







MySQL体制结构
下图为MySQL体系结构:
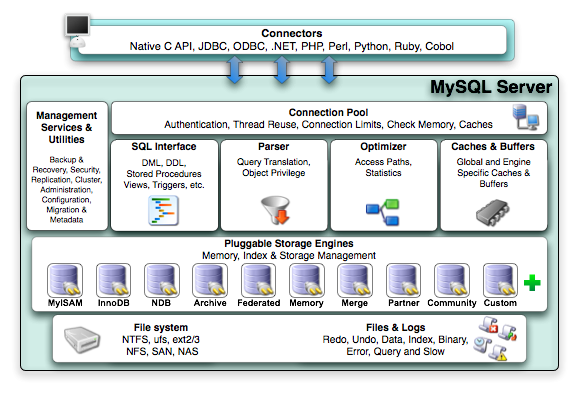
从上向下看:
从上向下看:
1、Connectors:客户端连接,使用SQL和数据库交互。可以是不同语言的客户端。
2、Management Services & Utilities:管理服务和工具组件。
3、Connection Pool:连接池组件。管理客户端的连接。
4、SQL Interface:SQL接口组件。接受客户端的SQL请求,并返回执行SQL语句的结果。
5、Parser:查询分析组件。负责解析和验证SQL语句。
6、Optimizer:优化器组件。对SQL语句进行优化,基于“选取-投影-联接”策略。
7、Caches & Buffers:缓冲组件。
8、Pluggable Storeage Engines:插件式存储引擎。这是MySQL特有的。
9、File System:物理文件。
10、Files & Logs:文件日志。
MySQL存储引擎
存储引擎介绍:
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。
这些不同的技术以及配套的相关功能在MySQL中被称作存储引擎(也称作表类型)。MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
参考:百度百科。
存储引擎有时承做表类型,每个表可以有自己的存储引擎,在创建表时可以指定存储引擎,还可以修改表的存储引擎
CREATE TABLE …… ENGINE=engineName;
ALTER TABLE ENGINE = engineName;设置当前会话的存储引擎:
SET storage_engine=engineName;查看MySQL支持的存储引擎:
SHOW ENGINES;下面介绍MySQL常用存储引擎:
1、InnoDB存储引擎:
从MySQL 5.5.8开始,InnoDB便是其默认的存储引擎。它支持事务,设计目标为面向联机事务处理(OLTP)的应用,其特点是支持外键、行锁设计,支持类似Oracle的非锁定读,即默认读取操作不会产生锁。
参考官网,InnoDB的优点如下:
1、它根据ACID模型设计,支持事务处理来保护用户数据,例如commit、rollback、crash-recovery。
2、支持行级别的锁(without escalation to coarser granularity locks),类似Oracle的非错定读,提高了并发的性能。
3、基于primary key来存储表中数据到磁盘。每个InnoDB的表都有一个primary key索引,叫做聚集(clustered)索引,依次组织数据,当查找primary key时,可以减少I/O操作。
4、为了完整保存数据,InnoDB支持FOREIGN KEY约束。
5、InnoDB表可以和其他存储引擎类型的表混合使用。例如,可以把InnoDB表和MEMORY表通过一个查询语句join到一起。
6、InnoDB处理海量数据时,它被设计为提高CPU效率和最大化性能。
InnoDB通过使用多版本并发控制(MVCC)来提高并发性能,实现了SQL标准的4种隔离级别,使用next-key locking策略来避免幻读(phantom)。InnoDB还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用功能。
2、MyISAM存储引擎:
MyISAM不支持事务和外键,主要面向一些OLAP数据库应用。在MySQL 5.5.8之前是默认的存储引擎。
参考官网
MyISAM存储引擎是基于ISAM存储引擎的,但是增加了许多有用的扩展。
每个基于MyISAM存储引擎的表在磁盘上有三个文件,文件名以表名开始,扩展名表示其类型。.frm文件存储表定义;.myd(MyData)存储数据;.MYI(MyIndex)存储索引。
其数据文件和索引文件可以放在不同的目录,平均分配IO可以获取更快的访问速度。
MyISAM存储引擎的表有如下特点:
1、数据存储从低位开始。这使得数据和操作系统相互独立。对于二进制的可移植性要求机器使用二进制补码标志整数符号位,以及IEEE要求的浮点数格式。这些要求广泛应用于流格式中。二进制兼容不适用于嵌入式系统,嵌入式系统常常使用特殊处理器。
There is no significant speed penalty for storing data low byte first; the bytes in a table row normally are unaligned and it takes little more processing to read an unaligned byte in order than in reverse order. Also, the code in the server that fetches column values is not time critical compared to other code.
2、低位优先存储数据没有明显降低存储速度。表中数据通常是没有对齐的,以顺序读取比以逆序读取需要多一点处理。在服务器上去的行数据消耗的时间与其他操作相比,并不重要。
3、数据类型的键值存储以高位优先,为索引比较提供方便。
4、在支持大文件的文件系统和操作系统上,它支持大文件(最大支持63-bit长的文件)。
5、MyISAM表中行最多为232 (~4.295E+09)。如果编译时加上–with-big-tables选项,限制增加为(232)2 (1.844E+19)。
以通过选项–with-max-indexes=N改变,N不能大于128。
6、每一列最多能建16个索引。
7、key的长度不能超过1000bytes。可以通过重新编译改变。key长度超过250bytes时,key block的大小会比默认的1024bytes大。
8、当以顺序插入时(例如在列上使用了AUTO_INCREMENT),索引树会被分割,因此高阶节点(high node)包含一个key。这样可以优化索引树的内存。
9、支持内部处理AUTO_INCREMENT列。在插入和更新操作时,MyISAM会自动更新这一列。这会使AUTO_INCREMENT列更快(至少10%)。
10、当混合使用delete、update、insert时,动态大小的行会有更小的碎片。当下一个块被删除时,当前块会自动调整。
11、MyISAM支持并发插入:如果一个表在文件中间没有空闲的block,你可以插入新行,同时其他线程可以读取表。当删除行时,或用更多内容来更新现有行时,就会出现空闲block。当所有空闲的block都已经用完,后面的插入会变成并发。
12、可以把数据文件和索引文件放到不同物理设备的不同目录下,以此获取更快速度。
13、BLOB和TEXT列可以被索引。
14、NULL值可以存在索引列中,它将占用0到1个byte。
15、每个字符列可以有不同的字符集。
16、在索引中有一个flag标记表是否正常关闭。当使用–myisam-recover启动,MyISAM表在打开时会自动检查上次是否正常关闭,如果不是则修复。
17、如果启动时启用-update-state 选项,myisamchk标记表作为检查。当这些表没有这个标志时,myisamchk –fast 检查。
18、myisamchk –analyze为部分或全部key存储统计(statistics)。
19、myisamchk可以pack BLOB列和VARCHAR列。
Memory存储引擎
Memory存储引擎将数据存放在内存,访问速度非常快,但是如果数据库重启或崩溃,那么数据将丢失。Memory存储引擎默认使用Hash索引,而不是B+树索引;因此使用相等=比较时会比较快,但是使用范围比较时会比较慢,使用order by也会比较慢。















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









