






LibSVM(Library for Support Vector Machines)是一个支持向量机的开源库,适用于多种机器学习任务,尤其是在处理复杂数据集和高维数据时表现出色。
下载安装过LibSVM的小伙伴都知道该开源库有Python、Java、Matlab三个版本的开源代码,如果还没下载可以看我的这篇博客哦,https://blog.csdn.net/Kelly_Ai_Bai/article/details/134649314很详细的。比如对于Matlab来说,需要先进行编译,得到mex文件后可以直接在Matlab中进行使用,在进行使用之前我们需要先弄清楚输入到LibSVM中的数据是什么格式的,所以认真学习与LibSVM相关的Read me 文件是一件很重要的事情,磨刀不误砍柴工,这样可以避免很多不必要的错误。
下面我将会介绍一下Libsvm开源库自带的Readme文件中的内容,此篇文章是我自己的认知与理解,如有错误的地方请留言评论给我,我们一起探讨!
目录
- 快速入门
- 安装和数据格式
- “svm train”用法
- “svm predict”用法
- “svm scale”用法
- 实用提示
- 示例
- 预先计算的内核
- 库使用情况
- Java版本
- 构建Windows二进制文件
- 附加工具:子采样、参数选择、格式检查等。
- MATLAB/OCTAVE接口
- Python接口
一、快速入门

如果你是第一次接触SVM并且数据并不是很大,可以使用 tools 文件夹下的 easy.py 文件,它可以实现从数据缩放到参数选择的一切自动化工作。
用法:easy.py training_file [testing_file]
关于参数选择的更多信息可以阅读 tools/README
二、安装和数据格式
1. 安装说明
在Unix系统上,输入 make 命令来构建 svm-train、svm-predict 和 svm-scale 程序
在其他系统上,可以查看 Makefile 文件来构建这些程序,或者使用预构建的二进制文件(Windows系统的二进制文件位于 windows 目录中)
2. 数据格式
训练和测试数据文件的格式为:

每一行包含一个实例,以 \n 字符结束。虽然样本可能没有特征值(即所有零值的一行),但 <label> 列不能为空。对于训练集中的 <label>,有以下几种情况:
-
分类问题:
<label>是表示类别标签的整数(支持多类别) -
回归问题:
<label>是目标值,可以是任意实数 -
单类别SVM:
<label>无效,可以是任何数字
在测试集中,<label> 仅用于计算准确性或错误。如果不知道它,可以使用任何数字。对于单类别SVM,如果知道非异常值/异常值,测试文件中它们的标签必须为+1/-1以进行评估。
-
<label>列使用C标准库提供的strtod()函数进行读取。因此,数值等效的<label>值将被视为相同(例如,+01e0和1被视为相同的类)。 -
<index>:<value>表示特征(属性)值:<index>从1开始是整数,<value>是实数。唯一的例外是预计算的核,其中<index>从0开始;请参阅预计算核的部分, 索引必须按升序排列。
3.其它说明
-
提供了一些实用程序,如
svm-scale用于缩放输入数据文件,svm-toy是一个简单的图形界面,显示SVM如何在平面上分离数据。 -
svm-toy提供了简单的图形界面,显示SVM如何在平面上分离数据。可以通过点击窗口绘制数据点,选择类别,加载和保存数据文件,并获得SVM模型。 -
注意,
svm-toy的 “load” 和 “save” 考虑到密集数据格式,对于分类和回归情况都是如此。对于分类,每个数据点都有一个标签(颜色),必须是1、2或3,以及两个属性(x轴和y轴的值)。对于回归,每个数据点都有一个目标值(y轴)和一个属性(x轴的值)。 -
构建
svm-toy时需要Qt库(从 http://www.trolltech.com 获取)或GTK+库(从 http://www.gtk.org 获取)。 -
预构建的Windows二进制文件在
windows目录中, 在64位机器上使用Visual C++
三、svm-train的使用说明
用法: svm-train [options] training_set_file [model_file]
四、支持向量机预测工具svm_predict的使用
用法: svm-predict [options] test_file model_file output_file
-
options: 可选参数,用于配置svm-train的各种设置。 -
training_set_file: 训练集文件的路径,包含用于训练模型的样本数据。 -
[model_file]: (可选)模型文件的路径,用于保存训练后的模型。 -
options可选参数的选项:
-
-s svm_type: 设置SVM的类型,默认为0。- 0: C-SVC(多类分类)
- 1: nu-SVC(多类分类)
- 2: 单类别SVM
- 3: epsilon-SVR(回归)
- 4: nu-SVR(回归)
-
-t kernel_type: 设置核函数的类型,默认为2。- 0: 线性核函数:u’*v
- 1: 多项式核函数:(gamma*u’*v + coef0)^degree
- 2: 径向基函数(RBF)核函数:exp(-gamma*|u-v|^2)
- 3: 双曲正切核函数:tanh(gamma*u’*v + coef0)
- 4: 预先计算的核(核值在训练集文件中)
-
-d degree: 在核函数中设置多项式的次数,默认为3。 -
-g gamma: 在核函数中设置 gamma 值,默认为1/特征数。 -
-r coef0: 在核函数中设置 coef0 值,默认为0。 -
-c cost: 设置 C-SVC、epsilon-SVR 和 nu-SVR 的参数 C,默认为1。 -
-n nu: 设置 nu-SVC、单类别SVM 和 nu-SVR 的参数 nu,默认为0.5。 -
-p epsilon: 设置 epsilon-SVR 损失函数中的 epsilon,默认为0.1。 -
-m cachesize: 设置缓存内存大小(以MB为单位),默认为100。 -
-e epsilon: 设置终止准则的容差,默认为0.001。 -
-h shrinking: 是否使用收缩启发式算法,0或1,默认为1。 -
-b probability_estimates: 是否训练概率估计模型,或10,默认为0。 -
-wi weight: 设置C-SVC中类别i的参数C为 weight*C,默认为1。 -
-v n: n折交叉验证模式。将数据随机分成n部分,计算交叉验证准确性/均方误差 -
-q: 静默模式,无输出。
svm-predict 用于使用训练好的模型对测试数据进行预测,并将结果输出到指定文件。
五、支持向量机数据缩放工具svm_scale的使用
用法: svm-scale [options] data_filename
svm-scale 用于缩放输入数据文件,以确保数据在训练和测试之间具有一致的尺度。详细的例子可以参考第七中的 ‘示例’ 部分。
-
options: 可选参数,用于配置svm-predict的各种设置。 -
-b probability_estimates: 是否预测概率估计值,0或1(默认为0)。 -
model_file: 由svm-train生成的模型文件。 -
test_file: 要进行预测的测试数据文件。 -
output_file:svm-predict生成的输出文件。 -
options: 可选参数,用于配置svm-scale的各种设置。 -
-l lower: x 缩放下限,默认为 -1。 -
-u upper: x 缩放上限,默认为 +1。 -
-y y_lower y_upper: y 缩放限制,默认为不进行 y 缩放。 -
-s save_filename: 将缩放参数保存到指定文件中。 -
-r restore_filename: 从指定文件中恢复缩放参数。
六、实用提示
主要是关于使用支持向量机(SVM)时的一些建议,这些建议旨在帮助用户更有效地使用支持向量机,并在处理不同类型的数据和问题时做出适当的选择和调整。
1. 对数据进行缩放: 例如,将每个属性缩放到 [0,1] 或 [-1,+1] 范围内,以确保数据具有一致的尺度。
2. 对于C-SVC,考虑使用工具目录中的模型选择工具: 对于C-SVC(多类分类),建议考虑使用工具目录中提供的模型选择工具,以帮助选择最合适的模型。
3. nu-SVC/one-class-SVM/nu-SVR中的nu近似于训练错误和支持向量的分数: 在使用 nu-SVC、one-class-SVM 或 nu-SVR 时,nu 参数近似表示训练错误和支持向量的比例。
4. 如果分类数据不平衡(例如正例很多而负例很少),尝试不同的惩罚参数C: 通过使用 -wi 参数,尝试不同的惩罚参数C,特别是在处理正例和负例不平衡的情况下。
5. 为庞大的问题指定更大的缓存大小(即更大的-m): 对于庞大的问题,建议设置更大的缓存大小,通过增大 -m 参数的值来提高性能。
七、示例
以下是对每个例子的中文解释:
1. **数据缩放:**
- `svm-scale -l -1 -u 1 -s range train > train.scale`
- `svm-scale -r range test > test.scale`
- 将训练数据的每个特征缩放到 [-1,1] 范围内。缩放因子存储在文件 `range` 中,并用于缩放测试数据。
2. **使用RBF核进行分类:**
- `svm-train -s 0 -c 5 -t 2 -g 0.5 -e 0.1 data_file`
- 使用RBF核函数 exp(-0.5|u-v|^2),设置C为5,停止容差为0.1进行分类器训练。
3. **使用线性核进行回归:**
- `svm-train -s 3 -p 0.1 -t 0 data_file`
- 使用线性核函数 u'v 进行回归,损失函数中的 epsilon 设置为0.1。
4. **设置不同类别的惩罚参数:**
- `svm-train -c 10 -w1 1 -w-2 5 -w4 2 data_file`
- 设置类别1的惩罚参数为10(1 * 10),类别-2的惩罚参数为50(5 * 10),类别4的惩罚参数为 20(2 * 10)。
5. **五折交叉验证:**
- `svm-train -s 0 -c 100 -g 0.1 -v 5 data_file`
- 使用参数C=100和gamma=0.1进行五折交叉验证。
6. **获得概率信息的模型并进行预测:**
- `svm-train -s 0 -b 1 data_file`
- `svm-predict -b 1 test_file data_file.model output_file`
- 获取包含概率信息的模型,并使用概率估计对测试数据进行预测。
八、预先计算的内核
用户可以预先计算核函数值并将其作为训练和测试文件的输入,这样libsvm就不需要原始的训练/测试集。
假设有L个训练实例x1,…, xL , 令K(x, y)表示两个实例x和y的核函数值。输入格式如下:
对于xi的新训练实例:
<label> 0:i 1:K(xi,x1) ... L:K(xi,xL)
对于任何x的新测试实例:
<label> 0:? 1:K(x,x1) ... L:K(x,xL)
换句话说,在训练文件中,第一列必须是xi的“ID”; 在测试中,? 可以是任何值。
所有核函数值,包括零值,都必须明确提供。训练/测试文件的任何排列或随机子集也是有效的(见下面的示例)。
示例:
假设原始训练数据有三个四维实例,测试数据有一个实例:
三个四维的训练数据实例:
15 1:1 2:1 3:1 4:1
45 2:3 4:3
25 3:1一个测试数据实例:
![]()
如果使用线性核函数,我们有以下新的训练/测试集:
训练实例:
15 0:1 1:4 2:6 3:1
45 0:2 1:6 2:18 3:0
25 0:3 1:1 2:0 3:1测试实例:
15 0:? 1:2 2:0 3:1其中 ? 可以是任何值
上述训练文件的任何子集也是有效的。例如:
25 0:3 1:1 2:0 3:1
45 0:2 1:6 2:18 3:0意味着核矩阵为

九.库使用情况
关于使用libsvm库进行支持向量机(SVM)模型训练和预测的说明。主要包括了以下内容:
- 如何包含头文件
svm.h并链接svm.cpp,以及如何使用svm-train.c和svm-predict.c示例文件。 - 构建SVM模型的方法,包括
svm_train函数的使用,以及svm_problem和svm_parameter结构的说明。 - 使用训练好的SVM模型进行数据分类或回归的方法,包括
svm_predict函数的使用。 - 交叉验证的方法,包括
svm_cross_validation函数的使用。 - 获取模型信息的方法,包括
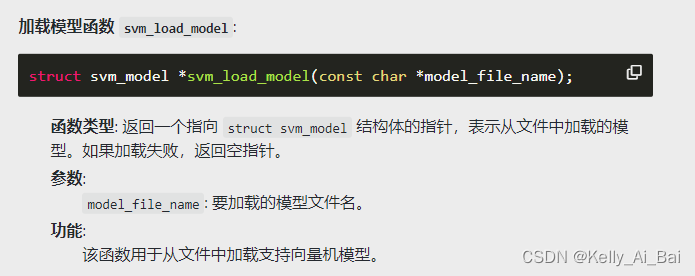
svm_get_svm_type、svm_get_nr_class等函数的使用。 - 保存和加载模型的方法,包括
svm_save_model和svm_load_model函数的使用。 - 释放内存的方法,包括
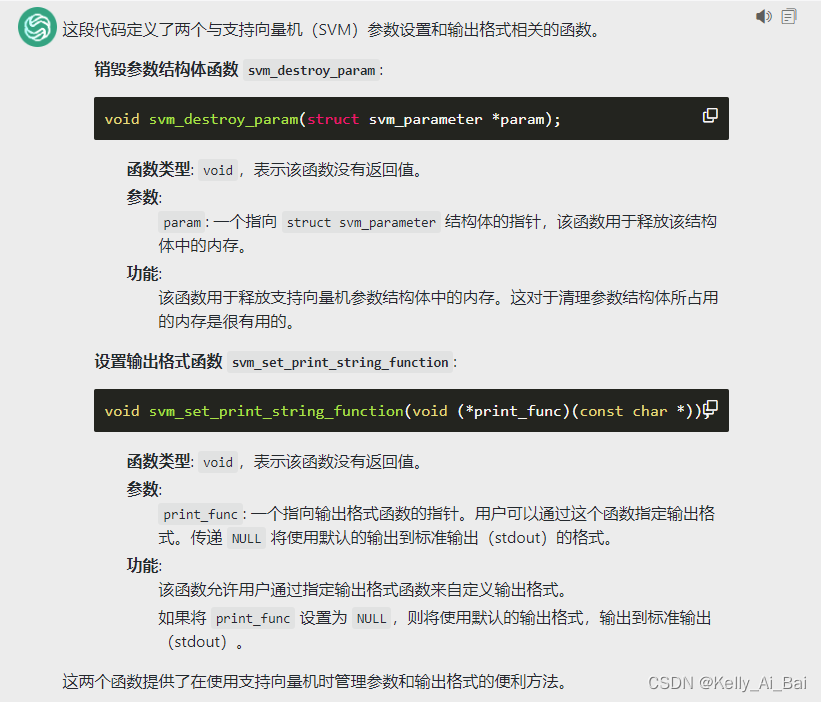
svm_free_model_content和svm_free_and_destroy_model函数的使用。
这些函数和结构提供了对SVM模型的训练、预测和评估的完整支持,以及模型的保存和加载功能。
下面我再来具体说一说这部分内容:
svm.h是头文件,里面包含了libsvm库中的函数以及结构体、变量等的定义,需要在c/c++源文件中写入 #include "svm.h" ,然后将项目和 svm.cpp 文件链接起来。你可以查看例子中是如何使用 'svm-train.c' 和 'sv-predict.c' 文件的。
在对测试数据进行分类处理之前,你需要使用训练数据对SVM模型( `svm_model' )进行训练,并且可以保存该模型以供后面使用。
1. svm_train函数
主要用于定义 SVM 的问题( struct svm_problem describes the problem)、参数(struct svm_parameter describes the parameters of an SVM model)和 模型(struct svm_model),以及进行 SVM 模型的训练。在 svm_model 中包含了训练过程中得到的模型信息,包括支持向量、决策函数的系数等。
- SVM的问题

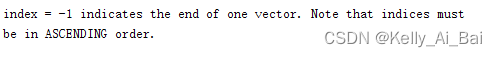
- 参数


- SVM模型
struct svm_model 存储了训练过程中得到的支持向量机模型, 不建议直接访问此结构中的条目,应该使用提供的接口函数来获取模型中的数值或信息。
-
模型存储位置:
struct svm_model结构存储了训练得到的支持向量机模型的所有相关信息,包括参数、支持向量、系数等。 -
不推荐直接访问:建议不要直接通过直接访问结构体的方式来获取或修改其中的数据。这是因为直接访问可能会破坏模型的完整性或导致不正确的操作。
-
使用接口函数:代替直接访问,应该使用提供的接口函数来获取模型中的数值或信息。这些接口函数设计用于安全地访问模型的不同部分,并且能够提供正确的数据以便于应用程序的使用。
因此,虽然 struct svm_model 存储了模型信息,但应该避免直接操作其中的数据,而是通过专门设计的接口函数来获取所需的信息,以确保正确性和稳定性。
关于svm_model的具体定义如下:


2. svm_predict函数

double svm_predict(const struct svm_model *model, const struct svm_node *x);
-
函数类型:
double,表明该函数返回一个双精度浮点数。 -
参数:
model: 一个指向struct svm_model结构体的指针,包含了用于预测的支持向量机模型。x: 一个指向struct svm_node结构体的指针,表示待测试的向量。
-
功能:
- 该函数在给定模型和测试向量的情况下执行分类或回归预测。
- 对于分类模型,返回测试向量
x的预测类别。 - 对于回归模型,返回使用模型计算的测试向量
x的函数值。 - 对于单类别模型(one-class model),返回+1或-1,表示测试向量
x是否属于该类别。
-
返回值:
- 对于分类模型,返回测试向量
x的预测类别。 - 对于回归模型,返回使用模型计算的测试向量
x的函数值。 - 对于单类别模型,返回+1或-1。
- 对于分类模型,返回测试向量
该函数允许用户根据训练好的支持向量机模型对新的数据进行分类或回归预测。具体的预测结果取决于模型的类型(分类、回归、单类别),并且使用模型中学到的参数进行计算。
3. svm_cross_validation函数

定义了一个名为 svm_cross_validation 的函数,用于进行交叉验证。数据被分成 nr_fold 个折叠(folds)。在给定参数 param 的情况下,依次使用从训练其余部分得到的模型验证每个折叠。在验证过程中,预测的标签(对所有 prob 实例的预测)被存储在名为 target 的数组中。
void svm_cross_validation(const struct svm_problem *prob, const struct svm_parameter *param, int nr_fold, double *target);
-
函数类型:
void,表示该函数没有返回值。 -
参数:
prob: 一个指向struct svm_problem结构体的指针,包含了训练数据和标签。param: 一个指向struct svm_parameter结构体的指针,包含了支持向量机模型的参数。nr_fold: 交叉验证的折叠数。target: 一个数组,用于存储在验证过程中的预测标签。
-
功能:
- 该函数执行交叉验证,将数据分成
nr_fold个折叠,并使用给定参数验证每个折叠。 - 在验证过程中,预测的标签(对所有
prob实例的预测)被存储在数组target中。
- 该函数执行交叉验证,将数据分成
-
说明:
prob的格式与svm_train()中的svm_problem结构体相同,包含了训练数据和标签。- 交叉验证通过将数据分成指定数量的折叠,每次使用其中一折作为验证集,其余折作为训练集,依次进行验证。
target数组用于存储在验证过程中得到的预测标签。
该函数是为了评估支持向量机模型在不同数据子集上的性能而设计的,以帮助选择模型参数或评估模型的泛化性能。
4. 获取支持向量机模型的类型

定义了一个名为 svm_get_svm_type 的函数,用于获取模型的 svm_type,svm_type 的取值在 svm.h 中定义。
int svm_get_svm_type(const struct svm_model *model);
-
函数类型:
int,表示该函数返回一个整数值,用于表示模型的svm_type。 -
参数:
model: 一个指向struct svm_model结构体的指针,包含了支持向量机模型的信息。
-
功能:
- 该函数用于获取模型的
svm_type,即支持向量机模型的类型。 svm_type的可能取值在svm.h中定义。
- 该函数用于获取模型的
该函数允许用户获取支持向量机模型的类型,以便了解模型是用于分类、回归还是单类别问题。

定义了一个名为 svm_get_nr_class 的函数,用于获取模型的类别数量。对于分类模型,该函数返回类别的数量;而对于回归模型或单类别模型,返回值为2。
int svm_get_nr_class(const svm_model *model);
-
函数类型:
int,表示该函数返回一个整数值,用于表示模型的类别数量。 -
参数:
model: 一个指向struct svm_model结构体的指针,包含了支持向量机模型的信息。
-
功能:
- 该函数用于获取模型的类别数量。
- 对于分类模型,返回模型中的类别数量。
- 对于回归模型或单类别模型,返回值为2,表示这两种模型都只涉及两个类别。
该函数的返回值对于了解模型是多类别分类还是其他类型的支持向量机模型很有用。
以及svm_get_labels、svm_get_sv_indices、svm_get_nr_sv、svm_get_svr_probability、svm_predict_values、svm_predict_probability、svm_check_parameter、svm_check_probability_model等函数的使用。
5. 保存和加载模型


6. 释放模型所占的内存,防止内存泄漏

7. 释放参数结构体的内存以及设置输出格式

十、 Java版本
这部分提供了关于使用 libsvm 在 Java 中进行支持向量机操作的说明和 API 文档。
因为我对Java语言目前不太熟悉,也没有用到,所以就先不具体介绍了,后面有时间会补充完整。
十一、构建Windows二进制文件
提供了在 Windows 环境下使用 Visual C++ 重新构建 libsvm 的二进制文件的说明
因为我是在 matlab 中使用的编译器对libsvm进行的编译,这一部分就不介绍了。
十二、附加工具:子采样、参数选择、格式检查等
具体的内容请看tools文件夹下的README文件
十三、MATLAB/OCTAVE 接口
Please check the file README in the directory `matlab'.
十四、Python接口
See the README file in python directory.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









