







Motivation
SVM在通用场景下的分类性能和模型学习是非常高效的,但是在推荐场景下,用户与商品的交互矩阵是高度稀疏(sparse)的,SVM并不适用于向量高度稀疏的学习任务中。于是,本文提出了一个新的模型——Factorization Machine(因子分解机),简称FM,来解决向量高度稀疏场景下的模型学习问题。
Contribution
主要有三点:
- FM能够在数据非常稀疏的场景下学习,这一点SVM做不到。(你做不了的,我能做)
- FM计算复杂度是线性的,这一点保证了它能够适应大规模数据集。(我不仅能做,而且效率还高,速度快)
- FM不仅适用于稀疏场景,在通用场景下也表现很好。(你做得了的,我也能做)
Solution
先来看第一个问题,为什么对SVM来说很吃力的任务,FM能轻松完成呢?这就要从FM的目标函数说起:
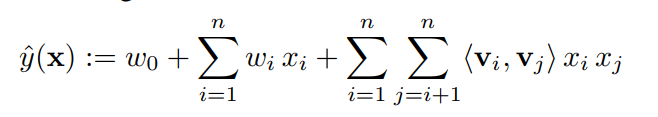
上面是二阶FM的表达式,为什么只考虑二阶,是因为二阶FM是实际应用场景中用得最多的,文章贡献中的线性复杂度也是从二阶推导出来的。当然从定义上来看,FM可以是任意阶。
w 0 w_0 w0: 零阶系数,模型的整体偏差
w i w_i wi: 一阶系数 ,每个特征 x i x_i xi的权重
< v i , v j > <v_i,v_j> <vi,vj> : 二阶关系, < ⋅ , ⋅ > <·,·> <⋅,⋅>表示两个向量的内积。 v i v_i vi是与 x i x_i xi对应的 k k k维向量,意思就是对于每个向量 x i x_i x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









