






论文标题
Information Recovery-Driven Deep Incomplete Multiview Clustering Network
论文来源
IEEE Transactions on Neural Networks and Learning Systems
论文链接
https://ieeexplore.ieee.org/document/10167670
代码链接
https://github.com/justsmart/Recformer-mindspore
昇思MindSpore作为一个开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能,超大规模AI预训练、极简开发、安全可信的体验,自2020年3月28日开源来已超过5百万的下载量,昇思MindSpore已支持数百+AI顶会论文,走入Top100+高校教学,通过HMS在5000+App上商用,拥有数量众多的开发者,在AI计算中心,金融、智能制造、金融、云、无线、数通、能源、消费者1+8+N、智能汽车等端边云车全场景逐步广泛应用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、套件、模型众智、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
在科技界、学术界和工业界对昇思MindSpore的广泛支持下,基于昇思MindSpore的AI论文2023年在所有AI框架中占比7%,连续两年进入全球第二,感谢CAAI和各位高校老师支持,我们一起继续努力做好AI科研创新。昇思MindSpore社区支持顶级会议论文研究,持续构建原创AI成果。昇思MindSpore将会不定期挑选一些优秀的论文来推送和解读,希望更多的产学研专家跟昇思MindSpore合作,一起推动原创AI研究,MindSpore社区会持续支撑好AI创新和AI应用,本文是昇思MindSpore AI顶会论文系列第14篇,选择了来自哈尔滨工业大学的一篇论文解读,感谢各位专家教授同学的投稿。本文已上传到知乎,点击阅读原文即可查看。
01 研究背景
众所周知,多视图数据从不同角度刻画观测对象。相比于传统单视图数据,这种异源数据保留了多层次、多维度的语义信息。最近几年,多视图聚类作为一种新颖的表示学习方法,已经引起了广泛的研究热情,并被大量地应用于数据分析等相关领域。传统的多视图聚类方法通常假设能够获得完整的多视图数据,然而这一假设在实践中很难满足。因此,研究者提出许多不完备多视图聚类方法以适应越来越常见的不完备多视图数据,我们这篇文章也是基于此问题展开。所谓不完备多视图数据是指样本的所有视图并非全部可用,存在随机的视图缺失,例如由语音、文本、图像组成的多视图数据中,存在部分或全部样本的任意部分模态不可用的现象。
针对不完备/缺失视图,一种常见的思路是在多视图对齐的前提下规避缺失信息的负面风险,例如在深度网络中引入先验缺失信息以帮助模型在训练过程中“无视”缺失的数据;另一种方法则试图根据不同视图间信息的关联性恢复缺失的数据,这一方法更加直观也更有挑战性。
我们基于昇思MindSpore框架提出一种信息恢复驱动的深度不完备多视图聚类网络以解决上述问题,该模型在实现缺失视图复原的同时取得了良好的多视图聚类结果。
02 团队介绍
刘成亮博士生,哈尔滨工业大学(深圳),论文一作。
文杰助理教授,哈尔滨工业大学(深圳),论文通讯作者,IEEE/CCF 高级会员,谷歌引用3100多次,获得中国博新计划,发表CCF A/B类论文60多篇,一篇论文荣获CCF A类会议AAAI优秀论文奖。
吴志昊博士生,哈尔滨工业大学(深圳)
罗笑玲博士生,哈尔滨工业大学(深圳)
黄超助理教授,中山大学(深圳校区)
徐勇教授,哈尔滨工业大学(深圳)
03 论文简介
3.1方法动机
我们不能凭空恢复缺失的信息,但我们可以基于现有的数据尽可能地猜测缺失的数据。首先从多视图数据的关键属性来考虑这个问题。我们知道,不同的视图在聚类任务中具有相同的高层语义信息,即它们是对同一个抽象目标的不同描述。如果我们能够捕获共享的高级语义信息,那么就有可能根据学习模式向后推断缺失的信息。从另一个角度来看,缺失数据推理可以看作是一个生成任务,通常通过自编码器网络来实现。受到上述分析的启发,我们设计了一个跨视图自编码器作为我们的主要框架,其编码器学习高级语义表示,解码器尝试从融合表示中恢复缺失的视图。
此外,大量研究证明数据的内在结构对于无监督学习至关重要。经典的最近邻图约束广泛应用于各种传统机器学习方法中,它使得提取的语义表示能够保持数据的原始拓扑结构,这不仅在很大程度上方便了聚类结构的学习,而且可以驱动模型向更合理的方向“猜测”缺失的数据。然而,需要注意的是,除非我们能提供近似完整的数据,否则我们很难直接从不完整的数据中得到一个完整的近邻图。至此,重新整合上述两点动机,我们可以得到如下的缺失数据的恢复思路:在统一的自编码器框架中融合近似图构建和缺失视图恢复两项任务。
获得恢复的视图需要在下游任务中进行评估,因此我们将模型的训练分为2个阶段:
阶段1:缺失视图恢复
阶段2:基于恢复数据学习多视图聚类表示
阶段1中主要尝试利用自编码器结构和样本间近邻约束恢复缺失数据,阶段2主要基于恢复的数据执行聚类微调。图1所示为我们的方法的总体框架。
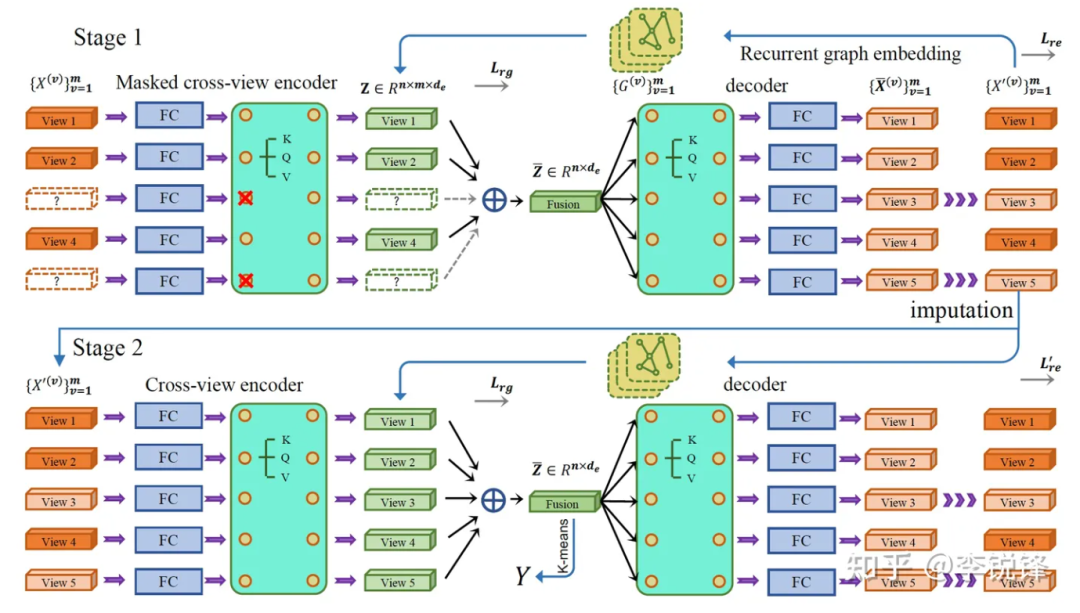
图1 主要结构图
3.2 跨视图编码器
多视图特征来源各异,每个视图的原始特征维度均不相同,为了便于深度网络的张量运算,同时将多个视图映射到同维度的特征空间,我们为每个视图分配对应的多层感知机以初步提取原始特征的深度特征。然而仅仅提取每个视图特定的深度特征是不够的,因为视图间的互补性信息难以得到充分挖掘。因此,我们借鉴处理序列数据中常用的Transformer模块,将多个视图的深度特征组合为一个无序的序列数据,并将其输入到Transformer中,利用自注意力机制完成跨视图的信息交互。
需要注意的是,我们在阶段1中的Transformer编码器的输入是面向不完备数据的,因此我们引入掩膜机制在计算注意力分数的过程中屏蔽缺失视图的影响,使得视图间的注意力分数仅关注可用视图。接着,我们将Transformer编码器的输出通过多视图加权融合策略融合为一个特征,这样即获得了样本的多个视图的融合表示。至此,编码过程结束,相应地,我们设计了一套对称的解码器用于将融合表示恢复到原始特征空间。在解码过程中,不再屏蔽缺失位置的特征使得解码器根据融合特征到原始特征的映射初步地恢复出缺失数据。
3.3 循环图约束
在多视图聚类领域,许多工作习惯于在传统的多视图学习方法中加入图约束,通过构造一个先验邻接矩阵来保持数据的原始内在结构。该方法基于如下基本的流形假设:如果两个样本在原始特征空间中彼此接近,那么它们在嵌入空间中也是接近的。但是在数据不完整的情况下,很多现有方法直接跳过缺失的视图构建近邻图,这往往会不可避免地带来偏差,特别是在缺失率较大的数据集上。因此,我们期望获得一个近似完整的邻接图来指导编码器提取高级语义特征。另一方面,更多的判别性语义特征也可以促进缺失视图的恢复,从而有助于构建更完备的近邻图。
基于以上准则,我们创新地提出了循环图约束:即通过自编码器生成恢复的数据,再基于恢复数据生成的近邻图反过来约束自编码器的编解码过程。这样反复迭代,生成恢复数据与近邻图约束两者相辅相成,相互促进。
04 实验
4.1 不完备多视图数据集设置
为了评估我们的模型的性能,我们选择五种常用的多视图数据集进行实验:
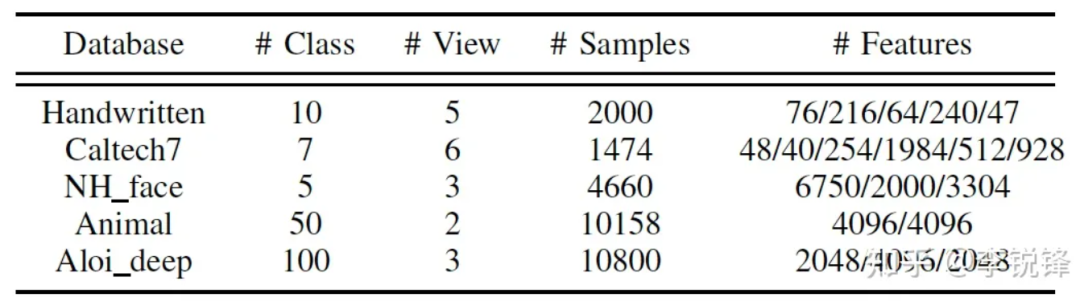
表1 五个常用的多视图聚类数据集
不完备数据集的预处理:我们在完备数据集的基础上生成不完整数据集来模拟丢失视图的情况。我们随机移除每个视图的[10%,30%,50%,70%]实例,并保证每个样本至少一个视图可用。对于只有两个视图的Animal数据集,我们随机选择所有样本中的[10%,30%,50%]作为具有两个视图的配对样本。剩余的一半样本的第一个视图被删除,另一半样本的第二个视图被删除。在实验中,所有被删除的数据都用“0”初步填充。
4.2 不同缺失率下的实验结果
在不同的缺失率下的实验结果:
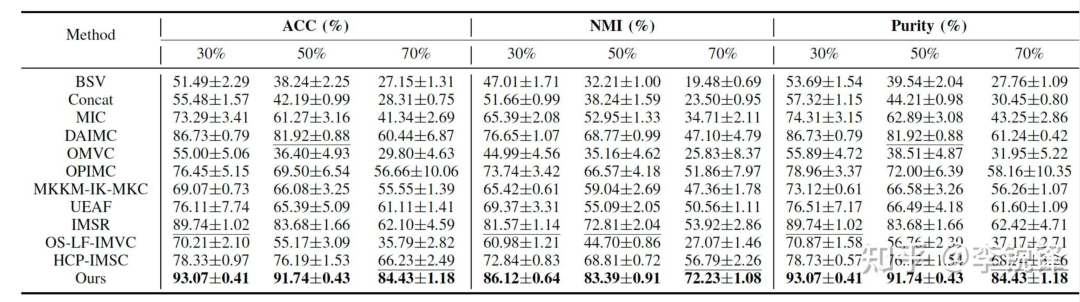
表2 在Handwritten上的实验结果
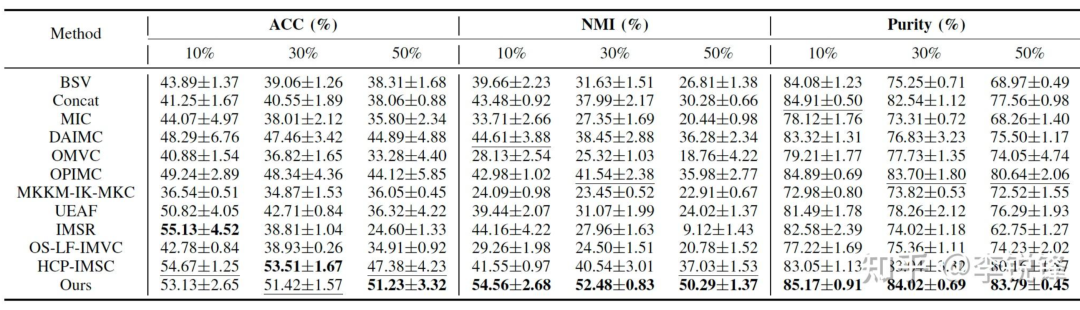
表3 在Caltech7上的实验结果
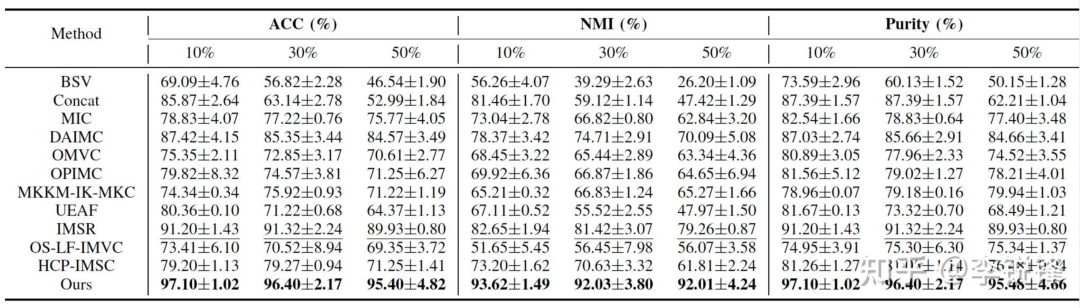
表4 在NH_face上的实验结果
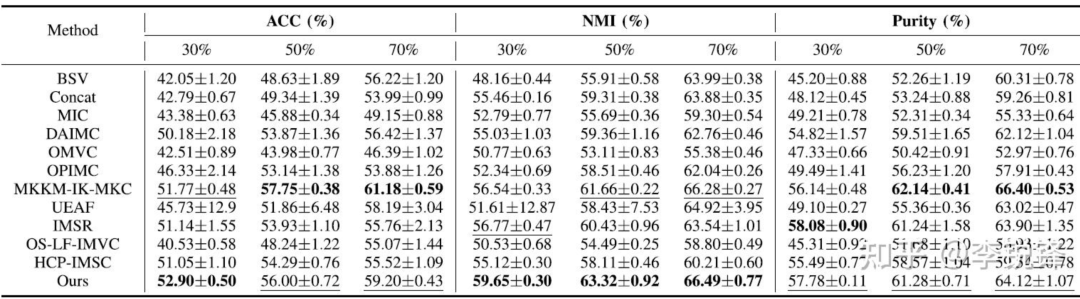
表5 在Animal上的实验结果
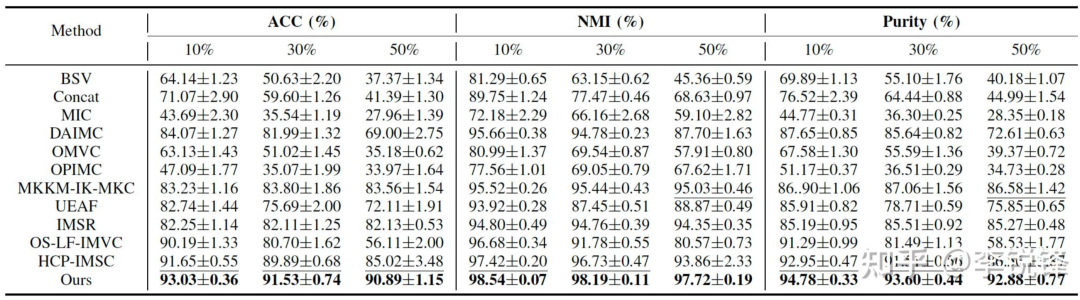
表6 在Aloi_deep上的实验结果
从表2至表6可以看到,我们的方法在不同缺失率下均取得了较好的聚类性能,同时,可以明显地观察到,当缺失率增大时,不完备多视图聚类的性能明显下降。
4.3 可视化结果
此外,由于Handwritten和NH_face恰好存在一个视图是样本的灰度值,因此我们可以将其缺失数据和恢复数据可视化,如图2所示:

图2 缺失数据恢复:在Handwritten和NH_face数据集上的恢复结果
该图第一行为缺失的数据(未参与模型优化),第二行为恢复的数据。经过对比可以看到,我们的恢复数据与原始数据非常接近,即模型具有强大的视图恢复能力。
我们将聚类指示特征使用t-NSE可视化后,可以看到我们的方法拥有更好的聚类效果(RecFormer是我们的方法):
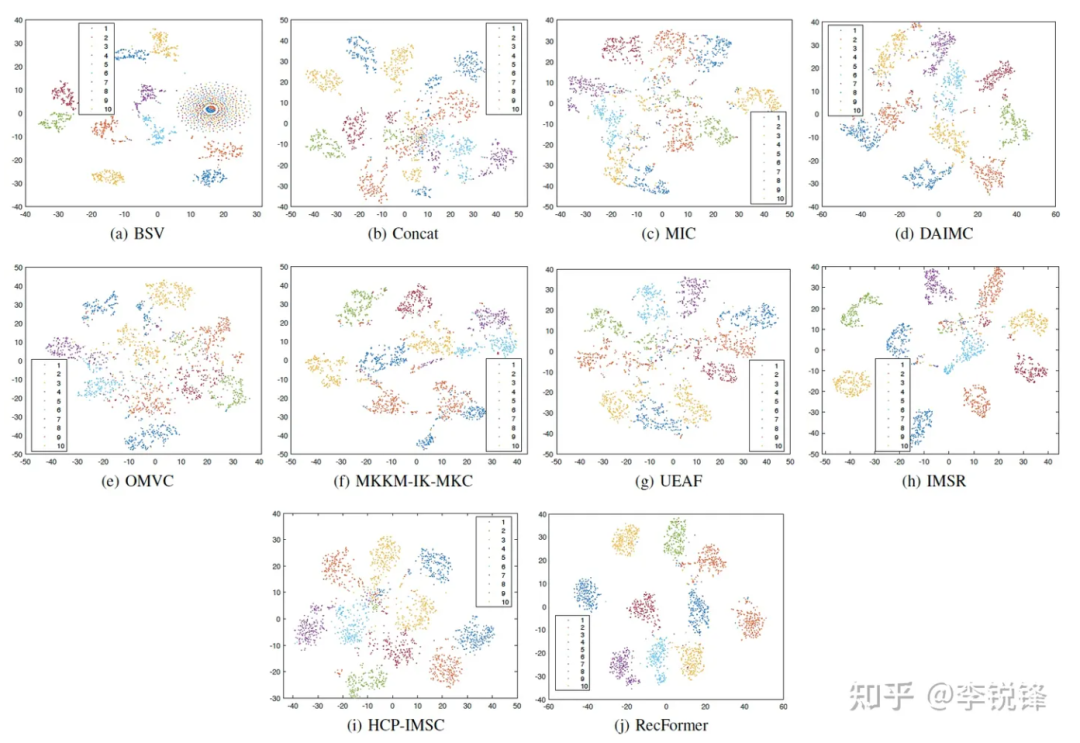
图3 关于聚类指示特征的t-SNE可视化结果
05 总结与展望
使用近邻图约束和自编码器对缺失视图进行复原的方法能够轻易地扩展到众多的不完备学习框架中并为之提供强大的视图恢复能力。缺失视图恢复技术也可以作为数据增强的有效手段丰富不完备多视图数据,提升不完备多视图聚类性能。本方法采用昇思MindSpore框架实现,其多样化的算子操作很好地满足了算法需求,丰富的使用说明进一步助力算法的快速实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









