







(文章同步更新于个人博客@dai98.github.io)
源代码:Github
上一篇文章介绍了如何使用深度学习来预测泰坦尼克号幸存者,这一部分使用多分类器投票来做。由于数据预处理部分比较相似,重复的地方不再赘述,把重点放在模型的构建和优化上面。
使用的环境以及依赖包版本:
from matplotlib import pyplot as plt
import matplotlib
import seaborn as sns
import scipy
import numpy as np
import pandas as pd
import IPython
from IPython import display
import sklearn
from sklearn.model_selection import train_test_split
import xgboost
import warnings
import sys
import random
import time
# Machine Learning algorithms
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble
from sklearn import discriminant_analysis,gaussian_process
from xgboost import XGBClassifier
# Model helper
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
# Visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
from pandas.plotting import scatter_matrix
# Configuration
%matplotlib inline
mpl.style.use("ggplot")
sns.set_style("white")
pylab.rcParams["figure.figsize"] = 12,8
一、数据预处理
依旧是先填补空缺值,再将数值转换为类别型变量,区别是这次我们不用再将变量转化为独热码了。下面的过程在上一篇文章都介绍过,不再重复了。
data = [train,test]
train_backup = train.copy()
test_backup = test.copy()
for dataset in data:
# Fill with median value
dataset["Age"].fillna(dataset["Age"].median(),inplace = True)
# Fill with the most common value
dataset["Embarked"].fillna(dataset["Embarked"].mode()[0], inplace = True)
# Fill with median value
dataset["Fare"].fillna(dataset["Fare"].median(),inplace = True)
drop_columns = ["PassengerId","Cabin","Ticket"]
for dataset in data:
dataset.drop(drop_columns, axis = 1, inplace = True)
min_stat_thresh = 10
for dataset in data:
freq = (dataset["Title"].value_counts() < min_stat_thresh)
dataset["Title"] = dataset["Title"].apply(lambda x: "others" if freq .loc[x] else x)
label = LabelEncoder()
for dataset in data:
dataset["Sex_Code"] = label.fit_transform(dataset["Sex"])
dataset["Embarked_Code"] = label.fit_transform(dataset["Embarked"])
dataset["Title_Code"] = label.fit_transform(dataset["Title"])
dataset["AgeBin_Code"] = label.fit_transform(dataset["AgeBin"])
dataset["FareBin_Code"] = label.fit_transform(dataset["FareBin"])
处理完成后,我们将数据集分割开:
Target = ["Survived"]
train = data[0]
test = data[1]
data_x = ["Sex","Pclass","Embarked","Title","SibSp","Parch","Age","Fare",
"Family","IsAlone"]
data_x_calc = ["Sex_Code","Pclass","Embarked_Code","Title_Code","SibSp","Parch",
"Age","Fare"]
data_xy = Target + data_x
data_x_bin = ["Sex_Code","Pclass","Embarked_Code","Title_Code","FareBin_Code",
"AgeBin_Code","Family"]
data_xy_bin = Target + data_x_bin
data_dummy = pd.get_dummies(train[data_x])
data_x_dummy = data_dummy.columns.tolist()
data_xy_dummy = Target + data_x_dummy
之后我们的模型使用离散化后的数据data_x_bin,data_x不再使用。为了便于之后需要,再生成一份独热码的数据data_x_dummy。
二、变量选择
我们依旧计算出所有变量的相关系数矩阵,用热力图可视化:
correlation = data[0].corr()
_, ax = plt.subplots(figsize = (14,12))
colormap = sns.diverging_palette(220,10,as_cmap = True)
_ = sns.heatmap(correlation,
cmap = colormap,
square = True,
cbar_kws = {"shrink":.9},
ax = ax,
annot = True,
linewidths = 0.1, vmax = 1.0, linecolor = "white",
annot_kws = {"fontsize":12}
)
plt.title("Correlation Heatmap\ n")
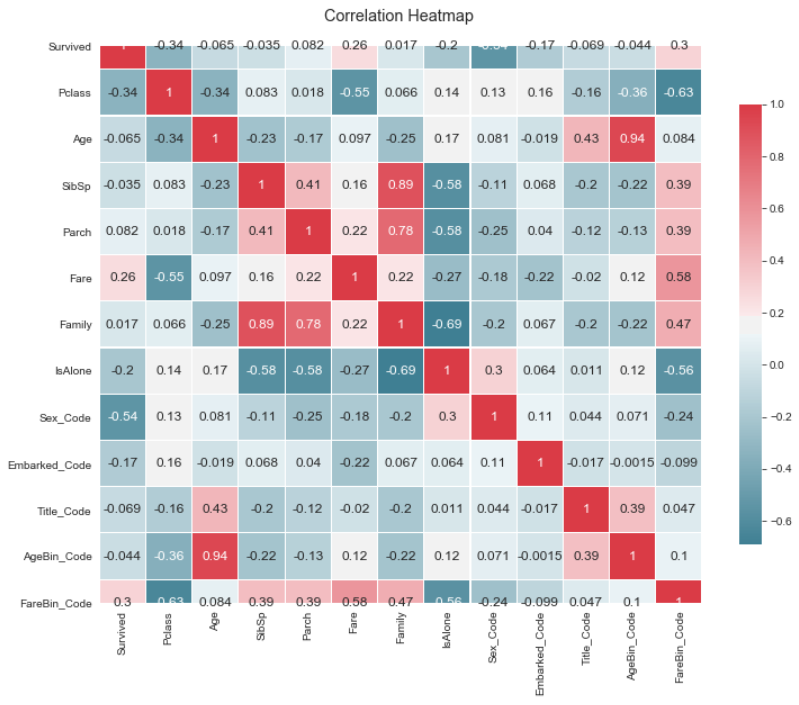
我们可以看到,关联程度较大的变量都在data_x中,在之后都不会用到。
三、模型搭建
首先我们来划分数据集:
train_x, val_x, train_y, val_y = model_selection.train_test_split(train[data_x_calc], train[Target], random_state = 0)
train_x_bin, val_x_bin, train_y_bin, val_y_bin = model_selection.train_test_split(train[data_x_bin], train[Target] , random_state = 0)
train_x_dummy, val_x_dummy, train_y_dummy, val_y_dummy = model_selection.train_test_split(data_dummy[data_x_dummy], train[Target], random_state = 0)
我们来初始化所有的模型,将其放在一个列表中:
# Machine Learning Algorithm Selection and Initialization
MLA = [
# Ensemble Methods
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
# Gaussian Process
gaussian_process.GaussianProcessClassifier(),
#Generalized Linear Model
linear_model.LogisticRegressionCV(),
linear_model.PassiveAggressiveClassifier(),
linear_model.RidgeClassifierCV(),
linear_model.SGDClassifier(),
linear_model.Perceptron(),
# Naive Bayes
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(),
# Nearest Neighbor
neighbors.KNeighborsClassifier(),
# SVM
svm.SVC(probability = True),
svm.NuSVC(probability = True),
svm.LinearSVC(),
# Trees
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(),
# Discriminant Classifier
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(),
#XGBoost
XGBClassifier()
]
生成下面要用的交叉验证的数据划分(在下面会详细介绍),并生成一个Pandas的DataFrame来储存各个模型在训练集上的效果:
cv_split = model_selection.ShuffleSplit(n_splits = 10, test_size = 0.3,
train_size = 0.6, random_state = 0)
# Dataframe to store the metrics
MLA_columns = ["MLA Name","MLA Parameters",
"MLA Test Accuracy Mean","MLA Test Accuracy 3*STD","MLA Time"]
MLA_compare = pd.DataFrame(columns = MLA_columns,index=range(0,len(MLA)))
MLA_predict = train[Target]
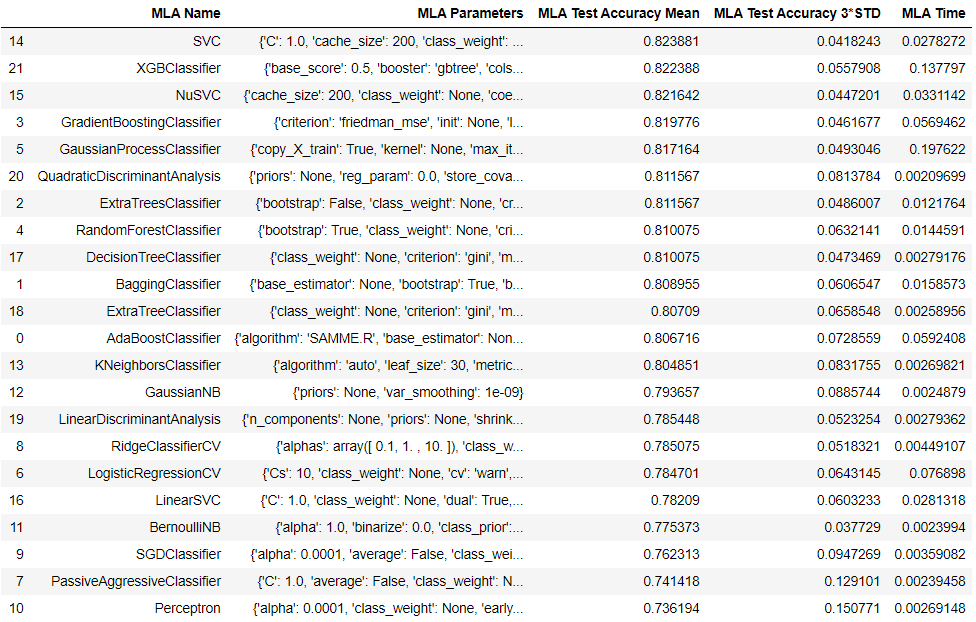
下面让所有模型在训练集上用交叉验证拟合一遍,来查看所有模型的表现:
row_index = 0
for alg in MLA:
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, "MLA Name"] = MLA_name
MLA_compare.loc[row_index, "MLA Parameters"] = str(alg.get_params())
# Cross Validation
cv_results = model_selection.cross_validate(alg, train[data_x_bin], train[Target], cv = cv_split)
MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std()*3
alg.fit(train[data_x_bin],train[Target])
MLA_predict[MLA_name] = alg.predict(train[data_x_bin])
row_index += 1
MLA_compare = MLA_compare.sort_values(by = ['MLA Test Accuracy Mean'], ascending = False, inplace = False)
MLA_compare
这样我们可以得到各个模型训练集上的效果:
sns.barplot(x = "MLA Test Accuracy Mean", y = "MLA Name", data=MLA_compare, color="m")
plt.title("Machine Learning Algorithm Accuracy Score \n")
plt.xlabel("Accuracy Score (%)")
plt.ylabel("Algorithm")
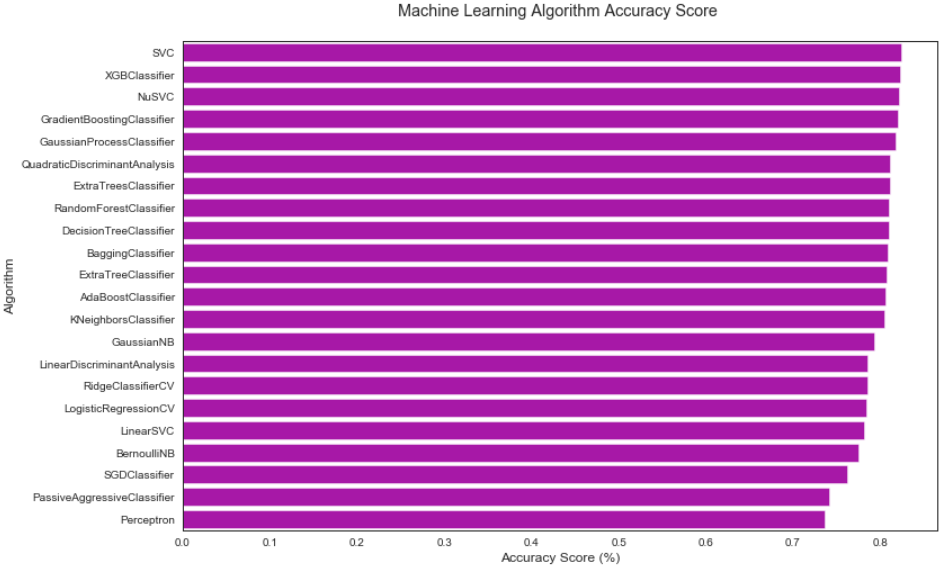
在上面的源代码中,你可以看到,为了评测每个模型的表现,我们需要先让它们预测,再使用其预测结果和真实结果进行比对,计算正确率。因此我们选用的数据集是train而不是test,因为test我们根本不知道预测结果。而在使用train数据集的时候,我们又要将train划分为训练集和测试集,这一部分测试集,也就是训练数据划分出的测试集,我们一般要做验证集(Validation data),这也是验证的作用。
为什么需要验证呢?无论我们最终的目标是拟合还是分类,都有许多种模型,而哪一种模型才是最适合这个数据集的呢,我们就需要用训练集训练这些模型,再使用验证集找出来表现最好的模型。找到了最好的模型还不够,因为大部分模型都有超参数来影响分类,例如随机森林子树的数量,或是KNN中k的大小,我们要对超参数设不同的值,再进行重复验证,找出最好的一组超参数,从而达到最优的效果(这也是稍后我们要做的)。找到了最优的模型,我们再用这个训练集来训练模型,这样就是我们最终得模型。在这个分类任务中,我们使用投票(稍后介绍),因此所有的模型都可以派上用场,这里只是简单查看一下模型的表现。
那么交叉验证(Cross Validation)是什么呢?验证集是我们把训练数据划分为两部分,而交叉验证是我们把训练数据等分为N份 (N一般为5或10),并重复训练N次,每次将第 i i i份作为验证集 ( i = 1 , 2 , ⋯ , N i = 1,2,\cdots,N i=1,2,⋯,N),将其余N-1份作为训练集,最后将N个损失函数的值和准确率求平均,即交叉验证后模型的表现。这样大费周折有什么好处呢?首先交叉验证可以增强我们数据的稳定性,如果验证集和训练集的差异比较大,那模型最后的表现可能比较差;交叉验证使得我们的loss和准确率是整个数据集上的平均值,使得模型的表现不会因为验证集被随机分配到的几个离群点影响。其次是,我们的训练集和验证集都变多了,原来的验证集可能只有20%,现在是整个数据集。
现在,你也许能够理解上面我做了什么,首先我规定了数据划分的方式(cv_split变量),其次我对每个模型都进行交叉验证来评测它们的表现,并最后把结果可视化。
下面我们来创建我们的投票集合,什么是投票呢?投票 (Voting)是一种把多个模型的预测结果统一的过程,对于分类问题来说,即对于一条数据,统计所有分类器的预测值,把频率出现最多的预测结果当作该条数据的预测值,比较像“少数服从多数”的效果。而投票又分类硬投票和软投票,硬投票就像上文说的统计各个分类器的结果;而软分类是在分类器计算每个类别的概率后(分类实际上计算的是各类的概率),并对每一类的概率求和,最后可以得到各类的概率和,选取概率和最高的那一类。在Python中,我们的投票器是一个列表,其中由多个元组组成,元组中是分类器的名字与对象。
vote_est = [
# Ensemble Methods
("ada", ensemble.AdaBoostClassifier()),
("bc", ensemble.BaggingClassifier()),
("etc", ensemble.ExtraTreesClassifier()),
("gbc", ensemble.GradientBoostingClassifier()),
("rfc", ensemble.RandomForestClassifier()),
# Gaussian Processes
("gpc", gaussian_process.GaussianProcessClassifier()),
#GLM
("lr",linear_model.LogisticRegressionCV()),
# Navies Bayes
("bnb", naive_bayes.BernoulliNB()),
("gnb", naive_bayes.GaussianNB()),
# Nearest Neighbor
("knn", neighbors.KNeighborsClassifier()),
# SVM
("svc",svm.SVC(probability=True)),
#xgboost
("xgb",XGBClassifier())
]
我们来看看硬软分类之后的效果,同样,我们也使用交叉验证:
# Hard Vote
vote_hard = ensemble.VotingClassifier(estimators = vote_est, voting = "hard")
vote_hard_cv = model_selection.cross_validate(vote_hard, train[data_x_bin], train[Target],cv = cv_split)
vote_hard.fit(train[data_x_bin],train[Target])
print("Hard Voting Test w/bin score mean: {:.2f}". format(vote_hard_cv['test_score'].mean()*100))
print("Hard Voting Test w/bin score 3*std: +/- {:.2f}". format(vote_hard_cv['test_score'].std()*100*3))

# Soft Vote
vote_soft = ensemble.VotingClassifier(estimators = vote_est , voting = 'soft')
vote_soft_cv = model_selection.cross_validate(vote_soft, train[data_x_bin], train[Target], cv = cv_split)
vote_soft.fit(train[data_x_bin], train[Target])
print("Soft Voting Test w/bin score mean: {:.2f}". format(vote_soft_cv['test_score'].mean()*100))
print("Soft Voting Test w/bin score 3*std: +/- {:.2f}". format(vote_soft_cv['test_score'].std()*100*3))

四、模型优化
你可以看到,我们在建立分类器对象的时候使用的全部是分类器的默认参数,现在我们来调整分类器的超参数,来取得分类器最好的效果。我们首先创建每个超参数要测试的数组,并依次把对应的超参数按照顺序对应好依次的模型:
# Hyperparameter
grid_n_estimator = [10, 50, 100, 300]
grid_ratio = [.1, .25, .5, .75, 1.0]
grid_learn = [.01, .03, .05, .1, .25]
grid_max_depth = [2, 4, 6, 8, 10, None]
grid_min_samples = [5, 10, .03, .05, .10]
grid_criterion = ['gini', 'entropy']
grid_bool = [True, False]
grid_seed = [0]
grid_param = [
[{
'n_estimators': grid_n_estimator, #default=50
'learning_rate': grid_learn, #default=1
'random_state': grid_seed
}],
[{
'n_estimators': grid_n_estimator, #default=10
'max_samples': grid_ratio, #default=1.0
'random_state': grid_seed
}],
[{
#ExtraTreesClassifier
'n_estimators': grid_n_estimator, #default=10
'criterion': grid_criterion, #default=”gini”
'max_depth': grid_max_depth, #default=None
'random_state': grid_seed
}],
[{
#GradientBoostingClassifier
'learning_rate': [.05],
'n_estimators': [300],
'max_depth': grid_max_depth,
'random_state': grid_seed
}],
[{
#RandomForestClassifier
'n_estimators': grid_n_estimator, #default=10
'criterion': grid_criterion, #default=”gini”
'max_depth': grid_max_depth, #default=None
'oob_score': [True],
'random_state': grid_seed
}],
[{
#GaussianProcessClassifier
'max_iter_predict': grid_n_estimator, #default: 100
'random_state': grid_seed
}],
[{
#LogisticRegressionCV
'fit_intercept': grid_bool, #default: True
#'penalty': ['l1','l2'],
'solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'], #default: lbfgs
'random_state': grid_seed
}],
[{
#BernoulliNB
'alpha': grid_ratio, #default: 1.0
}],
#GaussianNB
[{}],
[{
#KNeighborsClassifier
'n_neighbors': [1,2,3,4,5,6,7], #default: 5
'weights': ['uniform', 'distance'], #default = ‘uniform’
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute']
}],
[{
#SVC
'C': [1,2,3,4,5], #default=1.0
'gamma': grid_ratio, #edfault: auto
'decision_function_shape': ['ovo', 'ovr'], #default:ovr
'probability': [True],
'random_state': grid_seed
}],
[{
#XGBClassifier
'learning_rate': grid_learn, #default: .3
'max_depth': [1,2,4,6,8,10], #default 2
'n_estimators': grid_n_estimator,
'seed': grid_seed
}]
]
下面开始优化的过程,因为我们按照顺序排列好了参数,直接使用Python内置的zip参数就可以让模型和参数两两对应,再使用for循环即可对每个参数进行操作:
start_total = time.perf_counter()
for clf, param in zip (vote_est, grid_param):
start = time.perf_counter()
best_search = model_selection.GridSearchCV(estimator = clf[1], param_grid = param, cv = cv_split, scoring = 'roc_auc')
best_search.fit(train[data_x_bin], train[Target])
run = time.perf_counter() - start
best_param = best_search.best_params_
print('The best parameter for {} is {} with a runtime of {:.2f} seconds.'.format(clf[1].__class__.__name__, best_param, run))
clf[1].set_params(**best_param)
run_total = time.perf_counter() - start_total
print('Total optimization time was {:.2f} minutes.'.format(run_total/60))

我们来看看优化后的投票结果:
#Hard Vote or weighted probabilities w/Tuned Hyperparameters
grid_hard = ensemble.VotingClassifier(estimators = vote_est , voting = 'hard')
grid_hard_cv = model_selection.cross_validate(grid_hard, train[data_x_bin], train[Target], cv = cv_split)
grid_hard.fit(train[data_x_bin], train[Target])
print("Hard Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_hard_cv['test_score'].mean()*100))
print("Hard Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_hard_cv['test_score'].std()*100*3))
#Soft Vote or weighted probabilities w/Tuned Hyperparameters
grid_soft = ensemble.VotingClassifier(estimators = vote_est , voting = 'soft')
grid_soft_cv = model_selection.cross_validate(grid_soft, train[data_x_bin], train[Target], cv = cv_split)
grid_soft.fit(train[data_x_bin], train[Target])
print("Soft Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_soft_cv['test_score'].mean()*100))
print("Soft Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_soft_cv['test_score'].std()*100*3))

最后使用我们的投票模型预测并保存结果即可:
result = pd.DataFrame(columns=["PassengerId","Survived"])
result['Survived'] = grid_hard.predict(test[data_x_bin])
result["PassengerId"] = test_backup["PassengerId"]
result.to_csv("result.csv", index=False)
最终我们的预测结果获得了78.94%的准确率。

四、参考资料
[1]. A Data Science Framework: To Achieve 99% Accuracy
[2]. Python进行泰坦尼克生存预测
[3]. Kaggle Titanic生死率预测















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









