







(文章同步更新于个人博客@dai98.github.io)
泰坦尼克幸存者预测是Kaggle上数据竞赛的入门级别的比赛,我曾经在一年前作为作业参加过这个比赛,我想要再次从这个比赛开始,尝试不同的模型,来当作在Kaggle比赛的起点。
关于此次竞赛,我想分成两个部分,第一个部分基于PyTorch建立神经网络,第二个部分使用sklearn做多个分类器投票。
使用的编程环境及依赖包版本:
import matplotlib
from matplotlib import pyplot as plt
import seaborn as sns
import IPython
import numpy as np
import pandas as pd
from collections import Counter
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
import warnings
import sys
import os
warnings.filterwarnings("ignore")
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"

一、数据预处理
首先我们看看数据中有多少空缺值:
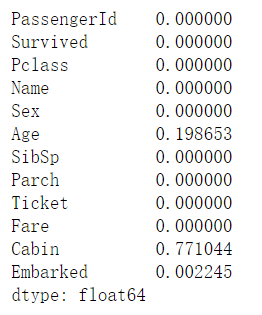
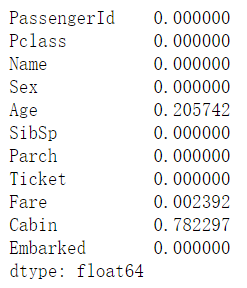
我们可以看到,Age、Cabin、Embarked和Fare有空缺值。Cabin有78%的空缺值,而且其余值也没有明显的规律,我们在之后可以直接删除改列。对于其他值,我们可以对Age和Fare补充中位数,把Embarked补充频率最高的值。
我们可以把训练数据train与测试数据test拼接在一起,一起来进行处理,可以省去各自处理的麻烦。
data = [train,test]
train_backup = train.copy()
test_backup = test.copy()
for dataset in data:
dataset["Age"].fillna(dataset["Age"].median(),inplace = True)
dataset["Fare"].fillna(dataset["Fare"].median(),inplace = True)
dataset["Embarked"].fillna(dataset["Embarked"].mode()[0],inplace = True)
这里有一点需要提醒,如果我们使用for循环来对两个数据集依次进行处理,需要注意Python在对列表值的遍历的时候提供的值是列表值中的浅拷贝,也就是说dataset和data[0]中的值对应的是一个指针,然而是两个不同的对象。所以对dataset做重赋值的情况,并不会真正改变train和test两个数据集。Pandas中有些函数(drop,apply等)可以对数据集进行操作来改变数据集,但记得要把inplace参数设置为True。如果想要在循环中修改数据集的值,一定要记得通过索引来访问列表!
现在没有了空缺值,我们来处理一下其他的数据。我们从Name开始,虽然一个人叫什么不会影响他/她是否幸存,但如果你自己观察,每个人的名字中间带有他们的称谓,或者前缀(Mr, Mrs),能从一定程度上反映出他/她的性别和社会地位,也会一定程度的影响幸存与否。
threshhold = 10
for dataset in data:
dataset["Prefix"] = dataset["Name"].apply(lambda x:x.split(" ")[1])
freq = (dataset["Prefix"].value_counts() < threshhold)
dataset["Prefix"] = dataset["Prefix"].apply(lambda x: "others" if freq.loc[x] else x)
这里我发现称谓的种类实在太多了,有许多只出现了一两次,所以我把所有出现低于10次的称谓都重新赋为"others"。
我们来继续处理其他变量。我看到SibSp和Parch代表船上兄弟姐妹、配偶、父母、孩子的数量,可以把它们相加来代表家人的数量,并再添加一个二元变量,代表该人当时在船上是否只有一个人。注意,我再相加的时候多加了1,代表整个家庭的人数,你也可以不加1,代表他/她的家人的数量。
for dataset in data:
# The size of the whole family
dataset["Family"] = dataset["Parch"] + dataset["SibSp"] + 1
dataset["IsAlone"] = dataset["Family"].apply(lambda x: 1 if x == 1 else 0)
dataset["FareBin"] = pd.qcut(dataset["Fare"],4)
dataset["AgeBin"] = pd.cut(dataset["Age"],4)
dataset["FamilyBin"] = pd.cut(dataset["Family"],3)
我又根据数值的大小,将Fare、Age和Family进行分段重新归类。这样的离散化处理使得我们将连续性变量转换为类别型的变量。注意cut函数和qcut的区别,cut函数是将数据分割成等长区间,每个区间的观测值数量不等;qcut是将数据分割成自适应区间,虽然区间的长度是不固定的,但是每个区间的观测值数量是相等的。
然而,如果此时你查看我们的数据,你会发现数据的值变成了区间。为了再之后做独热码的时候变量名更加清晰,我们将变量的值重新赋为数字类别:


label = preprocessing.LabelEncoder()
label_columns = ["FareBin","AgeBin","FamilyBin"]
for dataset in data:
for label_column in label_columns:
dataset[label_column] = label.fit_transform(dataset[label_column])
最后一步,因为数字类别的特征会导致类别本身数值大小也成为特征,因此我们把数字类别转换为独热码。例如,类别3转换为[0 0 1],这样数字本身的大小便不会影响模型了。除此之外,我们再将没有用处的列删除掉。
drop_columns = ["PassengerId","Name","Age","SibSp","Parch",
"Ticket","Fare","Cabin","Family"]
dummy_columns = ["Pclass","Sex","Embarked","Prefix","FareBin","AgeBin","FamilyBin"]
for i,dataset in enumerate(data):
data[i].drop(drop_columns,axis = 1,inplace = True)
for dummy in dummy_columns:
dummy_df = pd.get_dummies(dataset[dummy],prefix = dummy)
data[i] = pd.concat([data[i],dummy_df],axis = 1)
data[i].drop(dummy,axis = 1,inplace = True)
最后数据的特征:

我们再将数据重新分割成训练集和测试集:
train = data[0]
test = data[1]
train_data = train.drop("Survived",axis = 1,inplace = False)
train_target = train["Survived"]
二、变量选择
我们通过计算每个变量之间的相关系数,来判断每个变量和目标变量(Survived)之间的相关系数,并通过每个变量之间的相关系数来判断多重共线性是否存在。
correlation = train.corr()
_, ax = plt.subplots(figsize = (10,10))
colormap = sns.diverging_palette(220,10,as_cmap = True)
_ = sns.heatmap(correlation,
cmap = colormap,
square = True,
cbar_kws = {"shrink":.6},
ax = ax,
linewidths = 0.1, vmax = 1.0, linecolor = "white",
annot_kws = {"fontsize":12}
)
plt.title("Correlation Heatmap \n")
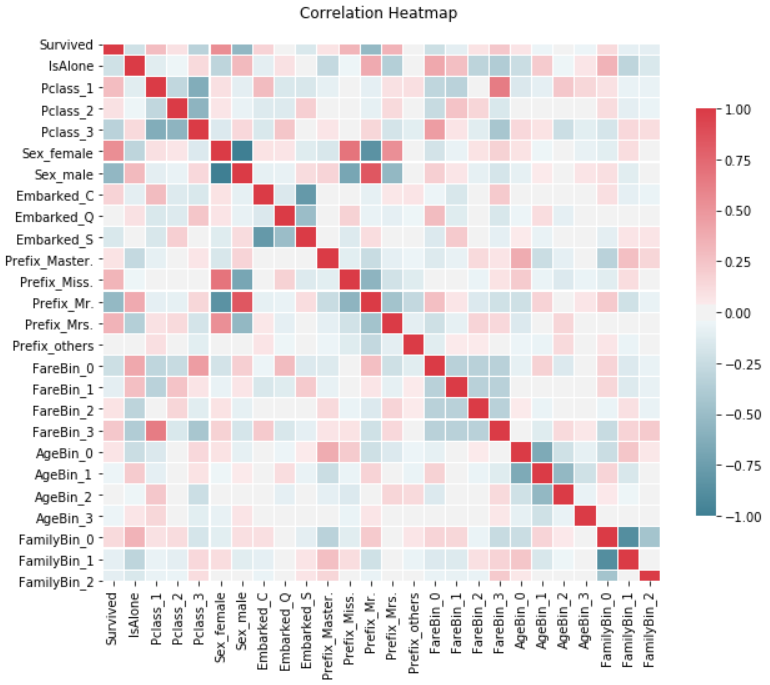
我们发现相关系数比较高的变量是Sex和Prefix,也就是如果一个人的性别是男的,他就不可能是女的,并且很大概率被称作"Mr."。对我们的回归没有很大的影响,我们无需删除。
三、模型搭建
神经网络的搭建基于PyTorch,首先我们把数据从Pandas的DataFrame转换为Numpy的array,再通过torch的from_numpy函数来生成Tensor。
train_data = np.array(train_data)
train_target = np.array(train_target)
test = np.array(test)
data_tensor = torch.from_numpy(train_data).type(torch.FloatTensor)
target_tensor = torch.from_numpy(train_target).type(torch.LongTensor)
test_tensor = torch.from_numpy(test).type(torch.FloatTensor)
注意,虽然我们的数据集只有0和1两种值,但是必须要设置为FloatTensor,因为稍后要计算交叉熵损失函数;而目标张量target_tensor设置成LongTensor即可。
现在我们来设置一下之后会用到的模型的超参数:
config = {
"USE_CUDA":torch.cuda.is_available(),
"N":train_data.shape[0],
"D_in":train_data.shape[1],
"H":train_data.shape[1]+1,
"D_out":2,
"learning_rate":0.02,
"epoch":10000
}
下面我们就可以开始创建模型了,在这里我用了三层的神经网络,前两层使用了ReLU激活函数,最后一层使用Sigmoid激活函数来进行二分类,并在中间添加了一层Dropout,来防止过拟合。
class Model(nn.Module):
def __init__(self,D_in,H,D_out):
super(Model,self).__init__()
self.linear1 = nn.Linear(D_in,H)
self.linear2 = nn.Linear(H,H)
self.linear3 = nn.Linear(H,D_out)
self.dropout = nn.Dropout(0.3)
def forward(self,x):
layer1 = F.relu(self.linear1(x))
layer2 = F.relu(layer1)
layer2 = self.dropout(layer2)
layer3 = F.sigmoid(self.linear3(layer2))
return layer3
def predict(self,x):
pred = self.forward(x)
ans = []
for t in pred:
if t[0]>t[1]:
ans.append(0)
else:
ans.append(1)
return torch.tensor(ans)
下面我们就可以创建模型对象,以及损失函数、优化器和Scheduler:
model = Model(config["D_in"],config["H"],config["D_out"])
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=config["learning_rate"])
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma = 0.5)
Scheduler是帮助我们的Learning rate衰退用的,在下面会详细解释到。
如果安装了CUDA和Cudnn,可以使用GPU加速计算:
if config["USE_CUDA"]:
model = model.cuda()
data_tensor = data_tensor.cuda()
target_tensor = target_tensor.cuda()
test_tensor = test_tensor.cuda()
现在我们开始训练过程:
losses = []
for epoch in range(config["epoch"]+1):
pred_tensor = model(data_tensor)
loss = loss_func(pred_tensor,target_tensor)
if epoch % 500 == 0:
print("Epoch",epoch," loss",loss.item())
if epoch % 1000 == 0:
loss_value = loss.item()
if len(losses) == 0 or loss_value < min(losses):
print("Minimum Loss Updated")
torch.save(model.state_dict(),"model.pth")
else:
print("Learning rate decay")
scheduler.step()
losses.append(loss_value)
loss.backward()
optimizer.step()
optimizer.zero_grad()
在这里,我设置了每500轮显示一次损失函数的值;每1000轮存储一次损失函数,如果损失函数的值是当前最小的值,说明当前是模型最优的时候,我们将其保存,如果稍后有更优的值,将覆盖此次值;如果损失函数的值没有增大,那我们就将Learning rate减小一半。
为什么要减小呢?实际上模型训练的过程和下山的过程很像,Learning Rate就是我们步子的大小。我们训练的过程实际上就是从当前位置走到最低点。在最开始的时候我们步子很大,所以下降的很快,过了一会儿,我们发现因为我们步子太长,一直在一个坑的两侧迈来迈去,进不到坑里面。那么怎么办呢?只要步子小一点就行了!这也是Scheduler的作用,在训练受到阻碍的时候帮助我们把Learning Rate减小。
现在训练完成,我们只需要新建一个模型,读取刚才模型最优时候的状态,再用最优模型来预测测试集数据即可:
best_model = Model(config["D_in"],config["H"],config["D_out"])
if config["USE_CUDA"]:
best_model = best_model.cuda()
best_model.load_state_dict(torch.load("model.pth"))
test_target = best_model.predict(test_tensor)
test_target = test_target.cpu().numpy()
注意,我们在使用GPU训练之后,要将Tensor从GPU上推回CPU。
最后我们把结果保存成csv文件即可。
res = {
"PassengerId":test_backup["PassengerId"],
"Survived":test_target
}
res_dataframe = pd.DataFrame(res)
res_dataframe.to_csv("result.csv", index = False)

可以看到,我们的准确率为77.51%,下一篇文章使用的多分类器投票将进一步提升正确率。
四、参考资料
[1]. A Data Science Framework: To Achieve 99% Accuracy
[2]. Python进行泰坦尼克生存预测
[3]. PyTorch实现二分类器
[4]. Kaggle Titanic生死率预测















 4278
4278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









