






目录
1. IoU(Intersection over Union):
第一步:将VOC07测试集的XML文件转换为COCO支持的JSON文件格式
我们都知道目标检测领域有自己的评价指标MAP,表示计算每个类别上的AP(Average Precision)的结果,最后求取平均值得到MAP。但是像COCO大型的目标检测数据集有自己的MAP评价工具pycocotools,由于COCO是80个类别,如果要将这个工具应用到自己的领域,比如自定义了各个类别的数据集或者像20个类别VOC数据集,该怎么做呢?
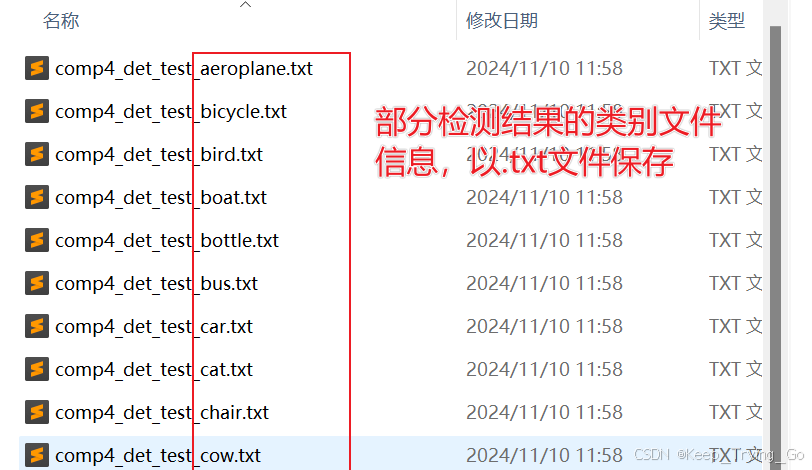
如果能用pycocotools工具的话,那么将不需要手写很多细节代码,并且这些细节是非常用错的,因此这篇文章以VOC作为例子,将VOC07的测试集转换为COCO支持的格式JSON,并利用RefineDet检测模型对VOC07测试集检测得到的结果保存到.txt文件中(注意这里是保存每一个类别的文件,也就是会得到20个文件)。最后的评估结果如下:
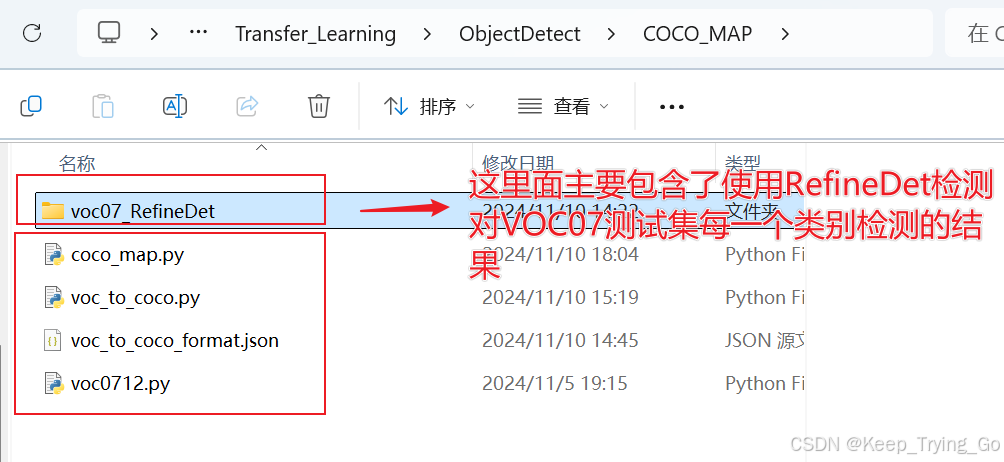
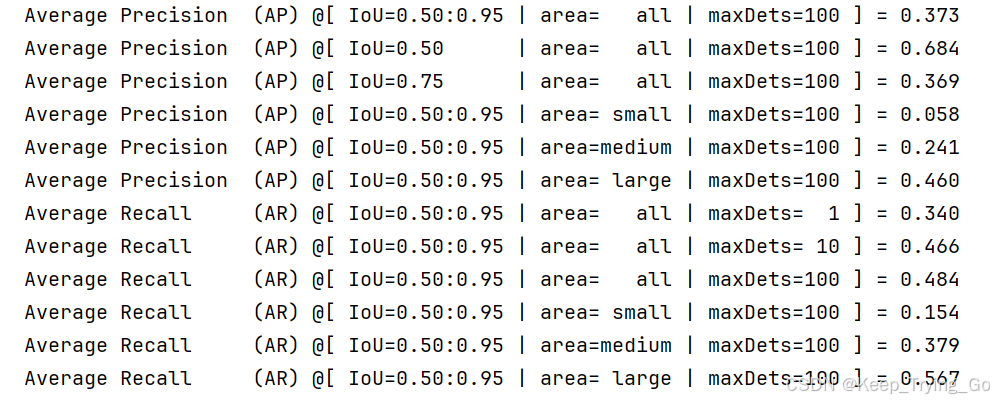
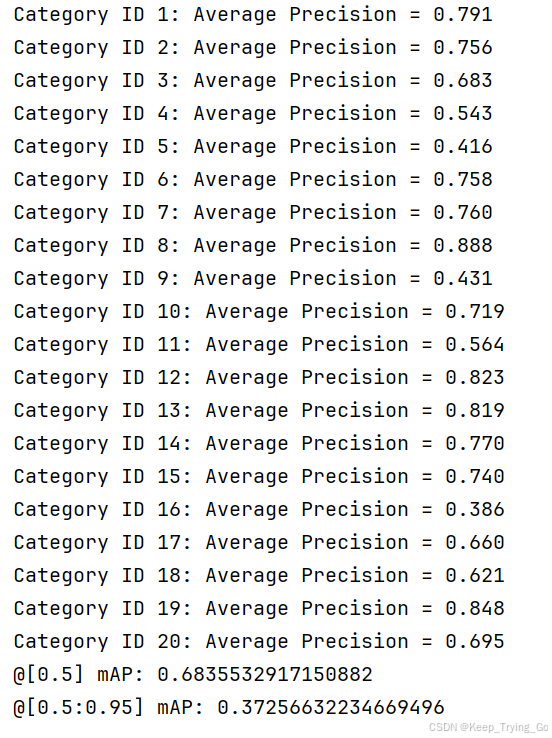
这里我自己打印了在IOU=0.5时的每个检测结果AP。
注意事项
-
pycocotools工具是用于COCO目标检测的MAP评估,因此如果要使用VOC的结果结合该pycocotools工具的话,需要将VOC的测试集XML文件以及检测的结果转换为COCO格式(不用担心,这一步在代码实现上并没有很难理解);
- COCO数据集是80个类别,如果直接将20类别的VOC转换为COCO格式并使用pycocotools工具进行评估的话需要注意这个类别索引问题,但是不用担心,因为将VOC的测试集转换为COCO支持的JSON格式之后,并使用pycocotools工具加载JSON文件,里面就已经包含了20个类别信息,不需要再去手动的修改之类的;
- 这一点以RefineDet训练模型为例,由于我们在将RefineDet模型检测的结果坐标保存为[xmin,ymin,xmax,ymax],但是使用pycocotools工具进行评估,需要将坐标转换为[xmin,ymin,xmax-xmin,ymax-ymin]=[xmin,ymin,w,h]格式。
- 最后一点,也许在使用RefineDet中的代码计算MAP结果(设置的IOU=0.5)时,发现使用pycocotools工具检测的结果比RefineDet中的代码计算MAP结果要低,这个不用惊奇,个人认为pycocotools工具计算的结果应该更加准确,并且最后我还打印了各个类别的检测结果(IOU=0.5)。
前置了解
1. IoU(Intersection over Union):
- mAP 通常通过不同的 IoU 阈值来评估。其中IoU=0.50 和 IoU=0.75 是不同的 IoU 阈值,用于判定检测框与真实框的重叠程度。在 COCO 中,IoU 是一个关键指标,检测框与真实框的重叠部分与它们的联合面积的比值。
2.Average Precision (AP):
- AP@ IoU=0.50: 当 IoU ≥ 0.50 时,计算该类别的 Average Precision。
- AP@ IoU=0.75: 当 IoU ≥ 0.75 时,计算该类别的 Average Precision
- AP@[IoU=0.50:0.95]: 计算从 0.50 到 0.95 的所有 IoU 阈值下的平均值,考虑了不同 IoU 为基础的精度曲线,并取其均值。
3. Average Recall (AR):
平均召回率通过在不同的最大检测数量(如 `maxDets=1`, `maxDets=10`, `maxDets=100`)下计算召回率来获得。它表示检测模型在不同检测数量情况下的表现。
4. mAP 计算:
最终的 mAP 是对所有 AP 值取平均。其中[0.5:0.95]表示是基于各个 IoU 阈值下计算的 AP。
mAP 通过综合考虑不同的 IoU 阈值和检测框数量,从多个角度评估模型的表现。
mAP 的高低反映了模型整体检测的准确性和召回能力,通常来说,越高越好。
具体实现流程
第一步:将VOC07测试集的XML文件转换为COCO支持的JSON文件格式
COCO格式的基础结构
# TODO COCO格式的基础结构
coco_output = {
"images": [],
"annotations": [],
"categories": []
}根据VOC类别保存每个类别索引
VOC_CLASSES = (
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
#TODO 将类别名称和索引对应起来(索引从1开始)
for id, category in enumerate(VOC_CLASSES, start=1):
category_dict[category] = id
coco_output["categories"].append({
"id": id,
"name": category,
"supercategory": "none",
})保存图像信息
coco_output["images"].append({
"id": image_id,
"file_name": filename,
"width": width,
"height": height,
})保存当前图像的物体信息
coco_output["annotations"].append({
"id": annotation_id,
"image_id": image_id,
"category_id": category_id,
"bbox": [xmin, ymin, xmax - xmin, ymax - ymin],
"area": (xmax - xmin) * (ymax - ymin),
"iscrowd": 0,
})注:这里只列出核心部分数据结构,最后是将所有信息保存为一个JSON文件。
第二步:读取检测的每个类别文件信息
注:我这里已经使用RefineDet模型将检测结果保存到.txt文件中,在源码中有,关于RefineDet代码以及训练请看上面给出的博文链接。
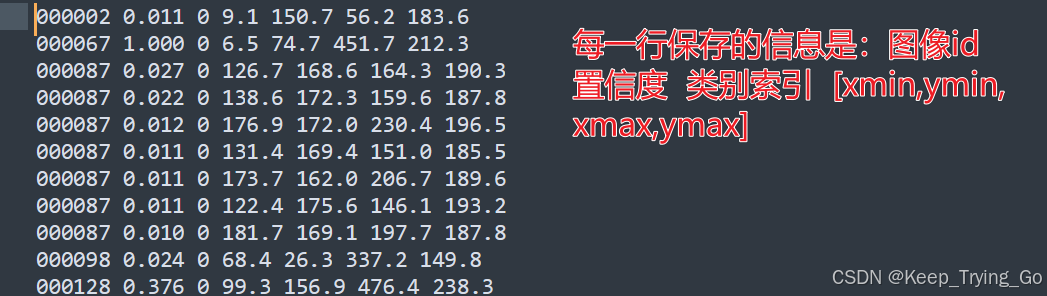
def readClsFiles():
# TODO 将 detections 转换为 COCO 格式
results = []
root = r'voc07_RefineDet'
#TODO 遍历每一个检测结果类别文件
for clsName in os.listdir(root):
result_path = os.path.join(root,clsName)
with open(result_path,'r',encoding='utf-8') as fp:
lines = fp.readlines()
for line in lines:
det = line.strip().split(' ')
image_id, score, class_id, xmin,ymin,xmax,ymax = det[0],det[1],det[2],det[3],det[4],det[5],det[6]
# TODO COCO bbox 是 [xmin, ymin, xmax, ymax] => [xmin,ymin,w,h]
bbox = [int(float(xmin)),int(float(ymin)),
int(float(xmax)) - int(float(xmin)),
int(float(ymax)) - int(float(ymin))]
results.append({
'image_id': str(image_id),
'category_id': int(class_id) + 1, #TODO 注意类别索引设置是从1开始的
'bbox': bbox,
'score': float(score),
})
return results特别要注意这里的数据结构形式:
results.append({
'image_id': str(image_id),
'category_id': int(class_id) + 1, #TODO 注意类别索引设置是从1开始的
'bbox': bbox,
'score': float(score),
})#TODO 加载 COCO 数据集的注释文件
coco = COCO('voc_to_coco_format.json')
#TODO 假设 detections 是你模型的输出结果,包含 [image_id, bbox, score, class_id]
#TODO 结构:image_id: str(这个类型根据测试集中id类型来写即可), bbox: [xmin, ymin, width, height], score: float, class_id: int
detections = [
# TODO 注意我们这里给出的image_id编号应该是在测试集中出现的,并且是符合测试集中编号格式
# 不然报错 AssertionError: Results do not correspond to current coco set
["000001", [100, 100, 50, 50], 0.9, 1],
["000002", [110, 110, 50, 50], 0.75, 1],
]第三步:计算MAP以及每个类别的AP打印
def compute_map():
results = readClsFiles()
# TODO 将结果添加到 COCO,没有实际的 COCO 数据格式,因此使用 COCO的 "results" 格式
coco_results = coco.loadRes(results)
# TODO 评估结果
coco_eval = COCOeval(coco, coco_results, 'bbox')
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
# TODO 获取每个类别的 AP(在类别数量与 coco_gt.getCatIds() 一一对应)
precision_per_category = coco_eval.eval['precision']
average_precisions = {}
#TODO 在加载的 JSON 文件的 categories 字段中,包含了数据集中定义的所有类别。
for i, cat_id in enumerate(coco.getCatIds()):
ap = precision_per_category[0, :, i, 0, -1]
average_precisions[cat_id] = ap.mean()
#TODO 输出每个类别上的AP
sum_ap = 0
for cat_id, ap_value in average_precisions.items():
print(f"Category ID {cat_id}: Average Precision = {ap_value:.3f}")
sum_ap += ap_value
print('@[IOU=0.5] mAP: {}'.format(sum_ap / len(coco.getCatIds())))
# TODO 输出 mAP
mAP = coco_eval.stats[0] # mAP@IoU=0.50:0.95
print(f'@[IOU=0.5:0.95] mAP: {mAP}')完整代码请看前面给出的代码下载地址 ,里面包含了不仅仅是这个MAP的计算,以及一些目标检测算法的实现也有。
如果有用的话,记得点个赞呀!☺。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









