






后台留言『交流』,加入 NewBee讨论组
长久以来,推荐任务被视为判别式任务(Learning to Classify):给定用户的交互历史,基于判别式的传统推荐模型通过优化正样本(观察到的用户交互)和负样本(通常通过负采样得到)的判别边界,来实现推荐模型的训练。
然而,基于判别式的传统推荐系统存在天然的弊端:负样本在实际推荐场景中难以观测,大多通过人为的负采样策略来得到,难以保证负样本的真实性。此外,基于判别式的推荐系统只能在已知的候选物品集内进行判别,对用户的兴趣造成了极大的局限。以上弊端,在基于判别式的传统推荐框架下是难以逾越的。
近日,来自中国科学技术大学,以及香港理工大学的研究团队,打破了传统推荐系统拘于判别式框架的桎梏,利用条件扩散模型(Guided Diffusion),在生成式框架下(Learning to Generate)重塑序列化推荐,提出DreamRec推荐框架,将推荐任务定义为用户理想物品(Oracel Item)的生成任务,向我们展示了生成式推荐系统的巨大潜力。
该论文发表于NeurIPS 2023:
论文地址:https://arxiv.org/pdf/2310.20453.pdf
项目主页:https://github.com/YangZhengyi98/DreamRec
研究动机
序列推荐一直以来被认为是判别式任务:在训练过程中,给定用户历史交互序列,和用户接下来要交互的物品(正样本),推荐模型首先进行负采样得到负样本,然后通过优化正负样本的判别边界来进行训练。总之,基于判别式的推荐模型基本目的是判断候选集中的物品是正样本还是负样本。
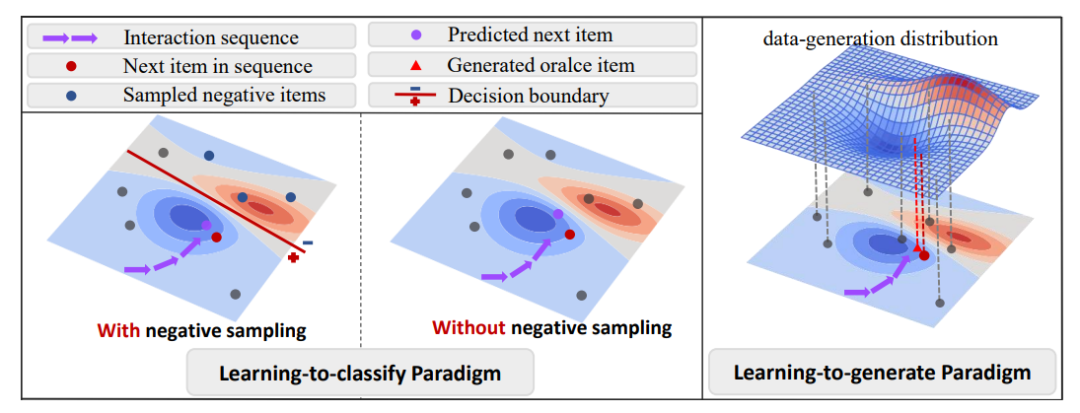
尽管判别式推荐模型已经统治推荐系统很多年,其中有两个问题难以解决:
(1)过于简化用户行为 —— 用户在与推荐系统交互后,会在脑海中自然形成理想物品(Oracle Item),然后在推荐列表中挑选和理想物品最匹配的进行交互。此理想物品是用户在交互后自然形成的,准确反映了用户兴趣,很难存在于候选物品集中。
(2)基于判别式的推荐模型只能用于区分观测到的正样本与采样得到的负样本,无法对理想物品进行准确建模。
为解决上述问题,我们必须建模理想物品的生成过程,这是判别式框架无法做到的。因此,我们提出DreamRec,将推荐任务重塑为理想物品的生成任务,并利用条件扩散模型,直接建模理想物品生成过程。
DreamRec刻画已观测交互数据的潜在生成分布,完全摆脱负样本,这是传统推荐模型难以做到的。此外,DreamRec完全基于生成式框架,不再局限于已知候选物品集。
DreamRec方法
给定用户历史交互的物品序列,通常每个物品都会转化为对应的向量表示:
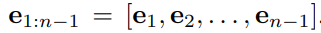
在DreamRec中,将理想物品的生成分布建模为:

注意此分布并非给定交互序列后,预测对候选集种物品推荐的概率分布,这是基于判别式推荐系统的常见建模方式。此分布描绘了给定交互序列后,生成理想物品需要服从的分布。如果此分布可以准确建模,那么我们将可以从中直接采样出理想物品。在DreamRec中,此分布通过条件扩散模型进行学习。
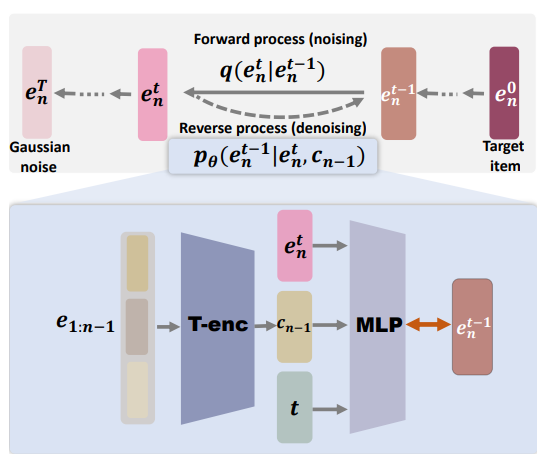
DreamRec训练过程
首先将历史交互序列通过Transformer encoder进行编码:
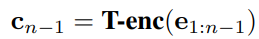
在DreamRec中,去噪过程(逆向过程)可以建模为:
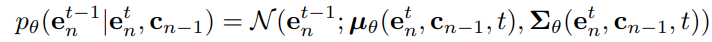
前向加噪过程是基于高斯核的马尔可夫过程:
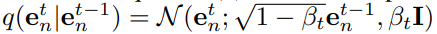
Dream的优化函数是学习去噪过程,通过前向与逆向过程的匹配实现:

利用重参数化技巧:
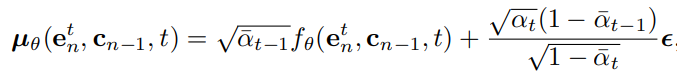
优化函数将转化为:
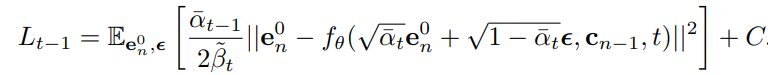
从优化函数中可以看出,DreamRec的训练过程关注在从噪声样本中恢复真实样本,完全不需要负样本参与,这是判别式推荐系统无法做到的。
在DreamRec训练过程中,我们采用Classifier-free Guidance策略,实现条件扩散模型与非条件扩散模型的同时训练。,从而实现条件扩散模型与非条件扩散模型的同时训练(Classifier-free Guidance)。
DreamRec采样过程
为了调节条件信号的强度,DreamRec在采样过程中会进行如下改动:
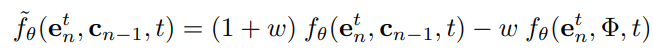
采样过程的一步去噪过程可以表示为:
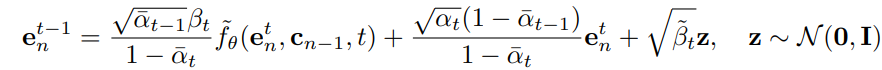
为了生成理想物品,我们首先采样一个高斯噪声, 然后通过以上公式进行步去噪,即可生成理想物品。
实验结果
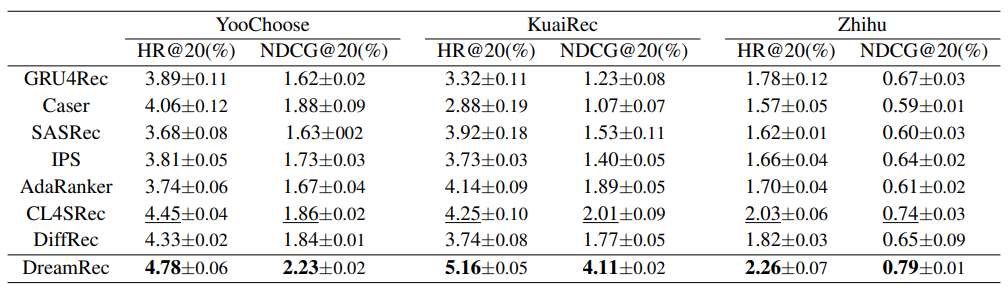
我们在三个真实数据集下,与代表性的序列推荐方法进行对比,展示了DreamRec优秀的推荐性能。值得注意的是,DreamRec作为生成式推荐模型,完全不依赖负采样,而其余序列推荐模型均为判别式,对负采样具有极强的依赖。
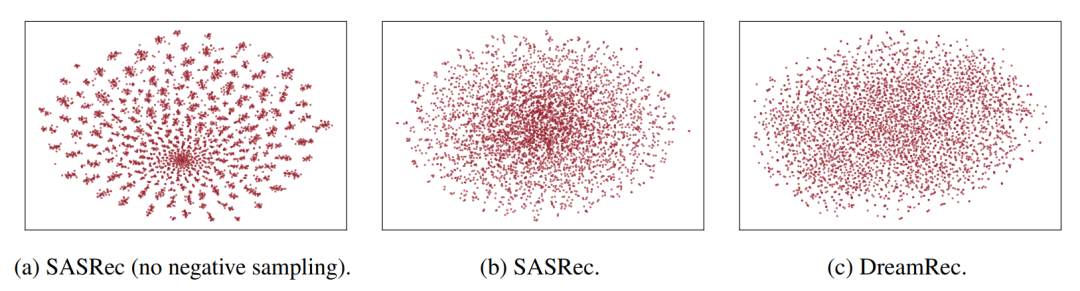
下面是用T-SNE对不同模型的物品向量表示进行降维可视化的结果。可以看出SASRec如果不进行负采样,学到的物品将难以区分;SASRec进行负采样后,可以更好的区分不同物品,但在中心区域仍有难以区分的物品。而DreamRec在不依赖负采样的情况下,对物品空间进行了更加全面的探索。
总结与展望
DreamRec利用条件扩散模型,首次提出将序列推荐任务重塑为理想物品的生成任务,打破了长久以来将推荐视为判别式的范式,完全抛弃负采样,这是传统推荐模型难以做到的。
但值得一提的是,DreamRec生成的是理想物品的隐向量表示,并未将理想物品显式表示出来。基于此我们提出RecInterpreter,成功通过大语言模型获得了理想物品的自然语言描述,全方位实现了DreamRec的生成式推荐新范式。
参考内容:https://arxiv.org/pdf/2310.20453.pdf
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









