式1,而t_i[j]表示t_i的第j个元素,且t_i[j]的取值范围为{0,1}。公式2中当k=1时,向量t_i表示one-hot编码,当k>1时,向量t_i表示multi-hot编码。
t i ∈ R K i ( 1 ) t_i \in R^{K_i} \qquad (1) ti∈RKi(1)
∑ j = 1 K i t i [ j ] = k ( 2 ) \sum_{j=1}^{K_i}t_i[j]=k \qquad (2) j=1∑Kiti[j]=k(2)
一个具体的例子是,特征x以多个特征群的形式表示,如公式3所示,公式中的M表示特征群的数量。公式4中的K表示全部特征空间的维度。
[ t 1 T , t 2 T , . . . t M T ] T ( 3 ) [t_1^T, t_2^T,...t_M^T]^T \qquad (3) [t1T,t2T,...tMT]T(3)
∑ i = 1 M K i = K ( 4 ) \sum_{i=1}^{M}K_i=K \qquad (4) i=1∑MKi=K(4)
对于工业实际中,对于包含4类特征的特征群[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book]来说,其对应的编码如公式5所示。
[ 0 , 0 , 0 , 0 , 1 , 0 , 0 ] ⏟ w e e k d a y = F r i d a y , [ 0 , 1 ] ⏟ g e n d e r = F e m a l e , [ 0 , … , 1 , … , 1 , … , 0 ] ⏟ v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3426
3426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









