






Hadoop安装和启动
-
执行hadoop namenode –format格式化hadoop
-
执行start-all.sh启动hadoop
-
执行jps显示当前所有java进程
| 2642 DataNode 3386 Jps 2538 NameNode 2860 JobTracker 2769 SecondaryNameNode 2982 TaskTracker |
-
在linux的浏览器中
通过hadoop:50070查看namenode是否运行成功
通过hadoop:50060查看tasktracker是否运行成功
通过hadoop:50030查看jobtracker是否运行成功
Hadoop源码
如果在eclipse的工程中出现” The method ***** of type AuthenticationFilter must override a superclass method”的错误,进行如下设置:
在eclipse里,Windows->Preferences->Java->Compiler “configure project specific settings”, Change from java 1.5 (5.0) to 1.6 (6.0) and then “yes” rebuild project。
HDFS的shell操作
hadoop fs –ls / 查看hdfs的根目录下的内容
hadoop fs –lsr / 递归查看hdfs的根目录下的内容
hadoop fs –mkdir /d1 在hdfs上创建文件夹d1
hadoop fs –put <linux source> <hdfs destination> 把数据从linux上传到hdfs的特定目录
hadoop fs -get <hdfs source> <linux destiontion> 把数据从hdfs下载到linux的特定路径
hadoop fs –text <hdfs文件> 查看hdfs的文件
hadoop fs –rm 删除hdfs中的文件
hadoop fs –rmr 删除文件夹
hadoop fs -touchz <hdfs文件> 创建一个0字节的空文件。
hadoop fs -text <src> 将源文件输出为文本格式。
使用java操作HDFS
文件上传/下载/删除
| import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.InputStream; import java.net.URI; import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory; import org.apache.hadoop.io.IOUtils;
public class FileOperator { // hadoop上的文件路径 public static final String HDFS_PATH = "hdfs://192.168.1.104:9000"; public static void OutputFile(String path) throws Exception { // TODO Auto-generated method stub URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); final URL url = new URL(HDFS_PATH + path); final InputStream in = url.openStream(); IOUtils.copyBytes(in, System.out, 1024, true); }
public static void main(String[] args) throws Exception { final FileSystem fileSystem = FileSystem.get(new URI(HDFS_PATH), new Configuration()); //创建文件夹 fileSystem.mkdirs(new Path("/dir2")); //创建文件 final FSDataOutputStream out = fileSystem.create(new Path("/dir2/file")); //上传文件 final FileInputStream in = new FileInputStream("C:/log.txt"); IOUtils.copyBytes(in, out, 1024, true); OutputFile("/dir2/file"); //下载文件 final FSDataInputStream input = fileSystem.open(new Path(HDFS_PATH + "/dir2/file")); final FileOutputStream output = new FileOutputStream("C:/file.txt"); IOUtils.copyBytes(input, output, 1024, true); //删除文件 final boolean deleteFile = fileSystem.deleteOnExit(new Path("/dir2/file")); } } |
RPC通信
简介
1、RPC是一种CS调用模式,用于不同java进程之间的方法调用, 不同java进程间的对象方法的调用。一方称作服务端(server),一方称作客户端(client)。 server端提供对象,供客户端调用的,被调用的对象的方法的执行发生在server端。
2、RPC是hadoop框架运行的基础,hadoop是建立在RPC基础之上。
3、RPC源码在org.apache.hadoop.ipc中。
4、Hadoop RPC在整个Hadoop中应用非常广泛,Client、DataNode、NameNode之间的通讯全靠它了。
5、举个例子,我们平时操作HDFS的时候,使用的是FileSystem类,它的内部有个DFSClient对象,这个对象负责与NameNode打交道。在运行时,DFSClient在本地创建一个NameNode的代理,然后就操作这个代理,这个代理就会通过网络,远程调用到NameNode的方法,也能返回值。
服务端:
| public class MyServer { public static final String SERVER_ADDRESS = "hdfs://192.168.1.104"; public static final int SERVER_PORT = 9000; /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { // 构造一个RPC server,第一个参数是被客户端调用的对象实例,第二个参数是用于监听连接的地址 final Server server = RPC.getServer(new MyBiz(), SERVER_ADDRESS, SERVER_PORT, new Configuration()); server.start(); } } |
客户端:
| public class MyClient {
/** * @param args * @throws IOException */ public static void main(String[] args) throws IOException {
//构造一个客户端的代理对象,该对象实现指定的协议,通过该对象可以和指定地址的server通信 //这里的返回值必须是实现了VersionedProtocol的接口 //也可以通过getProxy获得代理对象 final MyBizable proxy = (MyBizable) RPC.waitForProxy(MyBizable.class, MyBizable.VERSION, new InetSocketAddress(MyServer.SERVER_ADDRESS, MyServer.SERVER_PORT), new Configuration()); final String result = proxy.hello("wanjun"); System.out.println("客户端调用结果:" + result); RPC.stopProxy(proxy); }
} |
客户端通过代理对象要访问的服务端方法
| import org.apache.hadoop.ipc.VersionedProtocol;
public interface MyBizable extends VersionedProtocol{ public static final long VERSION = 4324523423L; public String hello(String name); }
public class MyBiz implements MyBizable{ public String hello(String name) { return name; }
@Override public long getProtocolVersion(String protocol, long clientVersion) throws IOException { // TODO Auto-generated method stub return VERSION; } }
|
HDFS文件读写流程
-
写文件流程
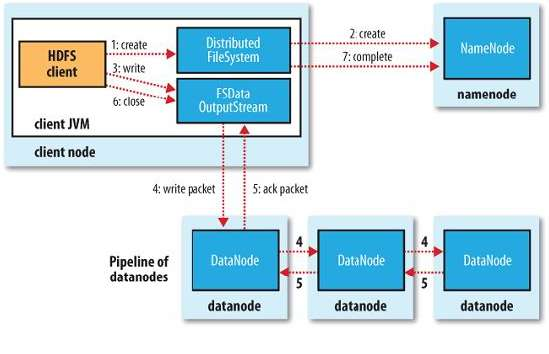
客户端
上传一个文件到hdfs,一般会调用DistributedFileSystem.create,其实现如下:
public FSDataOutputStream create(Path f, FsPermission permission,
boolean overwrite,
int bufferSize, short replication, long blockSize,
Progressable progress) throws IOException {
return new FSDataOutputStream
(dfs.create(getPathName(f), permission,
overwrite, replication, blockSize, progress, bufferSize),
statistics);
}
其最终生成一个FSDataOutputStream用于向新生成的文件中写入数据。其成员变量dfs的类型为DFSClient,DFSClient的create函数如下:
public OutputStream create(String src,
FsPermission permission,
boolean overwrite,
short replication,
long blockSize,
Progressable progress,
int buffersize
) throws IOException {
checkOpen();
if (permission == null) {
permission = FsPermission.getDefault();
}
FsPermission masked = permission.applyUMask(FsPermission.getUMask(conf));
OutputStream result = new DFSOutputStream(src, masked,
overwrite, replication, blockSize, progress, buffersize,
conf.getInt("io.bytes.per.checksum", 512));
leasechecker.put(src, result);
return result;
}
其中构造了一个DFSOutputStream,在其构造函数中,通过RPC(参见NameNode.java中的initialize方法中的RPC.getServer和DFSClient.java中的createRPCNamenode方法中的RPC.getProxy)调用NameNode的create来创建一个文件。 当然,构造函数中还做了一件重要的事情,就是streamer.start(),也即启动了一个pipeline,用于写数据,在写入数据的过程中,我们会仔细分析。
DFSOutputStream(String src, FsPermission masked, boolean overwrite,
short replication, long blockSize, Progressable progress,
int buffersize, int bytesPerChecksum) throws IOException {
this(src, blockSize, progress, bytesPerChecksum);
computePacketChunkSize(writePacketSize, bytesPerChecksum);
try {
namenode.create(
src, masked, clientName, overwrite, replication, blockSize);
} catch(RemoteException re) {
throw re.unwrapRemoteException(AccessControlException.class,
QuotaExceededException.class);
}
streamer.start();
}
5.2、NameNode
NameNode的create函数调用namesystem.startFile函数,其又调用startFileInternal函数,实现如下:
private synchronized void startFileInternal(String src,
PermissionStatus permissions,
String holder,
String clientMachine,
boolean overwrite,
boolean append,
short replication,
long blockSize
) throws IOException {
......
//创建一个新的文件,状态为under construction,没有任何data block与之对应
long genstamp = nextGenerationStamp();
INodeFileUnderConstruction newNode = dir.addFile(src, permissions,
replication, blockSize, holder, clientMachine, clientNode, genstamp);
......
}
5.3、客户端
下面轮到客户端向新创建的文件中写入数据了,一般会使用FSDataOutputStream的write函数,最终会调用DFSOutputStream的writeChunk函数:
按照hdfs的设计,对block的数据写入使用的是pipeline的方式,也即将数据分成一个个的package,如果需要复制三份,分别写入DataNode 1, 2, 3,则会进行如下的过程:
首先将package 1写入DataNode 1
然后由DataNode 1负责将package 1写入DataNode 2,同时客户端可以将pacage 2写入DataNode 1
然后DataNode 2负责将package 1写入DataNode 3, 同时客户端可以讲package 3写入DataNode 1,DataNode 1将package 2写入DataNode 2
就这样将一个个package排着队的传递下去,直到所有的数据全部写入并复制完毕
protected synchronized void writeChunk(byte[] b, int offset, int len, byte[] checksum) throws IOException {
//创建一个package,并写入数据
currentPacket = new Packet(packetSize, chunksPerPacket,
bytesCurBlock);
currentPacket.writeChecksum(checksum, 0, cklen);
currentPacket.writeData(b, offset, len);
currentPacket.numChunks++;
bytesCurBlock += len;
//如果此package已满,则放入队列中准备发送
if (currentPacket.numChunks == currentPacket.maxChunks ||
bytesCurBlock == blockSize) {
......
dataQueue.addLast(currentPacket);
//唤醒等待dataqueue的传输线程,也即DataStreamer
dataQueue.notifyAll();
currentPacket = null;
......
}
}
DataStreamer的run函数如下:
public void run() {
while (!closed && clientRunning) {
Packet one = null;
synchronized (dataQueue) {
//如果队列中没有package,则等待
while ((!closed && !hasError && clientRunning
&& dataQueue.size() == 0) || doSleep) {
try {
dataQueue.wait(1000);
} catch (InterruptedException e) {
}
doSleep = false;
}
try {
//得到队列中的第一个package
one = dataQueue.getFirst();
long offsetInBlock = one.offsetInBlock;
//由NameNode分配block,并生成一个写入流指向此block
if (blockStream == null) {
nodes = nextBlockOutputStream(src);
response = new ResponseProcessor(nodes);
response.start();
}
ByteBuffer buf = one.getBuffer();
//将package从dataQueue移至ackQueue,等待确认
dataQueue.removeFirst();
dataQueue.notifyAll();
synchronized (ackQueue) {
ackQueue.addLast(one);
ackQueue.notifyAll();
}
//利用生成的写入流将数据写入DataNode中的block
blockStream.write(buf.array(), buf.position(), buf.remaining());
if (one.lastPacketInBlock) {
blockStream.writeInt(0); //表示此block写入完毕
}
blockStream.flush();
} catch (Throwable e) {
}
}
......
}
其中重要的一个函数是nextBlockOutputStream,实现如下:
private DatanodeInfo[] nextBlockOutputStream(String client) throws IOException {
LocatedBlock lb = null;
boolean retry = false;
DatanodeInfo[] nodes;
int count = conf.getInt("dfs.client.block.write.retries", 3);
boolean success;
do {
......
//由NameNode为文件分配DataNode和block
lb = locateFollowingBlock(startTime);
block = lb.getBlock();
nodes = lb.getLocations();
//创建向DataNode的写入流
success = createBlockOutputStream(nodes, clientName, false);
......
} while (retry && --count >= 0);
return nodes;
}
locateFollowingBlock中通过RPC调用namenode.addBlock(src, clientName)函数
5.4、NameNode
NameNode的addBlock函数实现如下:
public LocatedBlock addBlock(String src,
String clientName) throws IOException {
LocatedBlock locatedBlock = namesystem.getAdditionalBlock(src, clientName);
return locatedBlock;
}
FSNamesystem的getAdditionalBlock实现如下:
public LocatedBlock getAdditionalBlock(String src,
String clientName
) throws IOException {
long fileLength, blockSize;
int replication;
DatanodeDescriptor clientNode = null;
Block newBlock = null;
......
//为新的block选择DataNode
DatanodeDescriptor targets[] = replicator.chooseTarget(replication,
clientNode,
null,
blockSize);
......
//得到文件路径中所有path的INode,其中最后一个是新添加的文件对的INode,状态为under construction
INode[] pathINodes = dir.getExistingPathINodes(src);
int inodesLen = pathINodes.length;
INodeFileUnderConstruction pendingFile = (INodeFileUnderConstruction)
pathINodes[inodesLen - 1];
//为文件分配block, 并设置在那写DataNode上
newBlock = allocateBlock(src, pathINodes);
pendingFile.setTargets(targets);
......
return new LocatedBlock(newBlock, targets, fileLength);
}
5.5、客户端
在分配了DataNode和block以后,createBlockOutputStream开始写入数据。
private boolean createBlockOutputStream(DatanodeInfo[] nodes, String client,
boolean recoveryFlag) {
//创建一个socket,链接DataNode
InetSocketAddress target = NetUtils.createSocketAddr(nodes[0].getName());
s = socketFactory.createSocket();
int timeoutValue = 3000 * nodes.length + socketTimeout;
s.connect(target, timeoutValue);
s.setSoTimeout(timeoutValue);
s.setSendBufferSize(DEFAULT_DATA_SOCKET_SIZE);
long writeTimeout = HdfsConstants.WRITE_TIMEOUT_EXTENSION * nodes.length +
datanodeWriteTimeout;
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(NetUtils.getOutputStream(s, writeTimeout),
DataNode.SMALL_BUFFER_SIZE));
blockReplyStream = new DataInputStream(NetUtils.getInputStream(s));
//写入指令
out.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
out.write( DataTransferProtocol.OP_WRITE_BLOCK );
out.writeLong( block.getBlockId() );
out.writeLong( block.getGenerationStamp() );
out.writeInt( nodes.length );
out.writeBoolean( recoveryFlag );
Text.writeString( out, client );
out.writeBoolean(false);
out.writeInt( nodes.length - 1 );
//注意,次循环从1开始,而非从0开始。将除了第一个DataNode以外的另外两个DataNode的信息发送给第一个DataNode, 第一个DataNode可以根据此信息将数据写给另两个DataNode
for (int i = 1; i < nodes.length; i++) {
nodes[i].write(out);
}
checksum.writeHeader( out );
out.flush();
firstBadLink = Text.readString(blockReplyStream);
if (firstBadLink.length() != 0) {
throw new IOException("Bad connect ack with firstBadLink " + firstBadLink);
}
blockStream = out;
}
客户端在DataStreamer的run函数中创建了写入流后,调用blockStream.write将数据写入DataNode
5.6、DataNode
DataNode的DataXceiver中,收到指令DataTransferProtocol.OP_WRITE_BLOCK则调用writeBlock函数:
private void writeBlock(DataInputStream in) throws IOException {
DatanodeInfo srcDataNode = null;
//读入头信息
Block block = new Block(in.readLong(),
dataXceiverServer.estimateBlockSize, in.readLong());
int pipelineSize = in.readInt(); // num of datanodes in entire pipeline
boolean isRecovery = in.readBoolean(); // is this part of recovery?
String client = Text.readString(in); // working on behalf of this client
boolean hasSrcDataNode = in.readBoolean(); // is src node info present
if (hasSrcDataNode) {
srcDataNode = new DatanodeInfo();
srcDataNode.readFields(in);
}
int numTargets = in.readInt();
if (numTargets < 0) {
throw new IOException("Mislabelled incoming datastream.");
}
//读入剩下的DataNode列表,如果当前是第一个DataNode,则此列表中收到的是第二个,第三个DataNode的信息,如果当前是第二个DataNode,则受到的是第三个DataNode的信息
DatanodeInfo targets[] = new DatanodeInfo[numTargets];
for (int i = 0; i < targets.length; i++) {
DatanodeInfo tmp = new DatanodeInfo();
tmp.readFields(in);
targets[i] = tmp;
}
DataOutputStream mirrorOut = null; // stream to next target
DataInputStream mirrorIn = null; // reply from next target
DataOutputStream replyOut = null; // stream to prev target
Socket mirrorSock = null; // socket to next target
BlockReceiver blockReceiver = null; // responsible for data handling
String mirrorNode = null; // the name:port of next target
String firstBadLink = ""; // first datanode that failed in connection setup
try {
//生成一个BlockReceiver, 其有成员变量DataInputStream in为从客户端或者上一个DataNode读取数据,还有成员变量DataOutputStream mirrorOut,用于向下一个DataNode写入数据,还有成员变量OutputStream out用于将数据写入本地。
blockReceiver = new BlockReceiver(block, in,
s.getRemoteSocketAddress().toString(),
s.getLocalSocketAddress().toString(),
isRecovery, client, srcDataNode, datanode);
// get a connection back to the previous target
replyOut = new DataOutputStream(
NetUtils.getOutputStream(s, datanode.socketWriteTimeout));
//如果当前不是最后一个DataNode,则同下一个DataNode建立socket连接
if (targets.length > 0) {
InetSocketAddress mirrorTarget = null;
// Connect to backup machine
mirrorNode = targets[0].getName();
mirrorTarget = NetUtils.createSocketAddr(mirrorNode);
mirrorSock = datanode.newSocket();
int timeoutValue = numTargets * datanode.socketTimeout;
int writeTimeout = datanode.socketWriteTimeout +
(HdfsConstants.WRITE_TIMEOUT_EXTENSION * numTargets);
mirrorSock.connect(mirrorTarget, timeoutValue);
mirrorSock.setSoTimeout(timeoutValue);
mirrorSock.setSendBufferSize(DEFAULT_DATA_SOCKET_SIZE);
//创建向下一个DataNode写入数据的流
mirrorOut = new DataOutputStream(
new BufferedOutputStream(
NetUtils.getOutputStream(mirrorSock, writeTimeout),
SMALL_BUFFER_SIZE));
mirrorIn = new DataInputStream(NetUtils.getInputStream(mirrorSock));
mirrorOut.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
mirrorOut.write( DataTransferProtocol.OP_WRITE_BLOCK );
mirrorOut.writeLong( block.getBlockId() );
mirrorOut.writeLong( block.getGenerationStamp() );
mirrorOut.writeInt( pipelineSize );
mirrorOut.writeBoolean( isRecovery );
Text.writeString( mirrorOut, client );
mirrorOut.writeBoolean(hasSrcDataNode);
if (hasSrcDataNode) { // pass src node information
srcDataNode.write(mirrorOut);
}
mirrorOut.writeInt( targets.length - 1 );
//此出也是从1开始,将除了下一个DataNode的其他DataNode信息发送给下一个DataNode
for ( int i = 1; i < targets.length; i++ ) {
targets[i].write( mirrorOut );
}
blockReceiver.writeChecksumHeader(mirrorOut);
mirrorOut.flush();
}
//使用BlockReceiver接受block
String mirrorAddr = (mirrorSock == null) ? null : mirrorNode;
blockReceiver.receiveBlock(mirrorOut, mirrorIn, replyOut,
mirrorAddr, null, targets.length);
......
} finally {
// close all opened streams
IOUtils.closeStream(mirrorOut);
IOUtils.closeStream(mirrorIn);
IOUtils.closeStream(replyOut);
IOUtils.closeSocket(mirrorSock);
IOUtils.closeStream(blockReceiver);
}
}
BlockReceiver的receiveBlock函数中,一段重要的逻辑如下:
void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, BlockTransferThrottler throttlerArg,
int numTargets) throws IOException {
......
//不断的接受package,直到结束
while (receivePacket() > 0) {}
if (mirrorOut != null) {
try {
mirrorOut.writeInt(0); // mark the end of the block
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
......
}
BlockReceiver的receivePacket函数如下:
private int receivePacket() throws IOException {
//从客户端或者上一个节点接收一个package
int payloadLen = readNextPacket();
buf.mark();
//read the header
buf.getInt(); // packet length
offsetInBlock = buf.getLong(); // get offset of packet in block
long seqno = buf.getLong(); // get seqno
boolean lastPacketInBlock = (buf.get() != 0);
int endOfHeader = buf.position();
buf.reset();
setBlockPosition(offsetInBlock);
//将package写入下一个DataNode
if (mirrorOut != null) {
try {
mirrorOut.write(buf.array(), buf.position(), buf.remaining());
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
buf.position(endOfHeader);
int len = buf.getInt();
offsetInBlock += len;
int checksumLen = ((len + bytesPerChecksum - 1)/bytesPerChecksum)*
checksumSize;
int checksumOff = buf.position();
int dataOff = checksumOff + checksumLen;
byte pktBuf[] = buf.array();
buf.position(buf.limit()); // move to the end of the data.
......
//将数据写入本地的block
out.write(pktBuf, dataOff, len);
/// flush entire packet before sending ack
flush();
// put in queue for pending acks
if (responder != null) {
((PacketResponder)responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
}
return payloadLen;
Hadoop实战
安装eclipse hadoop插件
Mapper、Reducer
-
map函数和reduce函数是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函 数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
-
map的输入默认是一行记录,每条记录都存放在value里面,map的输出是一条一条的key-value
实例
| //统计专利引用情况 public class PatentStat extends Configured implements Tool { // Mapper第一个参数的类型一定要和map的第一个参数类型一致,否则出错!!! public static class Map extends Mapper<LongWritable, Text, Text, Text> { // map方法把文件的行号当成key,所以要用LongWritable public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将输入的纯文本文件的数据转化成String String line = value.toString();
// 分别对每一行进行处理 // 每行按逗号分割 /* * 第一种分割方法:使用Tokenizer StringTokenizer tokenizerLine = new * StringTokenizer(line, ","); String citing = * tokenizerLine.nextToken().trim(); String cited = * tokenizerLine.nextToken().trim(); Text citingText = new * Text(citing); Text citedText = new Text(cited); context.write(new * Text(citedText), new Text(citingText)); */ // 第二种方法:使用split String[] citing = line.split(","); context.write(new Text(citing[1]), new Text(citing[0])); } }
// reduce将输入中的key复制到输出数据的key上, // 然后根据输入的value-list中元素的个数决定key的输出次数 // 用全局linenum来代表key的位次 public static class Reduce extends Reducer<Text, Text, Text, Text> { // 实现reduce函数 public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String csv = ""; for (Text value : values) { if (csv.length() > 0) { csv += ","; } csv += value.toString(); } context.write(key, new Text(csv)); } }
@Override public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration(); Job job = new Job(conf, "Patent Statistic"); job.setJarByClass(PatentStat.class);
// 设置输入和输出目录 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class);
// 设置Map和Reduce处理类 job.setMapperClass(Map.class); job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
return 0; }
public static void main(String[] args) throws Exception {
// 这句话很关键 // conf.set("mapred.job.tracker", "192.168.1.2:9001"); if (args.length != 2) { System.err.println("Usage: PatentStat "); System.exit(2); } int res = ToolRunner.run(new Configuration(), new PatentStat(), args); } } |
通过脚本使用Streaming
mapper和reducer会从标准输入中读取用户数据,一行一行处理后发送给标准输出。Streaming工具会创建MapReduce作业,发送给各个tasktracker,同时监控整个作业的执行过程。
如果一个文件(可执行或者脚本)作为mapper,mapper初始化时,每一个mapper任务会把该文件作为一个单独进程启动,mapper任务运行时,它把输入切分成行并把每一行提供给可执行文件进程的标准输入。 同时,mapper收集可执行文件进程标准输出的内容,并把收到的每一行内容转化成key/value对,作为mapper的输出。 默认情况下,一行中第一个tab之前的部分作为key,之后的(不包括tab)作为value。如果没有tab,整行作为key值,value值为null。
对于reducer,类似。
Hadoop Streaming用法
Usage: $HADOOP_HOME/bin/hadoop jar
$HADOOP_HOME/contrib/streaming/hadoop-*-streaming.jar [options]
options:
(1)-input:输入文件路径
(2)-output:输出文件路径
(3)-mapper:用户自己写的mapper程序,可以是可执行文件或者脚本
(4)-reducer:用户自己写的reducer程序,可以是可执行文件或者脚本
(5)-file:打包文件到提交的作业中,可以是mapper或者reducer要用的输入文件,如配置文件,字典等。
(6)-partitioner:用户自定义的partitioner程序
(7)-combiner:用户自定义的combiner程序(必须用java实现)
(8)-D:作业的一些属性(以前用的是-jonconf)
实例:
Mapper.py
| #!/usr/bin/env python import sys # maps words to their counts word2count = {} # input comes from STDIN (standard input) for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # split the line into words while removing any empty strings words = filter(lambda word: word, line.split()) # increase counters for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py # # tab-delimited; the trivial word count is 1 print '%s\t%s' % (word, 1) |
Reducer.py
| #!/usr/bin/env python from operator import itemgetter import sys # maps words to their counts word2count = {} # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip()
# parse the input we got from mapper.py word, count = line.split() # convert count (currently a string) to int try: count = int(count) word2count[word] = word2count.get(word, 0) + count except ValueError: # count was not a number, so silently # ignore/discard this line pass
# sort the words lexigraphically; # # this step is NOT required, we just do it so that our # final output will look more like the official Hadoop # word count examples sorted_word2count = sorted(word2count.items(), key=itemgetter(0))
# write the results to STDOUT (standard output) for word, count in sorted_word2count: print '%s\t%s'% (word, count) |
运行:
[root@Hadoop streaming]# hadoop jar /usr/local/hadoop/contrib/streaming/hadoop-streaming-1.1.2.jar
-mapper /home/hadoop/streaming/mapper.py
-reducer /home/hadoop/streaming/reducer.py
-input /mapreduce/wordcount/input/*
-output /python-output
-jobconf mapred.reduce.tasks=1
注意:这里的input和output地址是相对服务器的地址
使用DataJoin包实现Join
| public class DataJoin extends Configured implements Tool { //mapper的主要功能就是打包一个record使其能够和其他拥有相同group key的记录去向一个Reducer,DataJoinMapperBase完成所有的打包工作. public static class MapClass extends DataJoinMapperBase { //这个在任务开始时调用,用于产生标签,此处就直接以文件名作为标签,标签最终被保存在inputTag中 protected Text generateInputTag(String inputFile) { //String datasource = inputFile.split("-")[0]; return new Text(inputFile); } //获取主键——用于表联结的字段 protected Text generateGroupKey(TaggedMapOutput aRecord) { String line = ((Text) aRecord.getData()).toString(); String[] tokens = line.split(","); String groupKey = tokens[0]; return new Text(groupKey); } //为map的输出打上标签 protected TaggedMapOutput generateTaggedMapOutput(Object value) { TaggedWritable retv = new TaggedWritable((Text) value); retv.setTag(this.inputTag); return retv; } }
//我们的子类只是实现combine方法用来筛选掉不需要的组合,获得所需的联结操作(内联结,左联结等)。并且将结果化为合适输出格式(如:字段排列,去重等) public static class Reduce extends DataJoinReducerBase { /*对于两个datasource的联结,tags的长度最长为2,values的长度=tags的长度 * for example: * tags:{"Customers", "Orders"} * values:{"3,Jose Madrize, 13344409898", "A-1, 13400.00, 2014-12-12"} */ protected TaggedMapOutput combine(Object[] tags, Object[] values) { if (tags.length < 2) return null; //这一步,实现内联结 String joinedStr = ""; for (int i=0; i<values.length; i++) { if (i > 0) joinedStr += ","; TaggedWritable tw = (TaggedWritable) values[i]; String line = ((Text) tw.getData()).toString(); String[] tokens = line.split(",", 2);//将一条记录划分两组,去掉第一组的组键名。 joinedStr += tokens[1]; } TaggedWritable retv = new TaggedWritable(new Text(joinedStr)); retv.setTag((Text) tags[0]); return retv; } }
//TaggedMapOutput是一个抽象数据类型,封装了标签与记录内容 //此处作为DataJoinMapperBase的输出值类型,需要实现Writable接口,所以要实现两个序列化方法 public static class TaggedWritable extends TaggedMapOutput {
private Writable data;
public TaggedWritable() { this.tag = new Text(""); this.data = new Text(""); }
public TaggedWritable(Writable data) { this.tag = new Text(""); this.data = data; }
public Writable getData() { return data; }
public void setData(Writable data) { this.data = data; }
public void write(DataOutput out) throws IOException { this.tag.write(out); this.data.write(out); }
public void readFields(DataInput in) throws IOException { this.tag.readFields(in); this.data.readFields(in); } }
public int run(String[] args) throws Exception { Configuration conf = new Configuration();
JobConf job = new JobConf(conf, DataJoin.class);
Path in = new Path(args[0]); Path out = new Path(args[1]); FileInputFormat.setInputPaths(job, in); FileOutputFormat.setOutputPath(job, out);
job.setJobName("DataJoin"); job.setMapperClass(MapClass.class); job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class); job.setOutputFormat(TextOutputFormat.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(TaggedWritable.class); job.set("mapred.textoutputformat.separator", ",");
JobClient.runJob(job); return 0; }
public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new DataJoin(), args);
System.exit(res); } } |















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









