






1、Redis 在项目中的使用场景
缓存(核心)、分布式锁(set + lua 脚本)、排行榜(zset)、计数(incrby)、消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)等。
2、Redis 常见的数据结构
基础的5种:
String:字符串,最基础的数据类型。
List:列表。
Hash:哈希对象。
Set:集合。
Sorted Set:有序集合,Set 的基础上加了个分值。
高级的4种:
HyperLogLog:通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有0.81%标准差(standard error)的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
Geo:redis 3.2 版本的新特性。可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作:获取2个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。
Bitmap:位图。
Stream:主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
3、Redis 事务的实现
一个事务从开始到结束通常会经历以下3个阶段:
1)事务开始:multi 命令将执行该命令的客户端从非事务状态切换至事务状态,底层通过 flags 属性标识。
2)命令入队:当客户端处于事务状态时,服务器会根据客户端发来的命令执行不同的操作:
exec、discard、watch、multi 命令会被立即执行
其他命令不会立即执行,而是将命令放入到一个事务队列,然后向客户端返回 QUEUED 回复。
3)事务执行:当一个处于事务状态的客户端向服务器发送 exec 命令时,服务器会遍历事务队列,执行队列中的所有命令,最后将结果全部返回给客户端。
不过 redis 的事务并不推荐在实际中使用,如果要使用事务,推荐使用 Lua 脚本,redis 会保证一个 Lua 脚本里的所有命令的原子性。
4、Redis 实现分布式锁
1)加锁
加锁通常使用 set 命令来实现,伪代码如下:
set key value PX milliseconds NX
几个参数的意义如下:
key、value:键值对
PX milliseconds:设置键的过期时间为 milliseconds 毫秒。
NX:只在键不存在时,才对键进行设置操作。SET key value NX 效果等同于 SETNX key value。
PX、expireTime 参数则是用于解决没有解锁导致的死锁问题。因为如果没有过期时间,万一程序员写的代码有 bug 导致没有解锁操作,则就出现了死锁,因此该参数起到了一个“兜底”的作用。
NX 参数:用于保证在多个线程并发 set 下,只会有1个线程成功,起到了锁的“唯一”性。
5、使用缓存时,先操作数据库 or 先操作缓存
1)先操作数据库
案例如下,有两个并发的请求,一个写请求,一个读请求,流程如下:
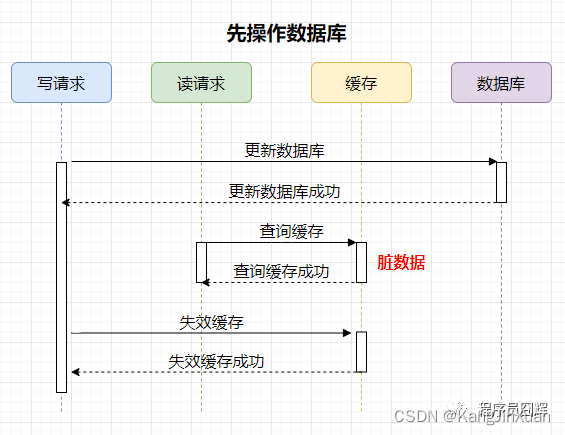
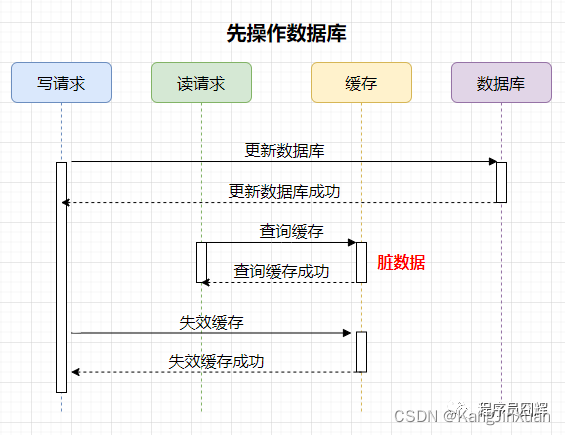
可能存在的脏数据时间范围:更新数据库后,失效缓存前。这个时间范围很小,通常不会超过几毫秒。
2)先操作缓存
案例如下,有两个并发的请求,一个写请求,一个读请求,流程如下:
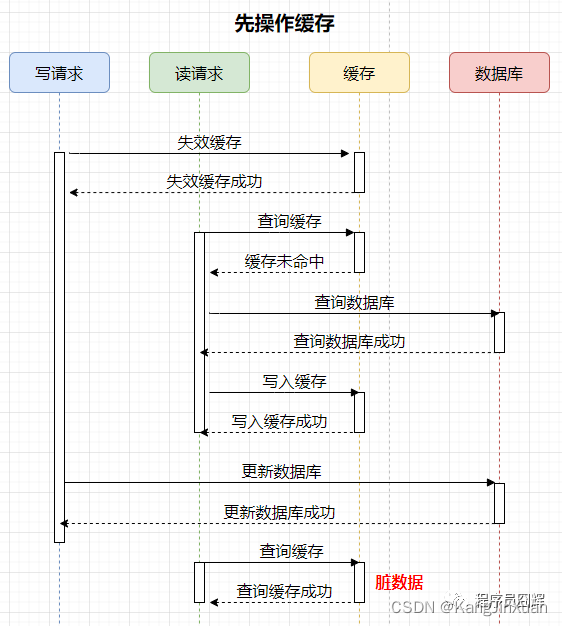
可能存在的脏数据时间范围:更新数据库后,下一次对该数据的更新前。这个时间范围不确定性很大,情况如下:
如果下一次对该数据的更新马上就到来,那么会失效缓存,脏数据的时间就很短。
如果下一次对该数据的更新要很久才到来,那这期间缓存保存的一直是脏数据,时间范围很长。
结论:通过上述案例可以看出,先操作数据库和先操作缓存都会存在脏数据的情况。但是相比之下,先操作数据库,再操作缓存是更优的方式,即使在并发极端情况下,也只会出现很小量的脏数据。
6、如何保证数据库和缓存的数据一致性
1)更新数据库,数据库产生 binlog。
2)监听和消费 binlog,执行失效缓存操作。
3)如果步骤2失效缓存失败,则引入重试机制,将失败的数据通过MQ方式进行重试,同时考虑是否需要引入幂等机制。
7、缓存穿透
描述:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用。
解决方案:
1)接口校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2)缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3)布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









