







线性回归的基本要素
模型
为了简单起见,这里我们假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。接下来我们希望探索价格与这两个因素的具体关系。线性回归假设输出与各个输入之间是线性关系:
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b price=warea⋅area+wage⋅age+b
数据集
我们通常收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄。我们希望在这个数据上面寻找模型参数来使模型的预测价格与真实价格的误差最小。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一栋房屋被称为一个样本(sample),其真实售出价格叫作标签(label),用来预测标签的两个因素叫作特征(feature)。特征用来表征样本的特点。
损失函数
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。一个常用的选择是平方函数。 它在评估索引为 i i i 的样本误差的表达式为
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 , l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2, l(i)(w,b)=21(y^(i)−y(i))2,
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w ⊤ x ( i ) + b − y ( i ) ) 2 . L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(w⊤x(i)+b−y(i))2.
优化函数 - 随机梯度下降
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。本节使用的线性回归和平方误差刚好属于这个范畴。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。它的算法很简单:先选取一组模型参数的初始值,如随机选取;接下来对参数进行多次迭代,使每次迭代都可能降低损失函数的值。在每次迭代中,先随机均匀采样一个由固定数目训练数据样本所组成的小批量(mini-batch) B \mathcal{B} B,然后求小批量中数据样本的平均损失有关模型参数的导数(梯度),最后用此结果与预先设定的一个正数的乘积作为模型参数在本次迭代的减小量。
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) (\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b) (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b)
学习率:
η
\eta
η代表在每次优化中,能够学习的步长的大小
批量大小:
B
\mathcal{B}
B是小批量计算中的批量大小batch size
总结一下,优化函数的有以下两个步骤:
- (i)初始化模型参数,一般来说使用随机初始化;
- (ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数。
线性回归模型从零开始的实现
# import packages and modules
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
print(torch.__version__)
生成数据集
使用线性模型来生成数据集,生成一个1000个样本的数据集,下面是用来生成数据的线性关系:
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b price=warea⋅area+wage⋅age+b
# set input feature number
num_inputs = 2
# set example number
num_examples = 1000
#
# 语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为$T$的词的序列$w_1, w_2, \ldots, w_T$,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
$$
P(w_1, w_2, \ldots, w_T).
$$
本节我们介绍基于统计的语言模型,主要是$n$元语法($n$-gram)。在后续内容中,我们将会介绍基于神经网络的语言模型。(概率大,则合理,概率小,序列比较不合理)
## 语言模型
假设序列$w_1, w_2, \ldots, w_T$中的每个词是依次生成的,我们有
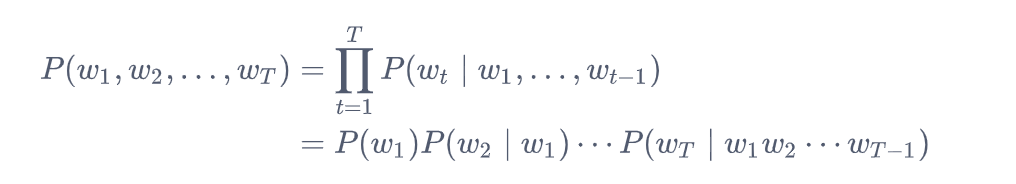
例如,一段含有4个词的文本序列的概率
$$
P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3).
$$
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,$w_1$的概率可以计算为:

其中$n(w_1)$为语料库中以$w_1$作为第一个词的文本的数量,$n$为语料库中文本的总数量。
类似的,给定$w_1$情况下,$w_2$的条件概率可以计算为:

其中$n(w_1, w_2)$为语料库中以$w_1$作为第一个词,$w_2$作为第二个词的文本的数量。
## n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。$n$元语法通过**马尔可夫假设简化模**型,马尔科夫假设是指一个词的出现只与前面$n$个词相关,即**$n$阶马尔可夫链**(Markov chain of order $n$),如果$n=1$,那么有$P(w_3 \mid w_1, w_2) = P(w_3 \mid w_2)$。基于$n-1$阶马尔可夫链,我们可以将语言模型改写为
$$
P(w_1, w_2, \ldots, w_T) = \prod_{t=1}^T P(w_t \mid w_{t-(n-1)}, \ldots, w_{t-1}) .
$$
以上也叫$n$元语法($n$-grams),它是基于$n - 1$阶马尔可夫链的概率语言模型。例如,当$n=2$时,含有4个词的文本序列的概率就可以改写为:

当$n$分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。
当$n$较小时,$n$元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当$n$较大时,$n$元语法需要计算并存储大量的词频和多词相邻频率。(存储开销会非常大)
思考:$n$元语法可能有哪些缺陷?
1. 参数空间过大 V+V^2+V^3
2. 数据稀疏 齐夫定律(很多次词频都很小 数据稀疏问题很严重)
# 语言模型数据集
## 读取数据集
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
print(len(corpus_chars))
print(corpus_chars[: 40])
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[: 10000]
建立字符索引
idx_to_char = list(set(corpus_chars)) # 去重,得到索引到字符的映射
char_to_idx = {char: i for i, char in enumerate(idx_to_char)} # 字符到索引的映射
vocab_size = len(char_to_idx)
print(vocab_size)
corpus_indices = [char_















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









