







leveldb-expand文档
- 作者:kang
- 邮箱:likang@tju.edu.cn
- 项目地址:[https://github.com/MaxEntroy/sina-workspace/tree/master/leveldb-expand]
功能一(前缀匹配)
1.接口设计
virtual Status GetByPrefix( const ReadOptions& options,
const Slice& key,
int n,
std::vector<RecordType>& record_list
接口名:GetByPrefix
接口功能:根据key指定的前缀,获取n条匹配该前缀的记录。
参数说明:
- options:传入参数,指定读取选项,比如快照。
- key:传入参数,指定要匹配的前缀。
- n:传入参数,指定要匹配的记录条数。n为0时,匹配所有的记录。
- record_list:传出参数,存储匹配该前缀的n条记录。
返回值:返回Status对象
2.源码修改
整个过程的修改思路是,对于mentable, immutable memetable, sst这三个部分分别进行修改,增加相应的前缀匹配函数。如下图所示:
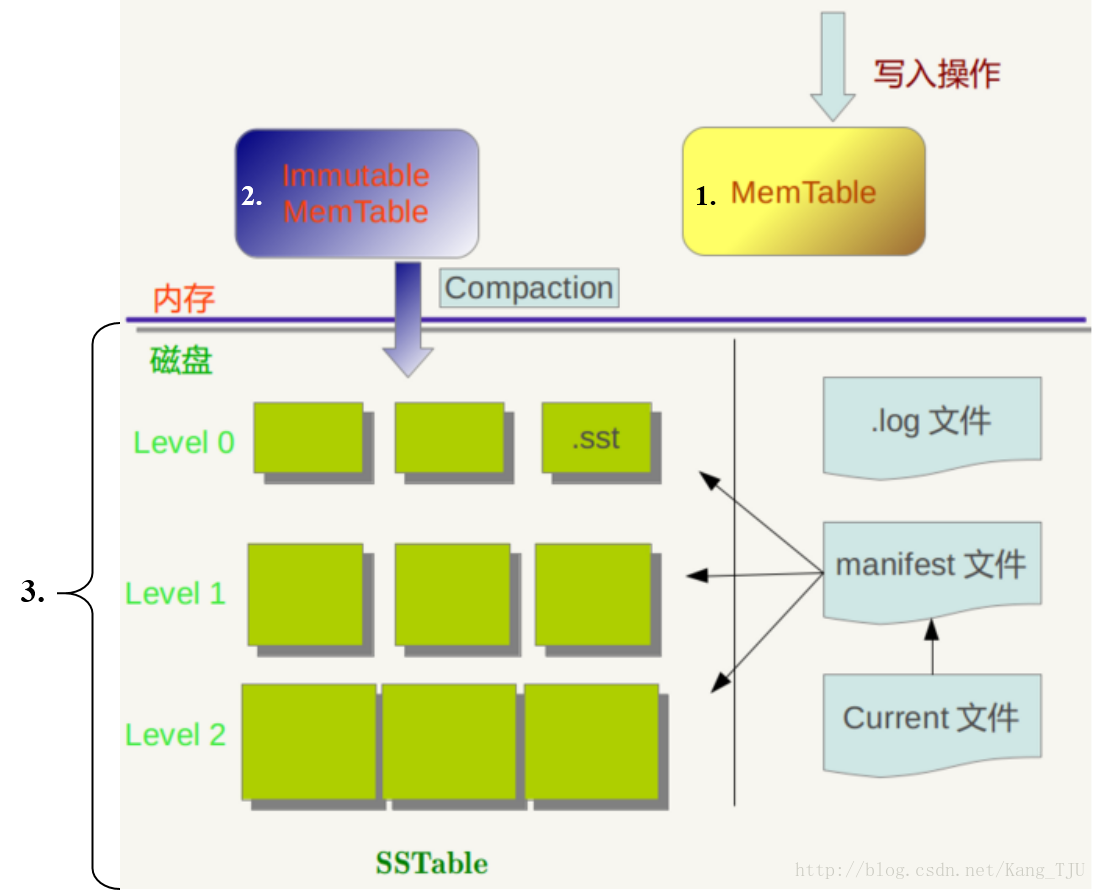
- /include/leveldb/db.h
在db.h当中增加GetByPrefix外部接口。
// Author: kang
// Mail: likang@tju.edu.cn
virtual Status GetByPrefix(const ReadOptions& options,
const Slice& key,
int n,
std::vector<RecordType>& record_list) = 0;- /include/leveldb/record_type.h
在/include/leveldb/目录下增加头文件record_type.h,包括记录类型以及回调状态。
#ifndef STORAGE_LEVELDB_INCLUDE_RECORD_TYPE_H_
#define STORAGE_LEVELDB_INCLUDE_RECORD_TYPE_H_
#include <utility>
#include <string>
#include <vector>
namespace leveldb {
typedef std::pair<std::string, std::string> RecordType;
enum SaverState {
kNotFound,
kFound,
kDeleted,
kCorrupt,
};
struct Saver {
SaverState state;
const Comparator* ucmp;
Slice user_key;
std::string* value;
};
struct SaverBatch {
SaverState state;
const Comparator* ucmp;
Slice user_key;
std::vector<RecordType>* precord_list;
};
} // leveldb
#endif // STORAGE_LEVELDB_INCLUDE_RECORD_TYPE_H_
- /db/db_impl.h
在/db/db_impl.h当中增加GetByPrefix外部接口。
// Author: kang
// Mail: likang@tju.edu.cn
virtual Status GetByPrefix(const ReadOptions& options,
const Slice& key,
int n,
std::vector<RecordType>& record_list);- /db/db_impl.cc
在/db/db_impl.cc当中增加GetByPrefix实现代码。
// Author: kang
// Mail: likang@tju.edu.cn
Status DBImpl::GetByPrefix(const ReadOptions& options,
const Slice& key,
int n,
std::vector<RecordType>& record_list) {
Status s;
MutexLock l(&mutex_);
SequenceNumber snapshot;
if (options.snapshot != NULL) {
snapshot = reinterpret_cast<const SnapshotImpl*>(options.snapshot)->number_;
} else {
snapshot = versions_->LastSequence();
}
MemTable* mem = mem_;
MemTable* imm = imm_;
Version* current = versions_->current();
mem->Ref();
if (imm != NULL) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats;
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
// debug info
//std::cout << "DBIMPL::GetBatch called." << std::endl;
//std::cout << "LookupKey: (" << key.ToString() << "," << snapshot << ")."<<std::endl;
if (mem->GetBatch(lkey, record_list, &s)) {
// Done
}
if (imm != NULL && imm->GetBatch(lkey, record_list, &s)) {
// Done
}
{
s = current->GetBatch(options, lkey, record_list, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
/*
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
*/
mem->Unref();
if (imm != NULL) imm->Unref();
current->Unref();
int sz = record_list.size();
if( n < sz && n != 0 ) {
int cnt = sz - n;
for( int i = 0; i < cnt; ++i )
record_list.pop_back();
}
return s;
}// GetByPrefix- /db/memtable.h
在/db/memtable.h当中增加GetBatch外部接口。
GetBatch接口主要用来获取批量数据。
bool GetBatch(const LookupKey& key, std::vector<RecordType>& record_list, Status* s);- /db/memtable.cc
在/db/memtable.h当中增加GetBatch实现。
bool MemTable::GetBatch(const LookupKey& key, std::vector<RecordType>& record_list, Status* s){
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
iter.Seek(memkey.data());
bool flag = false;
while (iter.Valid()) {
// entry format is:
// klength varint32
// userkey char[klength]
// tag uint64
// vlength varint32
// value char[vlength]
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry+5, &key_length);
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8),
key.user_key()) == 0) {
// Correct user key
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast<ValueType>(tag & 0xff)) {
case kTypeValue: {
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
std::string result_key = key.user_key().ToString();
std::string result_value;
result_value.assign(v.data(), v.size());
RecordType result_record(result_key, result_value);
record_list.push_back(result_record);
flag = true;
}
case kTypeDeletion:
*s = Status::NotFound(Slice());
}
iter.Next();
}// if
else
break;
}// while
return flag;
}
} // namespace leveldb
- /db/version_set.h
在/db/version_set.h当中增加GetBatch接口。
// Author: kang
// Mail: likang@tju.edu.cn
Status GetBatch(const ReadOptions&, const LookupKey& key, std::vector<RecordType>& record_list,
GetStats* stats);- /db/version_set.cc
在/db/version_set.cc当中增加GetBatch实现。
// Author: kang
// Mail: likang@tju.edu.cn
Status Version::GetBatch(const ReadOptions& options,
const LookupKey& k,
std::vector<RecordType>& record_list,
GetStats* stats){
Slice ikey = k.internal_key();
Slice user_key = k.user_key();
const Comparator* ucmp = vset_->icmp_.user_comparator();
Status s;
stats->seek_file = NULL;
stats->seek_file_level = -1;
FileMetaData* last_file_read = NULL;
int last_file_read_level = -1;
// We can search level-by-level since entries never hop across
// levels. Therefore we are guaranteed that if we find data
// in an smaller level, later levels are irrelevant.
std::vector<FileMetaData*> tmp;
FileMetaData* tmp2;
for (int level = 0; level < config::kNumLevels; level++) {
size_t num_files = files_[level].size();
if (num_files == 0) continue;
// Get the list of files to search in this level
FileMetaData* const* files = &files_[level][0];
if (level == 0) {
// Level-0 files may overlap each other. Find all files that
// overlap user_key and process them in order from newest to oldest.
tmp.reserve(num_files);
for (uint32_t i = 0; i < num_files; i++) {
FileMetaData* f = files[i];
if (ucmp->Compare(user_key, f->smallest.user_key()) >= 0 &&
ucmp->Compare(user_key, f->largest.user_key()) <= 0) {
tmp.push_back(f);
}
}
if (tmp.empty()) continue;
std::sort(tmp.begin(), tmp.end(), NewestFirst);
files = &tmp[0];
num_files = tmp.size();
} else {
// Binary search to find earliest index whose largest key >= ikey.
uint32_t index = FindFile(vset_->icmp_, files_[level], ikey);
if (index >= num_files) {
files = NULL;
num_files = 0;
} else {
tmp2 = files[index];
if (ucmp->Compare(user_key, tmp2->smallest.user_key()) < 0) {
// All of "tmp2" is past any data for user_key
files = NULL;
num_files = 0;
} else {
files = &tmp2;
num_files = 1;
}
}
}
for (uint32_t i = 0; i < num_files; ++i) {
if (last_file_read != NULL && stats->seek_file == NULL) {
// We have had more than one seek for this read. Charge the 1st file.
stats->seek_file = last_file_read;
stats->seek_file_level = last_file_read_level;
}
FileMetaData* f = files[i];
last_file_read = f;
last_file_read_level = level;
SaverBatch saver;
saver.state = kNotFound;
saver.ucmp = ucmp;
saver.user_key = user_key;
saver.precord_list = &record_list;
s = vset_->table_cache_->GetBatch(options, f->number, f->file_size,
ikey, &saver);
if (!s.ok()) {
return s;
}
switch (saver.state) {
case kNotFound:
break; // Keep searching in other files
case kFound:
return s;
case kDeleted:
s = Status::NotFound(Slice()); // Use empty error message for speed
return s;
case kCorrupt:
s = Status::Corruption("corrupted key for ", user_key);
return s;
}
}
}
return Status::NotFound(Slice()); // Use an empty error message for speed
}// GetBatch- /db/table_cache.h
在/db/table_cache.h当中增加GetBatche接口。
// Author: kang
// Mail: likang@tju.edu.cn
Status GetBatch(const ReadOptions& options,
uint64_t file_number,
uint64_t file_size,
const Slice& k,
void* arg);- /db/table_cache.cc
在/db/table_cache.cc当中增加GetBatche实现。
// Author: likang
// Mail: likang@tju.edu.cn
Status TableCache::GetBatch(const ReadOptions& options,
uint64_t file_number,
uint64_t file_size,
const Slice& k,
void* arg) {
Cache::Handle* handle = NULL;
Status s = FindTable(file_number, file_size, &handle);
if (s.ok()) {
Table* t = reinterpret_cast<TableAndFile*>(cache_->Value(handle))->table;
s = t->InternalGetBatch(options, k, arg);
cache_->Release(handle);
}
return s;
}
- /include/leveldb/table.h
在/include/leveldb当中增加InternalGetBatch接口。
Status InternalGetBatch(
const ReadOptions&, const Slice& key,
void* arg);- /table/table.h
在/table/table.h当中增加InternalGetBatch实现。
// Author: likang
// Mail: likang@tju.edu.cn
Status Table::InternalGetBatch(const ReadOptions& options, const Slice& k,
void* arg) {
Status s;
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
iiter->Seek(k);
while (iiter->Valid()) {
Slice handle_value = iiter->value();
FilterBlockReader* filter = rep_->filter;
BlockHandle handle;
if (filter != NULL &&
handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// Not found
break;
} else {
Iterator* block_iter = BlockReader(this, options, iiter->value());
block_iter->Seek(k);
while (block_iter->Valid()) {
const Slice& ikey = block_iter->key();
const Slice& v = block_iter->value();
SaverBatch* s = reinterpret_cast<SaverBatch*>(arg);
ParsedInternalKey parsed_key;
if (!ParseInternalKey(ikey, &parsed_key)) { // Not found
s->state = kCorrupt;
break;
}
else if(s->ucmp->Compare(parsed_key.user_key, s->user_key) == 0){
s->state = (parsed_key.type == kTypeValue) ? kFound : kDeleted;
if (s->state == kFound) { // found
std::string result_key;
std::string result_value;
result_key.assign( ikey.data(), ikey.size() );
result_value.assign( v.data(), v.size() );
// debug info
//std::cout << "key = " << result_key << " , value = " << result_value << std::endl;
RecordType result_record(result_key, result_value);
s->precord_list->push_back(result_record);
block_iter->Next(); // iterate to next k-v entry
}else {// Not found
break;
}
}else {// Not found
break;
}
}// while
s = block_iter->status();
delete block_iter;
iiter->Next(); // iterate to next block
}
}// while
if (s.ok()) {
s = iiter->status();
}
delete iiter;
return s;
}- /db/db_impl.cc
在/db/db_impl.cc当中修改DoCompactionWork函数,避免底层重复key在compact的时候被丢弃。
Status DBImpl::DoCompactionWork(CompactionState* compact) {
const uint64_t start_micros = env_->NowMicros();
int64_t imm_micros = 0; // Micros spent doing imm_ compactions
Log(options_.info_log, "Compacting %d@%d + %d@%d files",
compact->compaction->num_input_files(0),
compact->compaction->level(),
compact->compaction->num_input_files(1),
compact->compaction->level() + 1);
assert(versions_->NumLevelFiles(compact->compaction->level()) > 0);
assert(compact->builder == NULL);
assert(compact->outfile == NULL);
if (snapshots_.empty()) {
compact->smallest_snapshot = versions_->LastSequence();
} else {
compact->smallest_snapshot = snapshots_.oldest()->number_;
}
// Release mutex while we're actually doing the compaction work
mutex_.Unlock();
Iterator* input = versions_->MakeInputIterator(compact->compaction);
input->SeekToFirst();
Status status;
ParsedInternalKey ikey;
std::string current_user_key;
bool has_current_user_key = false;
SequenceNumber last_sequence_for_key = kMaxSequenceNumber;
for (; input->Valid() && !shutting_down_.Acquire_Load(); ) {
// Prioritize immutable compaction work
if (has_imm_.NoBarrier_Load() != NULL) {
const uint64_t imm_start = env_->NowMicros();
mutex_.Lock();
if (imm_ != NULL) {
CompactMemTable();
bg_cv_.SignalAll(); // Wakeup MakeRoomForWrite() if necessary
}
mutex_.Unlock();
imm_micros += (env_->NowMicros() - imm_start);
}
Slice key = input->key();
if (compact->compaction->ShouldStopBefore(key) &&
compact->builder != NULL) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
// Handle key/value, add to state, etc.
bool drop = false;
if (!ParseInternalKey(key, &ikey)) {
// Do not hide error keys
current_user_key.clear();
has_current_user_key = false;
last_sequence_for_key = kMaxSequenceNumber;
} else {
if (!has_current_user_key ||
user_comparator()->Compare(ikey.user_key,
Slice(current_user_key)) != 0) {
// First occurrence of this user key
current_user_key.assign(ikey.user_key.data(), ikey.user_key.size());
has_current_user_key = true;
last_sequence_for_key = kMaxSequenceNumber;
}
if (last_sequence_for_key <= compact->smallest_snapshot) {
// Hidden by an newer entry for same user key
//drop = true; // (A)
} else if (ikey.type == kTypeDeletion &&
ikey.sequence <= compact->smallest_snapshot &&
compact->compaction->IsBaseLevelForKey(ikey.user_key)) {
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
last_sequence_for_key = ikey.sequence;
}
#if 0
Log(options_.info_log,
" Compact: %s, seq %d, type: %d %d, drop: %d, is_base: %d, "
"%d smallest_snapshot: %d",
ikey.user_key.ToString().c_str(),
(int)ikey.sequence, ikey.type, kTypeValue, drop,
compact->compaction->IsBaseLevelForKey(ikey.user_key),
(int)last_sequence_for_key, (int)compact->smallest_snapshot);
#endif
if (!drop) {
// Open output file if necessary
if (compact->builder == NULL) {
status = OpenCompactionOutputFile(compact);
if (!status.ok()) {
break;
}
}
if (compact->builder->NumEntries() == 0) {
compact->current_output()->smallest.DecodeFrom(key);
}
compact->current_output()->largest.DecodeFrom(key);
compact->builder->Add(key, input->value());
// Close output file if it is big enough
if (compact->builder->FileSize() >=
compact->compaction->MaxOutputFileSize()) {
status = FinishCompactionOutputFile(compact, input);
if (!status.ok()) {
break;
}
}
}
input->Next();
}
if (status.ok() && shutting_down_.Acquire_Load()) {
status = Status::IOError("Deleting DB during compaction");
}
if (status.ok() && compact->builder != NULL) {
status = FinishCompactionOutputFile(compact, input);
}
if (status.ok()) {
status = input->status();
}
delete input;
input = NULL;
CompactionStats stats;
stats.micros = env_->NowMicros() - start_micros - imm_micros;
for (int which = 0; which < 2; which++) {
for (int i = 0; i < compact->compaction->num_input_files(which); i++) {
stats.bytes_read += compact->compaction->input(which, i)->file_size;
}
}
for (size_t i = 0; i < compact->outputs.size(); i++) {
stats.bytes_written += compact->outputs[i].file_size;
}
mutex_.Lock();
stats_[compact->compaction->level() + 1].Add(stats);
if (status.ok()) {
status = InstallCompactionResults(compact);
}
if (!status.ok()) {
RecordBackgroundError(status);
}
VersionSet::LevelSummaryStorage tmp;
Log(options_.info_log,
"compacted to: %s", versions_->LevelSummary(&tmp));
return status;
}功能二(条件匹配)
1.接口设计
virtual Status GetByCondition(const ReadOptions& options,
const Slice& key,
const Slice& key_filter,
const Slice& value_filter,
int n,
std::vector<RecordType>& record_list
接口名:GetByCondtion
接口功能:根据指定的key,以及相应的key和value的过滤条件,获取n条满足条件的记录。
参数说明:
- options:传入参数,指定读取选项,比如快照。
- key:传入参数,指定要匹配的key
- key_filter:传入参数,指定要匹配的key的过滤条件。如果传入空串,则该条件失效。
- value_filter:传入参数,指定要匹配的value的过滤条件。如果传入空串,则该条件失效
- n:传入参数,指定要匹配的记录条数。n为0时,匹配所有的记录。
- record_list:传出参数,存储符合以上条件的记录。
返回值:返回Status对象
2.源码修改
源码的修改思路是,借助之前实现的GetByPrefix函数,首先匹配满足key的所有记录,然后对该结果分别用key和value的过滤条件进行过滤,最后对记录数量进行限制。
- /include/leveldb/db.h
在db.h当中增加GetByConditon外部接口。
virtual Status GetByCondition(const ReadOptions& options,
const Slice& key,
const Slice& key_filter,
const Slice& value_filter,
int n,
std::vector<RecordType>& record_list) = 0;- /db/db_impl.h
在/db/db_impl.h当中增加GetByCondition外部接口。
// Author: kang
// Mail: likang@tju.edu.cn
virtual Status GetByCondition(const ReadOptions& options,
const Slice& key,
const Slice& key_filter,
const Slice& value_filter,
int n,
std::vector<RecordType>& record_list);- /db/db_impl.cc
在/db/db_impl.cc当中增加GetByCondition实现代码。
// Author: kang
// Mail: likang@tju.edu.cn
Status DBImpl::GetByCondition(const ReadOptions& options,
const Slice& key,
const Slice& key_filter,
const Slice& value_filter,
int n,
std::vector<RecordType>& record_list) {
Status s;
std::vector<RecordType> tmp_list;
GetByPrefix( leveldb::ReadOptions(), key, 0, tmp_list );
int sz = tmp_list.size();
for( int i = 0; i < sz; ++i ) {
Slice tmp_key( tmp_list[i].first );
Slice tmp_value( tmp_list[i].second );
if( key_filter != "" && value_filter != "" ) {
if( tmp_key.substr( key_filter )!= -1 && tmp_value.substr( value_filter ) != -1 ) {
record_list.push_back( tmp_list[i] );
}
}
else if( key_filter != "" && value_filter == "" ) {
if( tmp_key.substr( key_filter ) != -1 ) {
record_list.push_back( tmp_list[i] );
}
}
else if( key_filter == "" && value_filter != "" ) {
if( tmp_value.substr( value_filter ) != -1 ) {
record_list.push_back( tmp_list[i] );
}
}
else {
record_list.push_back( tmp_list[i] );
}
}
sz = record_list.size();
if( n < sz && n != 0 ) {
int cnt = sz - n;
for( int i = 0; i < cnt; ++i ) {
record_list.pop_back();
}
}
return s;
}// GetByCondition非功能修改部分
- /db/db_test.cc
需要在db_test.cc当中的ModelDB类再次增加上面所实现的两个功能借口。
class ModelDB: public DB {
public:
class ModelSnapshot : public Snapshot {
public:
KVMap map_;
};
explicit ModelDB(const Options& options): options_(options) { }
~ModelDB() { }
virtual Status Put(const WriteOptions& o, const Slice& k, const Slice& v) {
return DB::Put(o, k, v);
}
virtual Status Delete(const WriteOptions& o, const Slice& key) {
return DB::Delete(o, key);
}
virtual Status Get(const ReadOptions& options,
const Slice& key, std::string* value) {
assert(false); // Not implemented
return Status::NotFound(key);
}
// Author: kang
// Mail: likang@tju.edu.cn
virtual Status GetByPrefix(const ReadOptions& options,
const Slice& key,
int n,
std::vector<RecordType>& record_list) {
return Status::NotFound(key);
}
// Author: kang
// Mail: likang@tju.edu.cn
virtual Status GetByCondition(const ReadOptions& options,
const Slice& key,
const Slice& key_filter,
const Slice& value_filter,
int n,
std::vector<RecordType>& record_list ) {
return Status::NotFound(key);
}
virtual Iterator* NewIterator(const ReadOptions& options) {
if (options.snapshot == NULL) {
KVMap* saved = new KVMap;
*saved = map_;
return new ModelIter(saved, true);
} else {
const KVMap* snapshot_state =
&(reinterpret_cast<const ModelSnapshot*>(options.snapshot)->map_);
return new ModelIter(snapshot_state, false);
}
}
virtual const Snapshot* GetSnapshot() {
ModelSnapshot* snapshot = new ModelSnapshot;
snapshot->map_ = map_;
return snapshot;
}
virtual void ReleaseSnapshot(const Snapshot* snapshot) {
delete reinterpret_cast<const ModelSnapshot*>(snapshot);
}
virtual Status Write(const WriteOptions& options, WriteBatch* batch) {
class Handler : public WriteBatch::Handler {
public:
KVMap* map_;
virtual void Put(const Slice& key, const Slice& value) {
(*map_)[key.ToString()] = value.ToString();
}
virtual void Delete(const Slice& key) {
map_->erase(key.ToString());
}
};
Handler handler;
handler.map_ = &map_;
return batch->Iterate(&handler);
}
virtual bool GetProperty(const Slice& property, std::string* value) {
return false;
}
virtual void GetApproximateSizes(const Range* r, int n, uint64_t* sizes) {
for (int i = 0; i < n; i++) {
sizes[i] = 0;
}
}
virtual void CompactRange(const Slice* start, const Slice* end) {
}
private:
class ModelIter: public Iterator {
public:
ModelIter(const KVMap* map, bool owned)
: map_(map), owned_(owned), iter_(map_->end()) {
}
~ModelIter() {
if (owned_) delete map_;
}
virtual bool Valid() const { return iter_ != map_->end(); }
virtual void SeekToFirst() { iter_ = map_->begin(); }
virtual void SeekToLast() {
if (map_->empty()) {
iter_ = map_->end();
} else {
iter_ = map_->find(map_->rbegin()->first);
}
}
virtual void Seek(const Slice& k) {
iter_ = map_->lower_bound(k.ToString());
}
virtual void Next() { ++iter_; }
virtual void Prev() { --iter_; }
virtual Slice key() const { return iter_->first; }
virtual Slice value() const { return iter_->second; }
virtual Status status() const { return Status::OK(); }
private:
const KVMap* const map_;
const bool owned_; // Do we own map_
KVMap::const_iterator iter_;
};
const Options options_;
KVMap map_;
};















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









