









hive的连接有三种方式,分别是CLI连接、HiveServer2/beeline、web UI,这三种的方式远程连接Hive,但是这篇文章不会一一的介绍这三种方式,我只会着重讲Java采用JDBC的方式去连接Hive,这里我们先了解一下,hive的访问方式。
这里说的是版本号为hive2.3.7的访问方式
Hive
一、Hive的访问方式
Hive的访问方式主要分为两种,一种是本地模式,通常用于单机测
试,另一种是远程连接模式,比较常用。由于我们需要使用idea去
连接hive,所以这里讲的肯定是远程连接模式。
1. 连接虚拟机
我们这里需要使用xshell来连接虚拟机,这里如果是MacBook系
统,可以使用其自带的终端使用ssh roo@【你的虚拟机的用户
名】去远程连接虚拟机,后续的操作主要是在idea中,win和mac
的区别不太大,所以这里着重介绍win 的操作方式。
2. 准备工作
由于这个是2.3.7的版本,所以这个版本的远程连接是有一定区别
的,这里我们先去修改Hive-sete.xml文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.134.154:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 这是hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.134.154</value>
</property>
</configuration>
由于这里的默认的端口号是10000,如果无法使用,那就需要去修改
hadoop中的core-site.xml文件,只需要添加两段话就可以了。
<property>
<name>hadoop.proxyuser.用户组名.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.用户组名.groups</name>
<value>*</value>
</property>
注意这里并不是直接复制进去,对应的用户名需要更改一下。
重启Hadoop
hadoop的 重启就是先关闭在开启即可
./sbin/stop-all.sh
./abin/start-all.sh
开启hiveserver2服务
hive --service metastore &
hive --service hiveserver2 &
这里开通以后我们检查一下是否开启。
netstat -natp|grep ${port}
二、开始连接
连接之前我们需要先安装好maven的包,添加一下hive的依赖,这里无需从官网获取,我直接放在下面,复制进去,自动安装即可。
<!-- 添加hive依赖 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive-version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.aggregate</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop-version}</version>
</dependency>
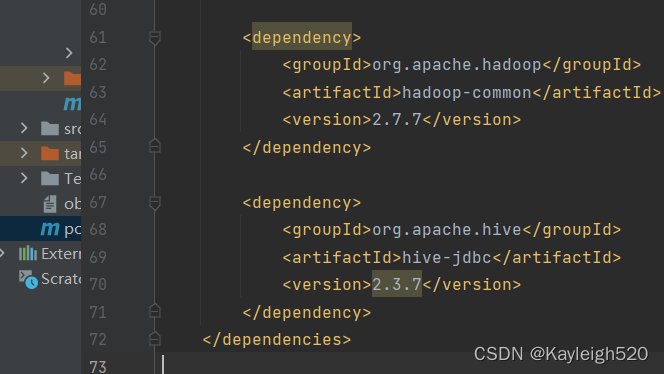
注意,留意看,这里我把hive的版本号给留住了,自己修改一下即可。
三、测试连接
这里不说原理,代码讲解单独在一个文章中去详细的讲解,有需要可以关注我的hive专栏,里面会持续更新
直接上代码
import java.sql.*;
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn = DriverManager.getConnection("jdbc:hive2://master:10000/kayleigh");
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from students_buks_zj limit 10");
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
int age = rs.getInt(3);
String gender = rs.getString(4);
String clazz = rs.getString(5);
System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
}
rs.close();
stat.close();
conn.close();
}
}
四、hive的终端优化
如果我们想在hive的终端看到当前的数据库名,还有在查询结果上面
到列名称,我们这里可以修改一下hive-site.xml文件
这个步骤可选可不选,这里直接把需要修改的放在下面了。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.resultset.use.unique.column.names</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
##五、 问题描述
如果出现了类似如下的报错:
org.apache.thrift.TApplicationException: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null)
很有可能就是项目中的hive-jdbc版本和服务器不一致的原因导致
的,这里我们需要更换这里的文件版本信息就可了。
这个问题初学者应该很容易就有,安装的过程一定要非常的小心
学习大数据除了努力之外,还需要非常细心,一个小小的问题可
能带来的问题都是致命的。

















 8100
8100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











