









一、需求分析
1.1 需求分析
学习 MapReduce 和 HDFS 的知识,基于这些知识实践一个实际的应用,即共同关注查找系统。用户可以提供一个包含用户及其关注列表的数据集,系统会通过 MapReduce 处理这些数据,找到每一位用户两两之间的共同关注。
1.2 需求分析图
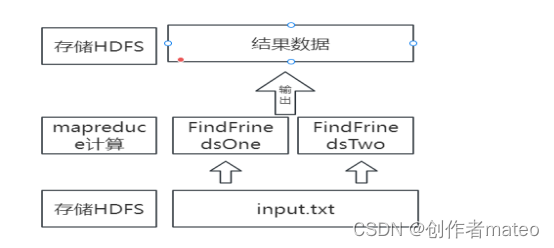
二、编程思路与代码
2.1 Mapper类编程思路
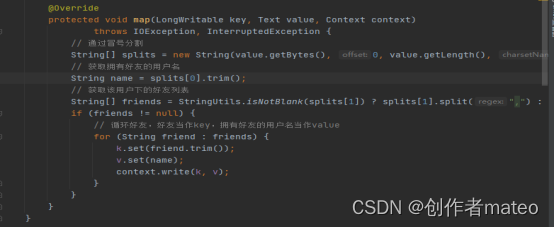
FindFrinedsOne的思路:求两两之间有共同好友,及他俩的共同好友都是谁。例子:张三-谢霆锋:陈奕迅,伊森:即张三和谢霆锋的共同关注有陈奕迅和伊森。把好友当作key,value是拥有key好友的用户,找出拥有张三的所有人员。
FindFrinedsTwo的思路:在第一步结果后,双重for循环进行两两之间进行拼接后实现本项目需求。将计算得到的结果保存在 HDFS 或本地文件系统上,提供给用户查询。
2.2 Mapper类代码说明
FindFrinedsOne:Mapper类,输入数据中的用户及其关注列表进行了处理。通过冒号分割,我们提取出拥有好友的用户名和该用户的好友列表,进一步将每位好友作为键,其所属用户作为值的键值对输出至上下文。这个Mapper类在整个流程中扮演着关键的角色,为后续的数据计算和共同关注的查找奠定了基础。
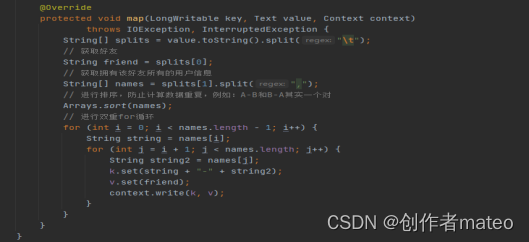
FindFrinedsTwo:Mapper类,该 Mapper 接收了第一阶段输出的数据,通过以制表符分割的方式提取好友信息和拥有该好友的用户列表。为了避免计算中的数据重复,它对用户列表进行了排序。随后,在双重循环的迭代中,该 Mapper 生成了每两个用户之间的共同关注的键值对。其中,键是两个用户的组合,值是它们共同关注的好友。这个过程确保了对于同一组用户,无论出现在哪个位置,都会生成相同的键值对,避免了重复计算。
2.3 Reducer类编程思路
FindFrinedsOne:Reduce类,通过 reduce 方法,它接收到了每位好友及其拥有该好友的用户列表。在处理过程中,它将所有用户列表整合成一个字符串,并与好友的名字连接,形成最终的输出结果。第一阶段 Reducer 类的设计使得最终的输出清晰明了,每一行都表示一位好友及其拥有该好友的用户列表。最后输出的结果的组织形式为第二阶段的处理提供了清晰的输入数据,为计算每两位用户之间的共同关注关系奠定了基础。这样的结果不仅方便后续阶段的处理,也为用户提供了直观且易于理解的信息。
FindFrinedsTwo:Reduce类,通过 reduce 方法,它接收到每两位用户之间的共同关注的键值对,其中键表示两位用户的组合,值是这些用户共同关注的好友列表。在处理过程中,它将所有好友列表整合成一个字符串,并与键连接,形成最终的输出结果。第二阶段 Reducer 类的设计使得最终的输出清晰明了,每一行都表示两位用户之间的共同关注关系,以及这些用户共同关注的好友列表。这种结果的组织形式方便后续的查询与分析,为用户提供了直观且易于理解的共同关注信息。
2.4 Reducer类代码说明
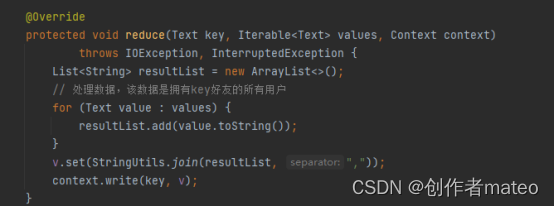
定义了 Text 类型的变量 v 作为输出的值。reduce 方法是 MapReduce 中的 Reducer 阶段的核心方法。Text, Text, Text, Text 表示输入和输出的键值对的类型。在 reduce 方法中,接收到的 key 是第一阶段 Mapper 阶段生成的好友关系,values 则是拥有这位好友的所有用户。
通过循环遍历 values,将拥有同一好友的用户列表整合为一个字符串。使用 StringUtils.join 方法将用户列表连接为一个字符串,以逗号分隔。将生成的字符串与 key 连接,并输出到上下文。这样,最终的输出就是每位好友及其拥有该好友的用户列表。
定义了 Text 类型的变量 k 作为输出的键。使用 NullWritable 表示输出的值为 null(因为我们只关心键),reduce 方法是 MapReduce 中的 Reducer 阶段的核心方法。Text, Text, Text, NullWritable 表示输入和输出的键值对的类型。在 reduce 方法中,接收到的 key 是第二阶段 Mapper 阶段生成的用户组合,values 则是这两位用户共同关注的好友。
通过循环遍历 values,将共同关注的好友列表整合为一个字符串。使用 StringUtils.join 方法将共同关注的好友列表连接为一个字符串,以逗号分隔。将生成的字符串与 key 连接,并输出到上下文。这样,最终的输出就是每两位用户组合及其共同关注的好友列表的字符串。
三、数据流程
3.1 第一阶段(共同好友查找的第一个 MapReduce 任务):
3.1.1 Mapper 阶段:
输入键值对:
K(键):LongWritable(行偏移量),V(值):Text(每行文本)。
处理过程:Mapper 通过解析每行文本,提取用户及其关注列表,生成键值对。其中K:Text(用户),V:Text(关注列表)。
输出键值对:K:Text(好友),V:Text(拥有该好友的用户)。
3.1.2 Reducer 阶段:
输入键值对:K:Text(好友),V:Iterable
处理过程:Reducer 将拥有同一好友的用户列表整合为一个字符串。其中K:Text(好友),V:Text(拥有该好友的用户列表)。
输出键值对:K:Text(好友),V:Text(拥有该好友的用户列表字符串)。
3.2 第二阶段(共同好友查找的第二个 MapReduce 任务):
3.2.1 Mapper 阶段:
输入键值对:K:Text(好友),V:Text(拥有该好友的用户列表字符串)。
处理过程:Mapper 解析输入,生成每两位用户之间的组合和共同关注好友列表。K:Text(用户组合),V:Text(共同关注好友)。
输出键值对:K:Text(用户组合),V:Text(共同关注好友)。
3.2.2 Reducer 阶段:
输入键值对:K:Text(用户组合),V:Iterable
处理过程:Reducer 将共同关注好友列表整合为一个字符串。K:Text(用户组合),V:NullWritable(用于标识没有实际值)。
输出键值对:K:Text(用户组合),V:NullWritable。
输出结果:
四、项目总结
目的:
第一阶段的目的是统计每个用户的关注列表,并整合为键值对。第二阶段的目的是计算每两位用户之间的共同关注好友,并整合为键值对。
数据类型变化:
在第一阶段,键值对的变化是从用户和关注列表到好友和拥有该好友的用户列表字符串。在第二阶段,键值对的变化是从好友和拥有该好友的用户列表字符串到用户组合和共同关注好友列表。
这样的设计和变化使得整个 MapReduce 过程在不同阶段能够有效地处理数据,从而实现了共同好友查找系统的功能。
详细代码:
数据集:
张三:谢霆锋,陈奕迅,邓昊天,风清扬,伊森,奥布莱恩
谢霆锋:张三,陈奕迅,伊森,柯南
陈奕迅:张三,谢霆锋,邓昊天,伊森,艾弗森
邓昊天:张三,伊森,风清扬,李世民
伊森:谢霆锋,陈奕迅,邓昊天,莫言,李世民
风清扬:张三,谢霆锋,陈奕迅,邓昊天,伊森,奥布莱恩,莫言
乔治:张三,陈奕迅,邓昊天,伊森,风清扬
何仙姑:张三,陈奕迅,邓昊天,伊森,奥布莱恩
艾弗森:张三,奥布莱恩
姜东南:谢霆锋,奥布莱恩
柯南:张三,陈奕迅,邓昊天
李世民:邓昊天,伊森,风清扬
莫言:伊森,风清扬,乔治
奥布莱恩:张三,何仙姑,艾弗森,姜东南
package com.gyx.mr;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; // 添加导入语句
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CommonFriendStepOne {
static class CommonFriendStepOneMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 通过冒号分割
String[] splits = new String(value.getBytes(), 0, value.getLength(), "UTF-8").split(":");
// 获取拥有好友的用户名
String name = splits[0].trim();
// 获取该用户下的好友列表
String[] friends = StringUtils.isNotBlank(splits[1]) ? splits[1].split(",") : null;
if (friends != null) {
// 循环好友,好友当作key,拥有好友的用户名当作value
for (String friend : friends) {
k.set(friend.trim());
v.set(name);
context.write(k, v);
}
}
}
}
static class CommonFriendStepOneReducer extends Reducer<Text, Text, Text, Text> {
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
List<String> resultList = new ArrayList<>();
// 处理数据,该数据是拥有key好友的所有用户
for (Text value : values) {
resultList.add(value.toString());
}
v.set(StringUtils.join(resultList, ","));
context.write(key, v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CommonFriendStepOne.class);
// 指定本业务job要使用的业务类
job.setMapperClass(CommonFriendStepOneMapper.class);
job.setReducerClass(CommonFriendStepOneReducer.class);
// 指定mapper输出的k v类型 如果map的输出和reduce的输出一样,只需要设置输出即可
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 指定最终输出kv类型(reduce输出类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定job的输入文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setInputFormatClass(TextInputFormat.class); // 添加这一行
// 指定job的输出结果目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将job中配置的相关参数,以及job所有的java类所在 的jar包,提交给yarn去运行
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
输出结果:
乔治 莫言
伊森 乔治,张三,何仙姑,谢霆锋,莫言,陈奕迅,李世民,邓昊天,风清扬
何仙姑 奥布莱恩
奥布莱恩 何仙姑,张三,风清扬,姜东南,艾弗森
姜东南 奥布莱恩
张三 风清扬,奥布莱恩,何仙姑,谢霆锋,柯南,陈奕迅,乔治,邓昊天,艾弗森
李世民 邓昊天,伊森
柯南 谢霆锋
艾弗森 奥布莱恩,陈奕迅
莫言 伊森,风清扬
谢霆锋 张三,姜东南,风清扬,伊森,陈奕迅
邓昊天 伊森,李世民,乔治,何仙姑,柯南,风清扬,张三,陈奕迅
陈奕迅 张三,柯南,伊森,乔治,谢霆锋,何仙姑,风清扬
风清扬 莫言,张三,李世民,乔治,邓昊天
package com.gyx.mr;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; // 添加导入语句
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CommonFriendStepTwo {
static class CommonFriendStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] splits = value.toString().split("\t");
// 获取好友
String friend = splits[0];
// 获取拥有该好友所有的用户信息
String[] names = splits[1].split(",");
// 进行排序,防止计算数据重复,例如:A-B和B-A其实一个对
Arrays.sort(names);
// 进行双重for循环
for (int i = 0; i < names.length - 1; i++) {
String string = names[i];
for (int j = i + 1; j < names.length; j++) {
String string2 = names[j];
k.set(string + "-" + string2);
v.set(friend);
context.write(k, v);
}
}
}
}
static class CommonFriendStepTwoReducer extends Reducer<Text, Text, Text, NullWritable> {
Text k = new Text();
@Override
protected void reduce(Text key, Iterable<Text> value, Context context)
throws IOException, InterruptedException {
List<String> resultList = new ArrayList<>();
for (Text text : value) {
resultList.add(text.toString());
}
k.set(key.toString() + ":" + StringUtils.join(resultList, ","));
context.write(k, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CommonFriendStepTwo.class);
// 指定本业务job要使用的业务类
job.setMapperClass(CommonFriendStepTwoMapper.class);
job.setReducerClass(CommonFriendStepTwoReducer.class);
// 指定mapper输出的k v类型 如果map的输出和reduce的输出一样,只需要设置输出即可
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 指定最终输出kv类型(reduce输出类型)
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 指定job的输入文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setInputFormatClass(TextInputFormat.class); // 添加这一行
// 指定job的输出结果目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将job中配置的相关参数,以及job所有的java类所在 的jar包,提交给yarn去运行
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
乔治-伊森:陈奕迅,邓昊天
乔治-何仙姑:邓昊天,陈奕迅,张三,伊森
乔治-奥布莱恩:张三
乔治-张三:邓昊天,风清扬,伊森,陈奕迅
乔治-李世民:邓昊天,风清扬,伊森
乔治-柯南:邓昊天,张三,陈奕迅
乔治-艾弗森:张三
乔治-莫言:伊森,风清扬
乔治-谢霆锋:陈奕迅,张三,伊森
乔治-邓昊天:伊森,风清扬,张三
乔治-陈奕迅:伊森,张三,邓昊天
乔治-风清扬:伊森,邓昊天,陈奕迅,张三
伊森-何仙姑:邓昊天,陈奕迅
伊森-姜东南:谢霆锋
伊森-张三:邓昊天,陈奕迅,谢霆锋
伊森-李世民:邓昊天
伊森-柯南:陈奕迅,邓昊天
伊森-谢霆锋:陈奕迅
伊森-邓昊天:李世民
伊森-陈奕迅:邓昊天,谢霆锋
伊森-风清扬:谢霆锋,邓昊天,莫言,陈奕迅
何仙姑-奥布莱恩:张三
何仙姑-姜东南:奥布莱恩
何仙姑-张三:陈奕迅,伊森,奥布莱恩,邓昊天
何仙姑-李世民:伊森,邓昊天
何仙姑-柯南:邓昊天,陈奕迅,张三
何仙姑-艾弗森:奥布莱恩,张三
何仙姑-莫言:伊森
何仙姑-谢霆锋:陈奕迅,张三,伊森
何仙姑-邓昊天:伊森,张三
何仙姑-陈奕迅:伊森,张三,邓昊天
何仙姑-风清扬:伊森,奥布莱恩,陈奕迅,邓昊天,张三
奥布莱恩-柯南:张三
奥布莱恩-艾弗森:张三
奥布莱恩-谢霆锋:张三
奥布莱恩-邓昊天:张三
奥布莱恩-陈奕迅:张三,艾弗森
奥布莱恩-风清扬:张三
姜东南-张三:奥布莱恩,谢霆锋
姜东南-艾弗森:奥布莱恩
姜东南-陈奕迅:谢霆锋
姜东南-风清扬:奥布莱恩,谢霆锋
张三-李世民:风清扬,伊森,邓昊天
张三-柯南:陈奕迅,邓昊天
张三-艾弗森:奥布莱恩
张三-莫言:伊森,风清扬
张三-谢霆锋:伊森,陈奕迅
张三-邓昊天:伊森,风清扬
张三-陈奕迅:伊森,邓昊天,谢霆锋
张三-风清扬:邓昊天,伊森,陈奕迅,谢霆锋,奥布莱恩
李世民-柯南:邓昊天
李世民-莫言:伊森,风清扬
李世民-谢霆锋:伊森
李世民-邓昊天:风清扬,伊森
李世民-陈奕迅:邓昊天,伊森
李世民-风清扬:伊森,邓昊天
柯南-艾弗森:张三
柯南-谢霆锋:陈奕迅,张三
柯南-邓昊天:张三
柯南-陈奕迅:邓昊天,张三
柯南-风清扬:陈奕迅,邓昊天,张三
艾弗森-谢霆锋:张三
艾弗森-邓昊天:张三
艾弗森-陈奕迅:张三
艾弗森-风清扬:奥布莱恩,张三
莫言-谢霆锋:伊森
莫言-邓昊天:风清扬,伊森
莫言-陈奕迅:伊森
莫言-风清扬:伊森
谢霆锋-邓昊天:张三,伊森
谢霆锋-陈奕迅:伊森,张三
谢霆锋-风清扬:伊森,张三,陈奕迅
邓昊天-陈奕迅:张三,伊森
邓昊天-风清扬:张三,伊森
陈奕迅-风清扬:张三,谢霆锋,邓昊天,伊森

















 1529
1529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











