






简评一下《PinnerFormer-Sequence Modeling for User Representation at Pinterest》这篇文章。Pinterest的文章,来自一线的实战经验多,干货满满,我基本上每篇必读。这篇文章也属于我之前总结过的用户长序列“离线建模”的思路
将用户的长历史压缩成一个向量,表示long-term user embedding
物料侧,让用户近期交互过的item,作为positive item embedding
将long-term user embedding与recent item embedding作为双塔的两端,再加一些negative sampled item,用双塔训练
训练完成之后,long-term user embedding离线生成并缓存起来,作为一路“基于用户长历史”的召回。因为用户长历史是已然发生的,变化不频繁,因此天级更新足矣。
这篇文章没有脱离我以上所说的大框架,基本思路都是遵循“拿用户长历史预测用户近期历史”。唯一不同的地方就是,原来在我描述的框架中,user embedding只有一个,而PinnerFormer是多个。
具体来说,先看结构图。
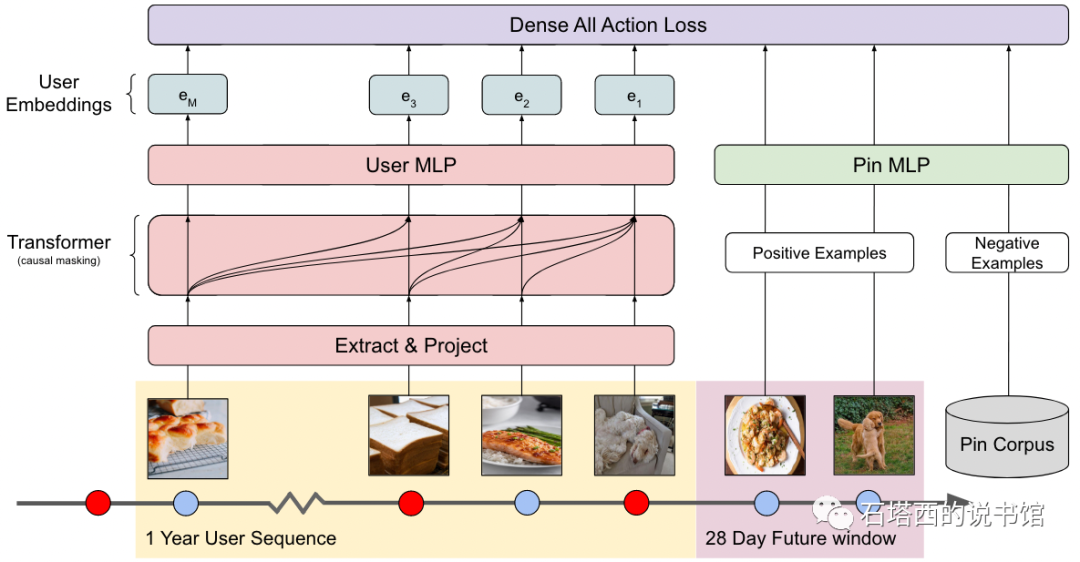
用户侧就是transformer。transformer的特点就是喂入用户长期历史中的M个historical item,那输出的也是M个embedding,而不是只有一个embedding。看到这里,我一开始的问题是,既然输出M个embedding,那么哪个表示user embedding?后续读下来才知道,PinnerForm的答案是:都是:-c
物料侧就是用户近期交互过的若干item,作为正样本。原始输入特征是用GNN训练出来的embedding。我发现pinterest很喜欢用GNN训练出来的embedding作为其他模型的输入。这一点和国内大厂的实践很不同,国内大厂不太喜欢让底层模型的输出作为上层模型的输入(只是一般情况,比如SIM就除外),原因是多个系统之间的版本管理、维护很麻烦,还不如自己单独end-to-end把自己想要的训练出来。
注意上面的Dense All Action Loss。一开始我读的时候,以为这是一个模块,接受用户一年的long historical item和最近28天的short historical item当输入,心想这个模块的接入层也太大了。后来才知道,这个dense all action loss是说可以接受这些long / short historical item任意组成的pair输入,而非同时输入。而且dense all action loss其实也不是什么模块,就是一个dot product后再计算loss。
架构上平平无奇的,那么还回到老问题,user侧喂入M个长期历史,transformer也输出M个长期历史,拿哪个表示user embedding?有好多作法。
按我之前的作法,transformer之后没完,还需要将这M个embedding压缩成一个embedding,比如average pooling也行,或者拿一些user attribute当query对所有M个embedding做target attention也行。
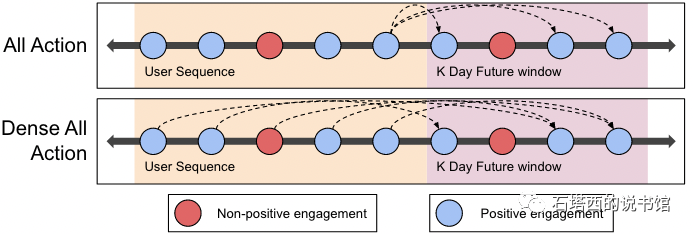
pinterest列举的一种作法是all action loss,如上图中第1行所示。就是拿这M个item embedding的最后一个当成user embedding,预测所有short term historical item。如果short term history太长,需要采样。
另一种就是pinterest在这一篇中的创新,dense all action loss,就是所有M个long historical item embedding都能是user embedding,要预测的对手方也是所有short historical item。拿M个long historical item embedding与short historical item两两组合,再抽样一些,就是正样本。
pinnerform宣称dense all action loss的特点:
在all action loss中,只用final long-term historical item embedding当user embedding,让它对所有short term history负责。这样一来final long-term historical item embedding要对所有short-term history负责,结果所有short-term history的loss都压到用户侧一个embedding上效果会有所平均。
现在相当于让其他long-term historical item替final分担压力,也有锻炼它们的意思,不能只让前边这些long-term historical item摸鱼。为了进一步防止前边的long-term item摸鱼,还在transformer做self-attention的时候增加了mask,让sequence中的item只能attend它前边的item,而不能偷看后面的。
疑问:以上所说的让除final之外的其他item embedding也当成user embedding与short-term item组成pair计算loss,但那是train,在predict的时候,毕竟还只能有一个user embedding,而非一堆。PinnerFormer的作法是,还是只拿final long-term historical item embedding当user embedding?既然如此,那么训练的时候,费心将之前的那些long-term historical item embedding训练好有用吗?
剩下的内容就平平无奇了。
负样本策略就是传统套路,但是套路中的细节没有讲,不好评判。
最好做的就是batch内负采样。每个example只有positive item,它拿同一个batch的其他example的positive item当negative item。好处是这些item embedding在被当成正样本时已经计算好了,被当成负样本时就不用重复计算了。坏处就是有二,一是热门物料做负样本的机会被放大了,导致热门物料被过分打压;二是热门物料当负样本都是hard negative,缺少easy negative。
所以再从大库中uniform sample一些当easy negative
仿效google作法,将uniformly sampled easy negative与in-batch sampled hard negative混合。
其实这种方法说起来简单,做起来都是细节,没那么简单。in-batch negative sampling效果不好,但是做起来简单,热门物料被过分打压的问题,加一些修正就好(怎么修正,看我的推荐算法书)。easy negative的uniform sampling不好做,因为训练的时候,模型是在变化中的,缓存那些easy negative item embedding没有意义。另外一些时间敏感特征的穿越问题也很不好处理,如果item feature使用了后验ctr之类的特征,那么我很难保证sample到的那个negative item的CTR与positive item的CTR是一个时间段上的。(其实细心的读者会发现,如果使用了时间敏感特征,即使in-batch negative sampling也会有期限错配的问题,但是因为in-batch在流式训练时基本来自range较小的同一个时间段,这个问题不严重被忽略不计了。)
再接下来的serving也没啥可说的。
天级更新即可,不像SIM那种需要在线持续训练,而且只有那些最近有了新动作的user的long-term user embedding需要更新。
拿最后一个long-term historical item embedding当成user embedding,代表用户长期兴趣,当成一路新召回。
Assuming the training dataset ends at time 𝑡, we compute embeddings at time 𝑡 for all users in the evaluation set, and then measure how well the embedding at time 𝑡 retrieves all Pins a user will engage with from time 𝑡 to 𝑡 + 14𝑑 from an index of 1M random Pins.一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 7139
7139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









