









论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
之所以这里会着重区分“Reference-less Counting,Zero-shot Counting,Few-shot Counting,单元域泛化以及域自适应”这个五个概念的区别,是因为真的很重要。我们在学习的过程中经常容易把这些问题给搞混淆,而恰恰这些概念又是非常重要的,那么我们在给被人讲述,写东西或者自己看论文的时候也容易犯糊涂。因此,这篇博文着重把这几个概念加入进来,当然,最后,我们也会探讨“全监督,半监督,开发世界识别和开发词汇识别”,关于参考过的文章和链接在这篇博文最后引用了。生面例举出来的几篇文章是我们已经讲解的,其中就涉及到了“零样本以及全监督”问题,建议大家去看一下他们的实现方式。
声明:个人在写这篇博文的时候参考链接放在了最后或者也搜索一点模型,关于模型搜索出来的结果是否存在“幻觉”,大家需要自己去辨认。
目录
一 概念区别
| 方法 | 核心目标 | 数据依赖 | 适用场景 |
| Reference-less Counting | 无需任何参考示例,直接计数图像中的物体(依赖通用特征或启发式规则)(但是训练的时候还是需要标签作为损失更新模型的)。 | ❌ 无参考信息 | 通用物体计数(如人群、车辆),无需特定类别先验。 |
| Zero-shot Counting (ZSC) | 计数训练中未见过的新类别,依赖语义信息(如类别名称或文本描述)(但是训练的时候还是需要标签作为损失更新模型的)。 | ❌ 无目标类别标注 | 新商品盘点、稀有物种监测等开放世界场景。 |
| Few-shot Counting | 通过极少量参考示例(如1~5张标注图像)计数新类别(但是训练的时候还是需要标签作为损失更新模型的)。 | ⭕ 少量目标类别参考 | 数据稀缺场景(如医学细胞计数),需快速适应新类别。 |
| 单域泛化 (SDG) | 在单一源域上训练,泛化到未知的多个目标域(域偏移)(但是训练的时候还是需要标签作为损失更新模型的)。 | ❌ 仅单一源域数据 | 模型需部署到未知环境(如自动驾驶在不同天气下的鲁棒性)。 |
| 域自适应 (DA) | 利用源域数据和无标签(或少量标签)目标域数据,对齐分布以减少域偏移(但是训练的时候还是需要标签作为损失更新模型的)。 | ⭕ 需目标域数据(无监督DA可无标签) | 跨设备/场景迁移(如合成数据→真实数据)。 |
二 从图解来说明区别
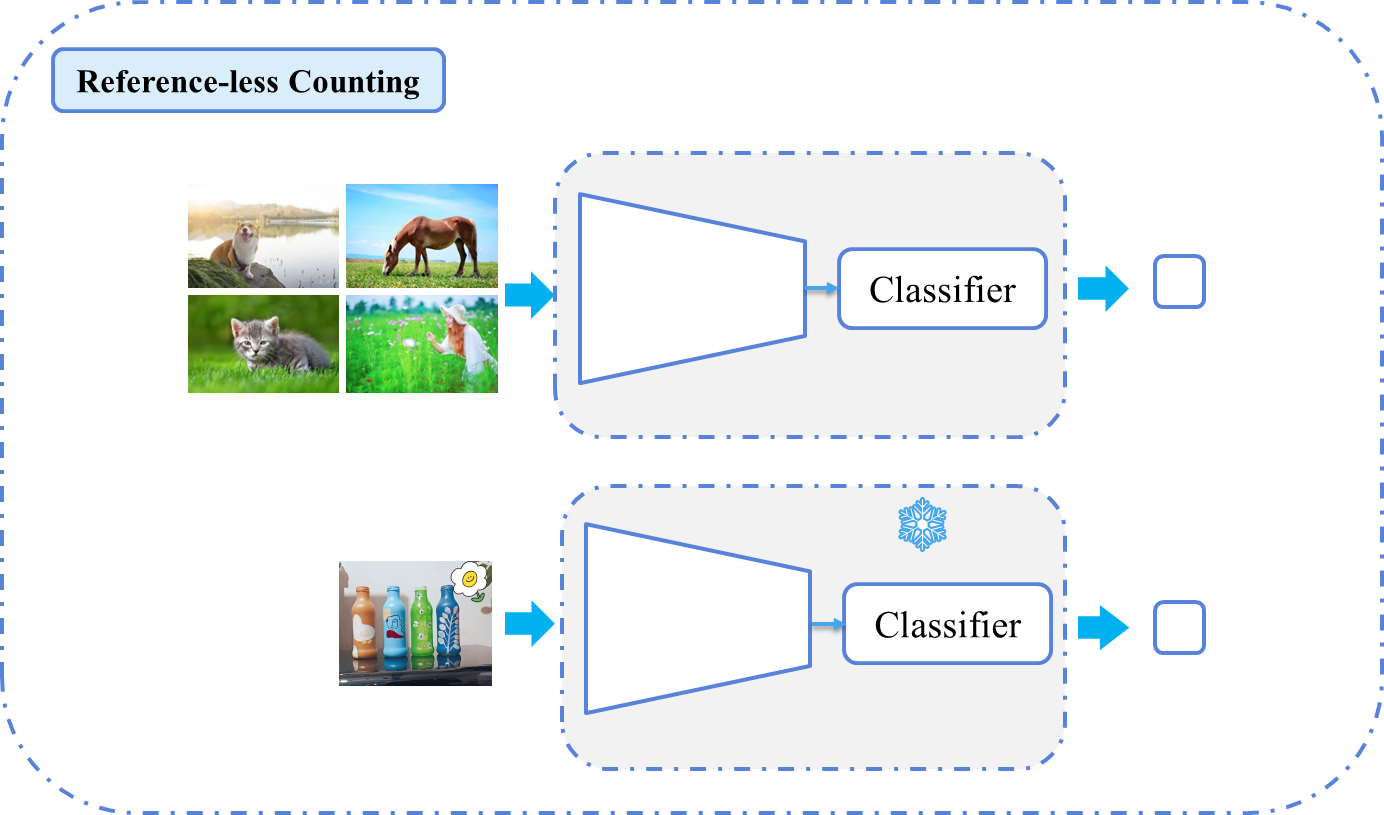
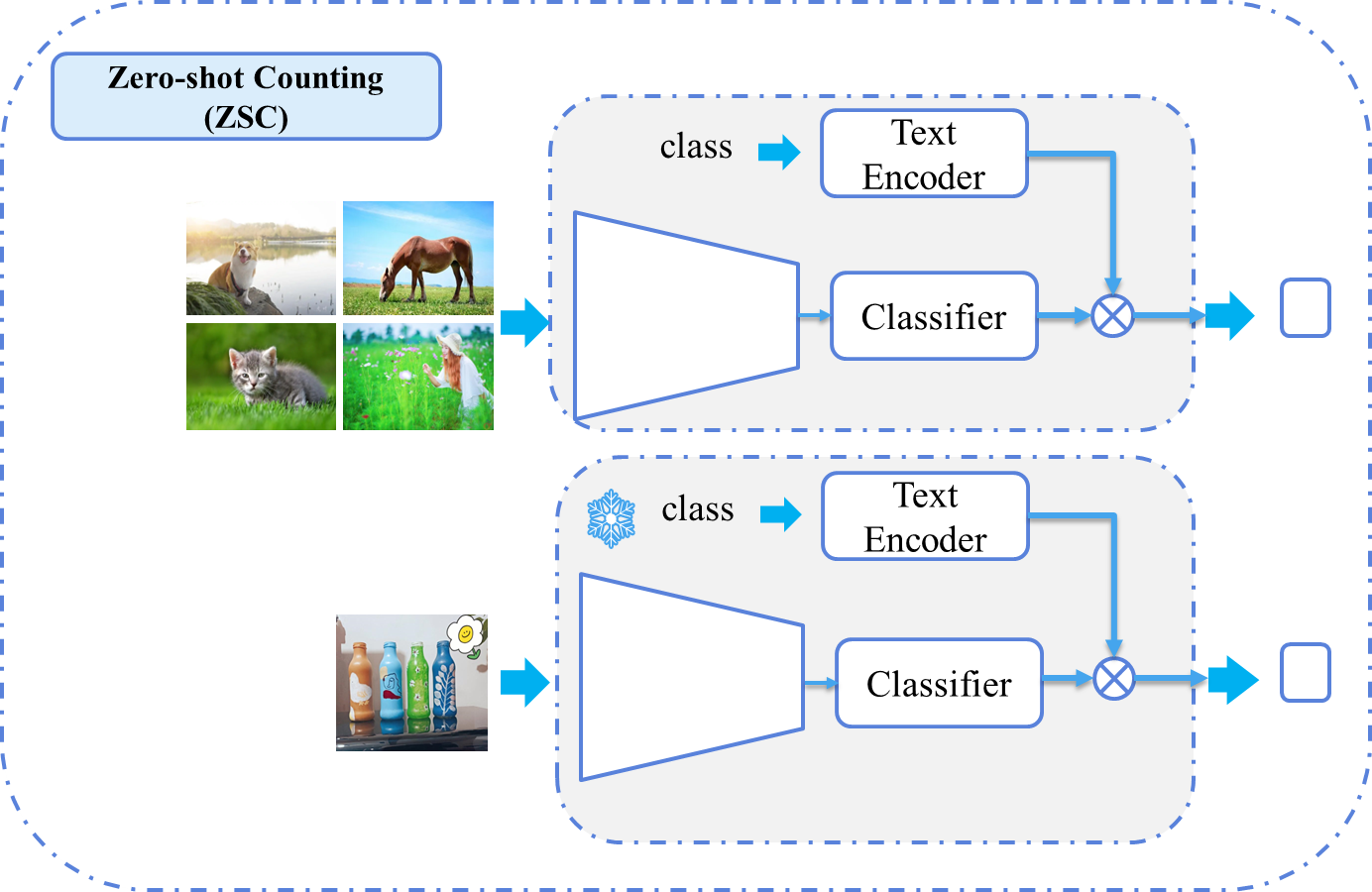
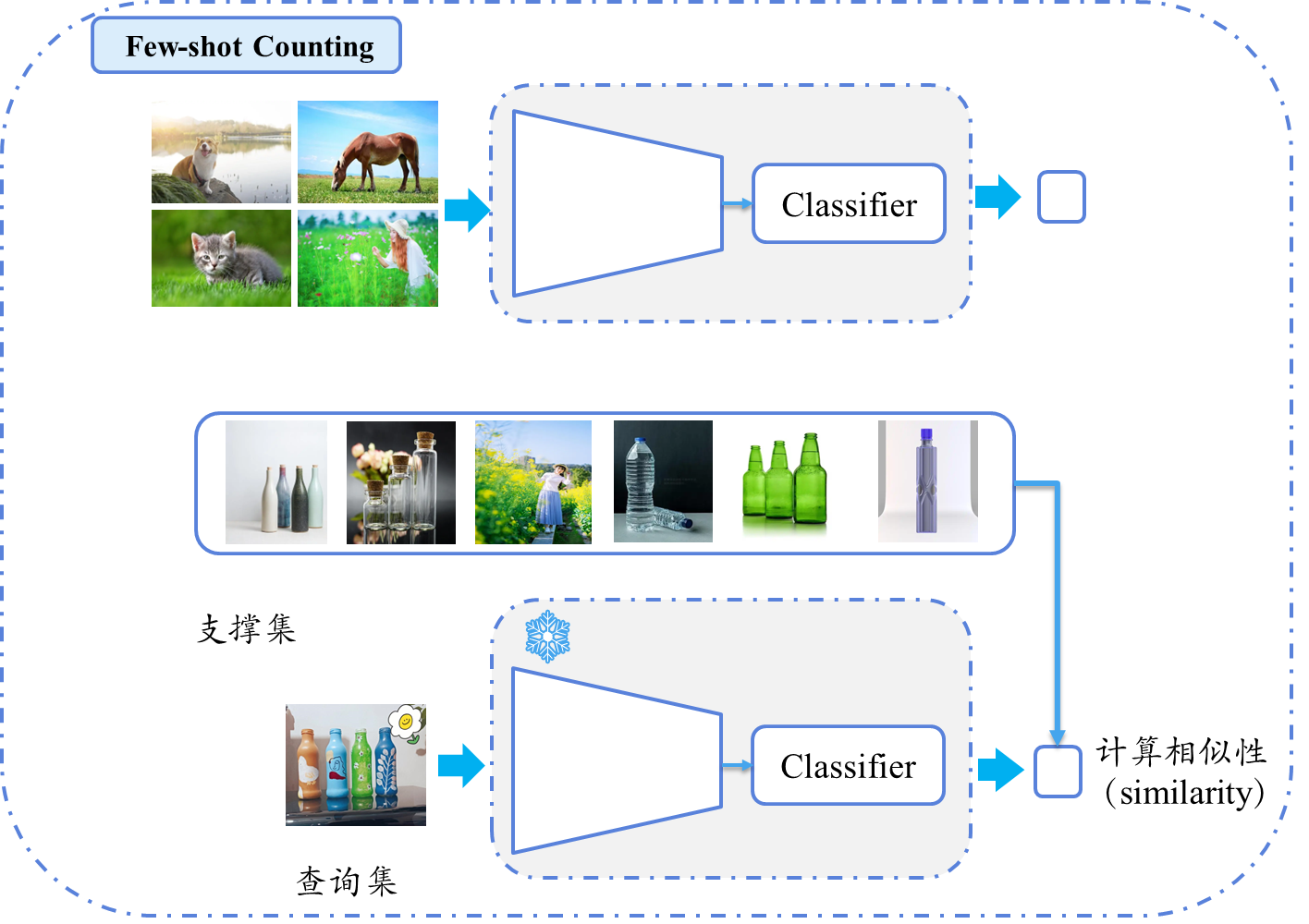
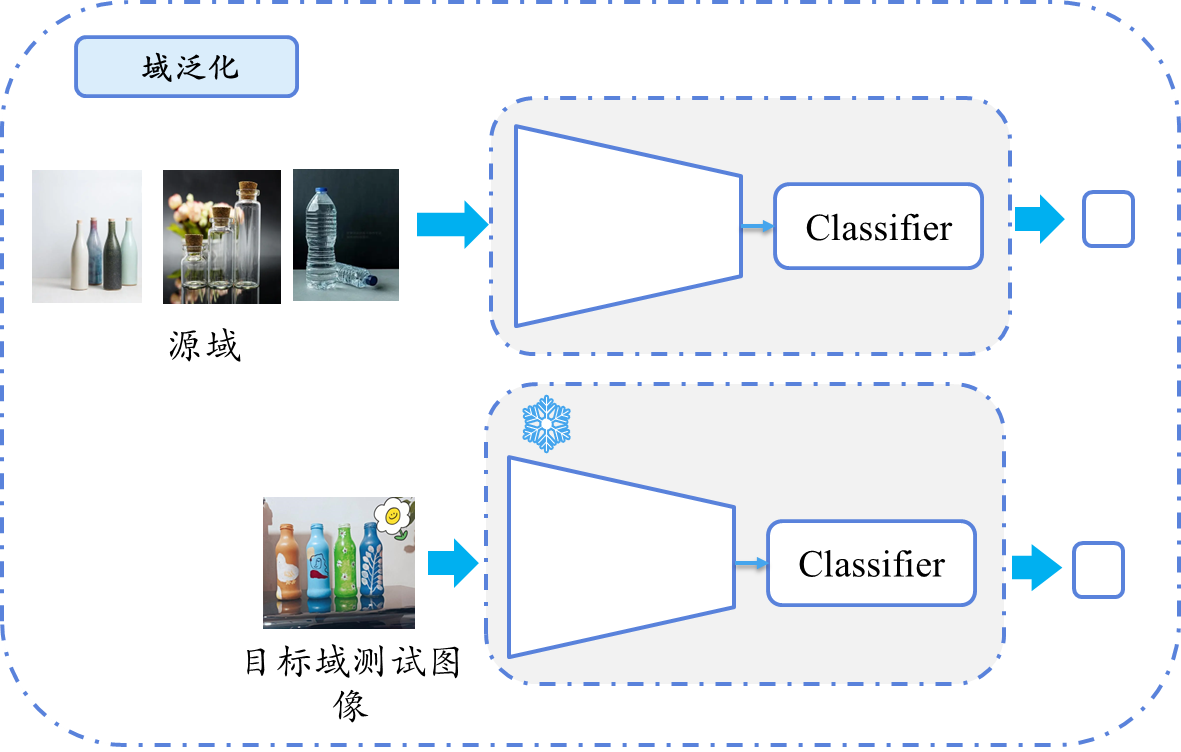
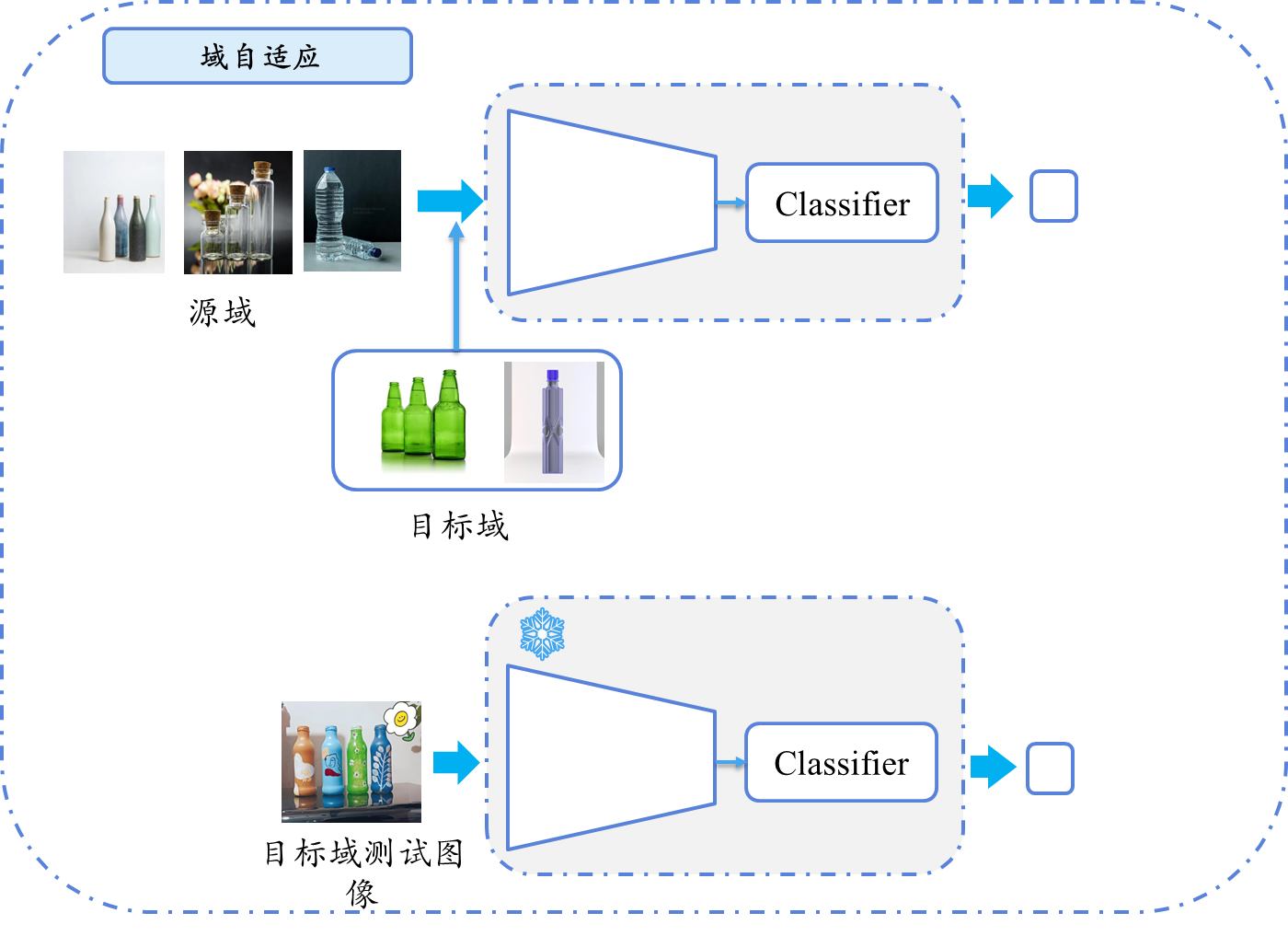
三 使用方法上的区别
| 方法 | 典型技术 | 挑战 |
| Reference-less | • 密度图回归(如MCNN) | 难以区分相似背景的物体,依赖手工特征。 |
| Zero-shot | • 多模态对齐(CLIP + 文本提示) | 依赖预训练模型的语义泛化能力,对新类别描述敏感。 |
| Few-shot | • 度量学习(如匹配网络) | 参考示例过少可能导致计数偏差。 |
| 单域泛化 | • 对抗生成(如StyleGAN) DCCUS[1]和MPCount[2]方法 | 仅用单一域数据模拟多样性困难。 |
| 域自适应 | • 域对齐(MMD/CORAL) | 需目标域数据,无监督DA易受噪声影响。 |
四 使用场景上的区别
| 场景 | 适用方法 | 原因 |
| 商场人流统计 | Reference-less Counting | 无需知道行人具体身份,直接估计密度。 |
| 新品上架商品计数 | Zero-shot Counting | 新商品无历史数据,但可通过文本描述(如“蓝色保温杯”)定位。 |
| 病理细胞计数 | Few-shot Counting | 标注成本高,但可提供少量示例快速适配。 |
| 自动驾驶跨天气泛化 | 单域泛化 (SDG) | 训练数据仅为晴天,需泛化到雨雪天气。 |
| 合成数据训练→真实测试 | 域自适应 (DA) | 合成数据与真实数据存在分布差异,需对齐特征。 |
五 具体需求上的应用
| 需求 | 推荐方法 |
| 无先验信息,直接计数 | Reference-less Counting |
| 新类别计数,仅有语义描述 | Zero-shot Counting |
| 新类别计数,有少量标注示例 | Few-shot Counting |
| 单一训练域,需泛化到未知环境 | 单域泛化 (SDG) |
| 源域与目标域数据分布不同但部分相关 | 域自适应 (DA) |
六 总结
从上面给出的区别来看,它们的共同点是都是在带有标签的数据集上进行训练的。至于在测试的场景中,可以从使用的样本数量,是否有文本监督指导或者测试目标的场景不同来判断。各自的方法都有不同的应用,因此,不能单纯的从方法或者应用场景来判断它们优劣。
七 拓展
1 Few-shot中怎么从少量图像中学习泛化
对于Few-shot: 论文下载地址:https://arxiv.org/pdf/2104.08391v1
(1) 训练阶段
- 需要标签:模型在训练时使用 带标注的支撑集(support set) 和 查询集(query set),学习如何从少量样本中泛化。
- 支撑集:包含少量参考图像(exemplars)及其标注(如点标注、密度图或计数标签)。
- 查询集:与支撑集同分布的目标图像,用于监督模型适应新类别/场景的能力。
- 目标:通过元学习(Meta-Learning)或参数优化,使模型能够快速适应未见过的类别/场景。
(2) 推理(测试)阶段
- 输入:
- 支撑集(Few-shot Exemplars):测试时提供的少量参考样本(如1~5张带标注的图像)。
- 查询图像:待计数的目标图像(无需标注)。
- 关键操作:
- 无需梯度更新(主流方法):大多数Few-shot Counting模型(如FamNet、CFOCNet)通过前馈方式提取支撑集特征,与查询图像特征匹配,直接预测计数结果,不涉及测试时的反向传播。
- 测试时微调(少数方法):部分方法(如基于优化的元学习)可能在测试时对模型部分参数进行少量梯度更新,但计算代价较高,并非主流。
2 有监督,半监督和无监督方法区别
| 维度 | 有监督方法 | 半监督方法 | 无监督方法 |
| 标签需求 | 需大量精确标注(点标注、密度图) | 少量标注 + 大量无标注数据 | 完全无需人工标注 |
| 训练信号 | 直接最小化预测与标签的误差(MSE/MAE) | 标注数据监督 + 无标注数据正则化/一致性约束 | 依赖数据内在结构(聚类、生成对抗、自相似性) |
| 典型技术 | CSRNet、MCNN | Mean Teacher、伪标签 | CrowdGAN、自监督预训练 |
| 适用场景 | 标注成本低的高精度场景(医学细胞计数) | 标注有限但需平衡性能(监控摄像头人群计数) | 标注不可获取(野生动物监测) |
| 优势 | 精度高、模型收敛快 | 平衡标注成本与性能 | 零标注成本、开放类别支持 |
| 劣势 | 标注成本高、领域迁移差 | 需设计无标注数据利用策略 | 精度较低、依赖数据分布假设 |
3 开放世界识别和开放词汇识别
| 维度 | 开放世界识别(Open-World Recognition) | 开放词汇识别(Open-Vocabulary Recognition) |
|---|---|---|
| 核心目标 | 识别已知类别的同时,检测并适应未知类别 | 通过自然语言描述识别训练时未见的类别 |
| 输入形式 | 纯视觉输入(图像/视频) | 视觉+文本多模态输入(如图像+类别描述文本),比如像CLIP对比语言预训练模型 |
| 输出能力 | 区分"已知类"与"未知类",逐步增量学习新类别 | 直接预测开放词汇表中的类别(无需显式增量学习) |
| 理论基础 | 增量学习、异常检测 | 多模态对齐(如视觉-语言预训练) |
参考过的链接:https://blog.csdn.net/festaw/article/details/139475358
[1] DCCUS:论文Domain-General Crowd Counting in Unseen Scenarios(DCCUS)详解以及对应代码详解
[2] MPCount:https://arxiv.org/pdf/2403.09124v2.pdf



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









