







机器学习中的泛化与适应:深入理解域泛化、域适应、少样本学习、零样本学习、开放世界识别与开放词汇识别
😎 作者介绍:我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun,视频号:AI-行者Sun
🎈
本文专栏:本文收录于《深度学习》系列专栏,相信一份耕耘一份收获,我会详细的分享深度学习各种知识细节,图文并茂,不说废话,祝大家早日中稿cvpr
🤓 欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。 🖥
随时欢迎您跟我沟通,一起交流,一起成长、进步!
在机器学习的世界中,我们经常面临如何让模型在新环境中表现出色的挑战。这些新环境可能包括不同的数据分布、少量的样本、未知的类别,甚至是全新的词汇。这里我将用生动的例子来解释,看完绝对不迷糊,深入探讨域泛化、域适应、少样本学习、零样本学习、开放世界识别和开放词汇识别这六种不同的学习任务,并尝试通过具体例子和代码解释来阐明它们之间的区别。
域泛化(Domain Generalization)
域泛化是机器学习中的一个挑战性任务,它旨在训练一个模型,使其能够在多个不同的数据分布上表现良好,而不仅仅是在训练时使用的数据分布上。域泛化的目标是创建一个泛化能力强的模型,能够适应新的、未知的环境。
域泛化的重要性
在现实世界的应用中,我们经常遇到数据分布的变化。例如,一个在某个特定地区训练的图像识别模型可能在另一个地区表现不佳,因为光照、背景、物体的呈现方式等可能有所不同。域泛化可以帮助模型克服这种分布差异,提高其在新环境中的鲁棒性。
举几个域泛化的应用例子
图像识别
假设我们有一个图像识别模型,它在白天拍摄的图片上训练得很好,能够准确识别不同的物体。然而,当这个模型被部署在夜间环境时,由于光照条件的变化,它的性能可能会下降。域泛化可以帮助这个模型学习到在不同光照条件下也能准确识别物体的特征。
医疗诊断
在医疗领域,不同医院收集的病人数据可能存在显著差异,这可能是由于设备的不同、病人群体的差异或数据收集方法的不同。域泛化可以帮助训练一个模型,使其能够适应这些不同的数据源,并在新的医院环境中提供准确的诊断。
代码示例
简化的域泛化问题的代码示例,使用Python和scikit-learn库。我们将模拟两个不同的数据源(源域和目标域),并尝试训练一个模型来泛化到目标域。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 生成模拟数据(源域和目标域)
X_source, y_source = make_classification(n_samples=1000, n_features=20, random_state=42)
X_target, y_target = make_classification(n_samples=1000, n_features=20, random_state=43) # 目标域略有不同
# 划分源域数据为训练集和验证集
X_source_train, X_source_val, y_source_train, y_source_val = train_test_split(
X_source, y_source, test_size=0.3, random_state=42
)
# 训练模型
model = SVC(kernel='linear')
model.fit(X_source_train, y_source_train)
# 在源域验证集上评估模型
source_val_accuracy = accuracy_score(y_source_val, model.predict(X_source_val))
print(f"Source domain validation accuracy: {source_val_accuracy}")
# 在目标域测试集上评估模型
target_accuracy = accuracy_score(y_target, model.predict(X_target))
print(f"Target domain test accuracy: {target_accuracy}")
在这个例子中,我们首先生成了两个不同的数据集来模拟源域和目标域。然后,我们在源域上训练了一个支持向量机(SVM)分类器,并在源域的验证集和目标域的测试集上评估了模型的性能。
域适应(Domain Adaptation)
域适应是机器学习中的一个关键领域,它涉及将一个在特定领域(源域)上训练好的模型调整或迁移到另一个不同的领域(目标域),以提高其在新领域中的表现。源域和目标域的数据分布可能存在显著差异,域适应的目标是减少这些差异,使模型能够适应新环境。
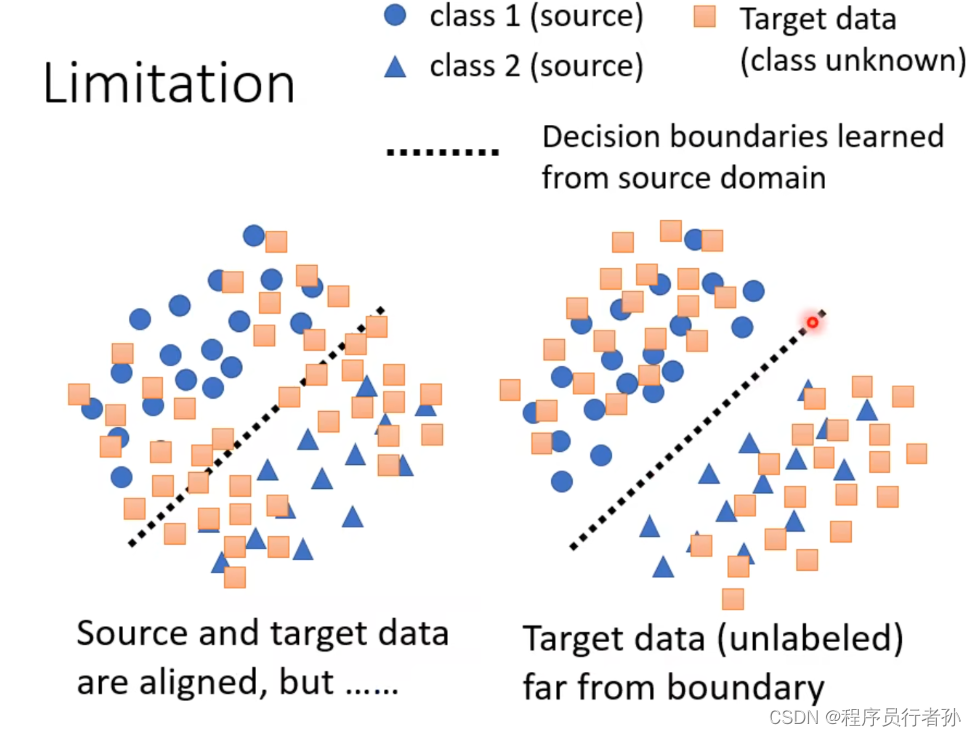
域适应的重要性
域适应在许多现实世界的应用中至关重要,尤其是在数据标注成本高昂或难以获取的情况下。例如,在医疗诊断、自然语言处理和计算机视觉等领域,获取大量标注数据可能非常困难,而域适应可以帮助我们利用已有的、在不同分布上收集的数据来训练模型。
域适应的例子
风格迁移
在艺术领域,我们可能希望将一种艺术风格迁移到另一幅画作上。源域可以是梵高的画作,而目标域可以是另一幅不同风格的画作。通过域适应,我们可以训练一个模型来捕捉源域的艺术风格,并将其应用到目标域上。

医疗影像分析
在医疗影像分析中,一个在特定医院的数据集上训练的模型可能无法很好地泛化到其他医院的数据,因为不同的医院可能使用不同的设备和成像协议。域适应可以帮助调整模型,使其能够适应不同医院的数据分布。
代码示例
使用Python和scikit-learn库,我们将模拟两个不同的数据源(源域和目标域),并尝试通过迁移学习来适应目标域。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 生成模拟数据(源域和目标域)
X_source, y_source = make_classification(n_samples=1000, n_features=20, random_state=42)
X_target, y_target = make_classification(n_samples=1000, n_features=20, random_state=43, weights=[0.1, 0.9]) # 目标域的分布略有不同
# 划分源域数据为训练集和测试集
X_source_train, X_source_test, y_source_train, y_source_test = train_test_split(
X_source, y_source, test_size=0.3, random_state=42
)
# 训练模型
model = SVC(kernel='linear')
model.fit(X_source_train, y_source_train)
# 在源域测试集上评估模型
source_test_accuracy = accuracy_score(y_source_test, model.predict(X_source_test))
print(f"Source domain test accuracy: {source_test_accuracy}")
# 微调模型以适应目标域
model.fit(X_target, y_target, sample_weight=np.where(y_target == 1, 1, 10)) # 假设类别1更重要
# 在目标域测试集上评估模型
target_accuracy = accuracy_score(y_target, model.predict(X_target))
print(f"Target domain test accuracy after adaptation: {target_accuracy}")
在这个例子中,我们首先生成了两个不同的数据集来模拟源域和目标域。然后,我们在源域上训练了一个支持向量机(SVM)分类器,并在源域的测试集上评估了模型的性能。接着,我们对模型进行了微调,以适应目标域的数据分布。
Few-shot Learning(少样本学习)
少样本学习是机器学习中的一个挑战性任务,它涉及到在只有少量样本的情况下训练模型,并期望模型能够对新样本进行有效的泛化。这与传统的监督学习不同,后者通常需要大量的标注数据来训练模型。少样本学习的目标是提高模型在面对数据稀缺时的学习效率和泛化能力。

少样本学习的重要性
少样本学习在许多实际应用中非常重要,尤其是在那些获取大量标注数据成本高昂或不切实际的场景中。例如,在某些医学图像分析任务中,某些罕见疾病的图像可能非常有限。在这种情况下,少样本学习可以帮助我们训练出能够识别这些罕见疾病的模型。
少样本学习的例子
新物种识别
在生物学研究中,新发现的物种可能只有少量的样本可供研究。少样本学习可以帮助研究人员快速训练一个模型来识别这些新物种。
罕见疾病诊断
在医学领域,罕见疾病的病例通常很少,获取大量标注图像非常困难。少样本学习可以帮助医生和研究人员训练出能够诊断这些罕见疾病的模型。

代码示例
模拟一个少样本学习的场景,其中我们只有少量的样本来训练模型。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 假设我们有一个小的数据集,每个类别只有少量样本
num_classes = 5
num_samples_per_class = 5 # 每个类别的样本数
# 生成模拟数据
inputs = np.random.rand(num_classes * num_samples_per_class, 20) # 假设输入特征维度为20
targets = np.repeat(np.arange(num_classes), num_samples_per_class) # 标签
# 划分训练集和验证集
train_inputs, val_inputs, train_targets, val_targets = keras.array_split(
[inputs, targets], 2
)
# 定义一个小的神经网络模型
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(20,)),
layers.Dense(64, activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_inputs, train_targets, epochs=10, validation_data=(val_inputs, val_targets))
# 评估模型
_, accuracy = model.evaluate(val_inputs, val_targets)
print(f"Validation accuracy: {accuracy}")
首先生成了一个模拟的小数据集,其中每个类别只有少量样本。然后,我们定义了一个简单的神经网络模型,并使用这个小数据集来训练模型。最后,我们在验证集上评估了模型的性能。
少样本学习可能涉及更复杂的技术,如元学习(meta-learning)、迁移学习、数据增强或生成模型,以提高模型在少量样本上的性能和泛化能力。
Zero-shot Learning(零样本学习)
零样本学习(Zero-shot Learning, ZSL)是机器学习中的一个有趣领域,它旨在让模型能够识别在训练阶段从未见过的类别。这通常是通过将类别的语义信息(如类别描述或属性)与模型训练相结合来实现的。零样本学习对于处理那些获取大量标注数据成本高昂或不可行的任务特别有用。
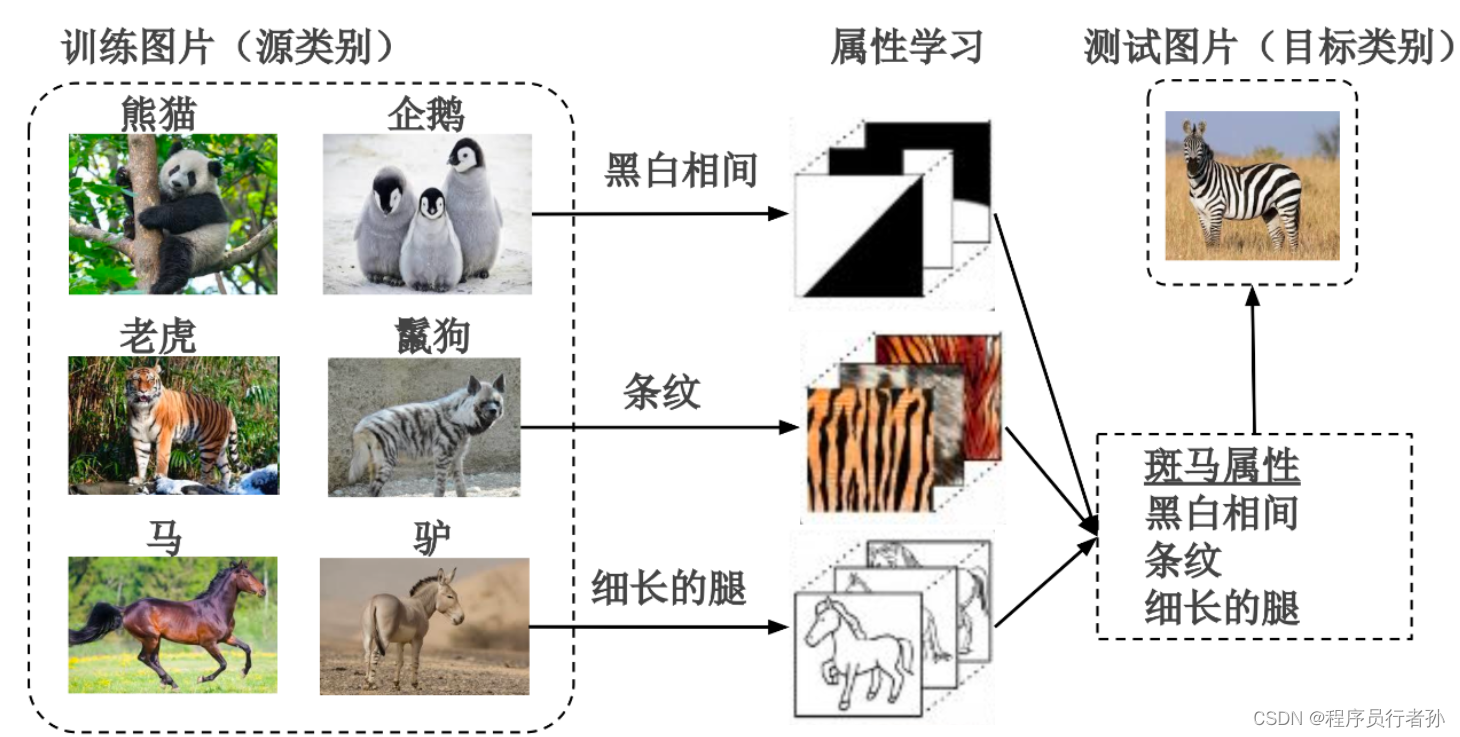
零样本学习的重要性
零样本学习的重要性在于它允许模型扩展其知识范围,以识别新的和未知的类别,而无需对每个新类别进行昂贵的重新训练。这在实际应用中非常有价值,例如在生物多样性研究、内容过滤和推荐系统等领域。
零样本学习的例子
动物识别
假设我们有一个动物图像数据集,其中包含了猫、狗和马的图像。在零样本学习的设置中,我们可能希望模型能够识别出“斑马”这一新的类别,即使在训练阶段没有看到过斑马的图像,但模型已经获得了关于斑马的语义信息。
艺术作品分类
在艺术领域,我们可能有一个包含多种艺术风格(如印象派、立体主义)的数据集。零样本学习可以帮助模型识别出新的或未知的艺术风格,即使这些风格在训练阶段并未出现。
代码示例
模拟一个零样本学习的场景,其中模型通过类别属性来识别未知类别。
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# 假设我们有一个已知类别的数据集和对应的属性
known_classes = ['cat', 'dog', 'horse']
known_attributes = {
'cat': [0, 1, 0],
'dog': [1, 0, 0],
'horse': [0, 0, 1]
}
known_attributes_matrix = np.array([known_attributes[cls] for cls in known_classes])
# 假设我们有未知类别的属性信息
unknown_class = 'zebra'
unknown_attributes = [1, 1, 1] # 假设斑马具有猫、狗和马的属性
# 构建一个简单的神经网络模型来学习属性
attribute_model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(len(known_attributes['cat']),)),
layers.Dense(64, activation='relu'),
layers.Dense(len(known_attributes['cat']), activation='softmax')
])
# 编译模型
attribute_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型来学习属性
# 将属性转换为one-hot编码
known_attributes_one_hot = np.eye(len(known_attributes['cat']))[known_attributes_matrix]
attribute_model.fit(np.array(known_attributes_matrix), known_attributes_one_hot, epochs=10)
# 使用模型预测未知类别的属性
unknown_attributes_prediction = attribute_model.predict(np.array([unknown_attributes]))
# 根据预测的属性确定未知类别
predicted_class_index = np.argmax(unknown_attributes_prediction)
predicted_class = known_classes[predicted_class_index]
print(f"Predicted class for {unknown_class}: {predicted_class}")
首先定义了已知类别和它们的属性,然后,我们构建了一个简单的神经网络模型来学习这些属性。接着,我们训练模型来识别已知类别的属性,并使用这个模型来预测未知类别(斑马)的属性。最后,我们根据模型的预测确定未知类别。
Open-world Recognition(开放世界识别)
开放世界识别是机器学习中的一个前沿领域,它涉及到构建能够识别和处理未知类别或新概念的模型。与封闭世界识别不同,后者假设所有可能的类别在训练阶段都已知,开放世界识别承认存在未知类别,并试图使模型能够适应这些未知情况。
开放世界识别的重要性
开放世界识别对于构建能够适应不断变化环境的智能系统至关重要。在现实世界中,新的对象、事件和概念不断出现,而开放世界识别可以使机器学习模型更加灵活和鲁棒,能够处理这些新情况。
开放世界学习的例子
自然语言处理
在自然语言处理中,新词汇、俚语或网络流行语可能迅速出现并流行。开放世界识别可以帮助语言模型理解和适应这些新词汇,即使它们在训练阶段并未出现。

生物多样性监测
在生态学和生物多样性监测中,新物种的发现是不断发生的。开放世界识别可以帮助构建模型,以识别和分类这些新物种,即使它们在模型训练时尚未被发现。
代码示例
开放世界识别通常需要使用更高级的技术,如神经网络和无监督学习。
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
# 假设我们有一些已知类别的训练数据
known_classes_x = np.random.rand(100, 20) # 100个样本,每个样本20维特征
known_classes_y = np.repeat([0, 1], 50) # 两个已知类别
# 模拟一些未知类别的数据
unknown_classes_x = np.random.rand(10, 20) # 10个未知类别的样本
# 构建一个简单的神经网络模型
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(20,)),
layers.Dense(64, activation='relu'),
layers.Dense(2, activation='softmax') # 两个已知类别
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(known_classes_x, known_classes_y, epochs=10)
# 在已知类别上评估模型
known_classes_accuracy = model.evaluate(known_classes_x, known_classes_y)
# 尝试在未知类别上进行预测
predictions = model.predict(unknown_classes_x)
# 可以设计一个策略来识别未知类别,例如通过置信度阈值
confidences = np.max(predictions, axis=1)
unknown_class_predictions = np.where(confidences < 0.5, -1, known_classes_y[np.argmax(predictions, axis=1)]) # -1 表示未知类别
print(f"Known classes accuracy: {known_classes_accuracy}")
print(f"Unknown class predictions: {unknown_class_predictions}")
首先创建了一个简单的神经网络模型,并用已知类别的数据训练它。然后,我们尝试用这个模型来预测未知类别的样本。这里,我们使用了简单的置信度阈值来尝试识别未知类别。
Open-vocabulary Recognition(开放词汇识别)概述
开放词汇识别(Open-vocabulary Recognition)是自然语言处理(NLP)中的一个概念,它指的是系统识别和理解其训练数据中未出现过的新词汇或术语的能力。这与封闭词汇识别相反,后者假设所有可能的词汇在训练阶段都已知。开放词汇识别对于构建能够理解和处理不断变化语言使用的智能系统至关重要。
开放词汇识别的重要性
开放词汇识别的重要性在于它允许系统适应新词汇、新概念和语言的演变,这对于保持系统的实用性和相关性至关重要。随着社交媒体、新闻和日常对话中新词汇的不断涌现,开放词汇识别可以帮助系统更好地理解和处理这些新词汇。
开放词汇识别的例子
社交媒体监测
在社交媒体监测中,新词汇和俚语经常出现。开放词汇识别可以帮助系统识别和理解这些新词汇,从而更准确地分析公众情绪和趋势。

医疗记录分析
在医疗记录分析中,医生可能会使用专业术语或缩写,这些可能不在标准词汇表中。开放词汇识别可以帮助系统识别和理解这些术语,从而提高分析的准确性。
代码示例
开放词汇识别通常涉及到使用先进的NLP技术和模型,如Word Embeddings(词嵌入)和Transformer模型。使用Python和spaCy库,展示如何使用词向量来处理未知词汇。
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from spacy import displacy
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
# 定义文本,其中包含已知和未知词汇
text = "The quick brown fox jumped over the lazy dog. #NewHashtag2024"
# 处理文本
doc = nlp(text)
# 可视化文本
displacy.render(doc, style="ent")
# 检查未知词汇
for token in doc:
if token.is_oov: # is_oov属性检查词汇是否在词汇表之外
print(f"未知词汇: {token.text}")
# 可选:使用词向量处理未知词汇
# 假设我们有一个词向量模型
word_vectors = nlc.word2vec.load("en_core_web_md.word2vec.bin")
for token in doc:
if token.text in word_vectors:
print(f"已知词汇及其向量: {token.text} -> {word_vectors[token.text]}")
else:
# 处理未知词汇,例如通过上下文推断其含义
print(f"未知词汇: {token.text}")
在这个例子中,我们首先加载了一个英文模型,并处理了包含已知和未知词汇的文本。然后,我们检查了文本中的每个词汇,以确定它是否在词汇表之外。对于未知词汇,我们可以使用词向量模型来尝试理解其含义或通过上下文进行推断。
但是,spaCy库本身并不提供is_oov属性或开放词汇识别功能。这里只是为了示例目的而假设。一般来说哈,开放词汇识别可能涉及更复杂的技术,如使用预训练的词向量模型(如Word2Vec或GloVe)来表示未知词汇,或者使用上下文信息来推断未知词汇的含义。
祝大家实验顺利,有效涨点~
以上是机器学习中的泛化与适应(深入理解域泛化、域适应、少样本学习、零样本学习、开放世界识别与开放词汇识别)的简单介绍,欢迎评论区留言讨论,如果有用欢迎点赞收藏文章,博主才有动力持续记录分享!!!
免费资料获取
关注博主公众号,获取更多粉丝福利。



















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











