







可能的原因:
1. 在数据集很大的时候,loss下降很明显。train loss是平均一个epoch内的所有loss,比如第一个epoch的loss是2.3,2.2,2.1...0.7,0.6 平均train loss是1.5, 而val的时候是用已经训练了一个epoch的model进行测试的,假设拟合的很好验证集的loss平均是0.7左右, 那么这个时候val的平均效果肯定就更好了
2. data augmentation也会导致这样的现象。因为data augmentation的本质就是把训练集变得丰富,制造数据的多样性和学习的困难来让network更robust(比如旋转,随机crop,scale),但是val和test的时候一般是不对数据进行data augmentation的。(有时候会center crop,如果train的时候有crop的话)
3. 也有可能是 drop out的影响,drop out可以理解为随机屏蔽掉一些feature(神经元),只用一部分 feature 来识别,这样留下来的这些feature就更强了。 等 test/val 的时候全部神经元一起上,表现就更好了,drop out一般用于fc层中
4. 其实在ImageNet等大数据集训练的前期到中期一直有这样的现象,一般都是最后验证精度才被训练精度反超。其原因就是对参与训练的数据加了很多data argumentation技巧,例如:rescale,随机crop等等,一般不对test/val数据进行数据增强,比如直接进行crop中心操作
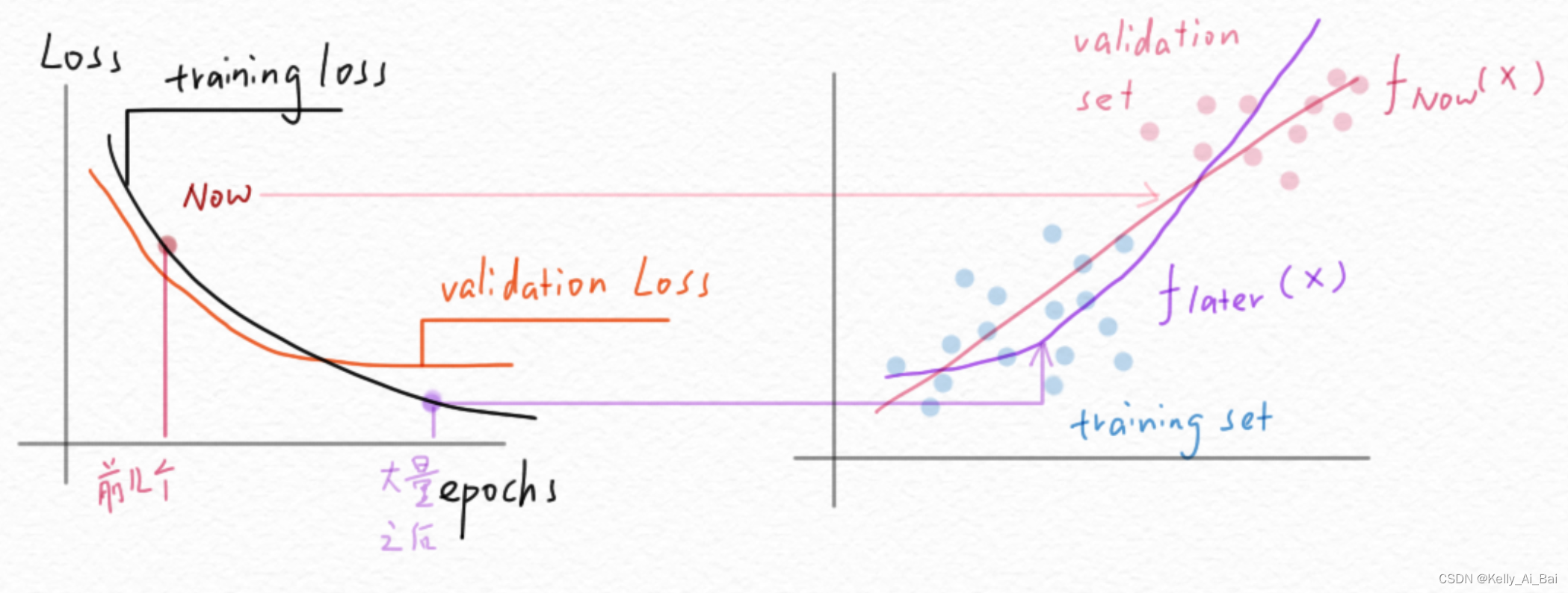
5. (1)数据集太小的话,如果数据集切分的不均匀,或者说训练集和测试集的分布不均匀。这时要重新切分数据集或者扩充数据集,使其分布一样
(2)在训练期间,Dropout将这些分类器的随机集合切掉,因此,训练准确率将受到影响。在测试期间,Dropout将自动关闭,并允许使用神经网络中的所有弱分类器,因此,测试精度提高
注意:测试集精度大于训练精度并不是一个普遍现象,需要仔细检查数据集的质量、模型的结构以及训练过程中的各种参数设置
参考链接:https://blog.csdn.net/IT_flying625/article/details/105013514















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









