






背景
在之前的文章中,我们介绍了三维形状表征(https://zhuanlan.zhihu.com/p/670504839)。与诸如点云或体素的3D形状表示相比,网格提供了更连贯的表面表示,它们更可控,更易于操作,更紧凑,同时也更接近网格生成后的下一步工作内容。
然而目前AI生成网格主要通过iso-surfacing方法,生成的三角形网格往往十分密集,否则会损失几何细节或者造成几何特征失真。近期,慕尼黑工业大学牵头发表了通过Decoder-only Transformer生成三角形网格的MeshGPT[1],在生成高质量紧凑网格方面取得了进展。
1、方法
MeshGPT主要由两个网络组成。首先通过Encoder-Decoder架构,学习到经过残差量化的三角形embeddings。而后通过Decoder-only GPT,生成紧凑三角形网格。
1.1 学习量化三角形embeddings
如图1所示,学习量化三角形embeddings主要分成四部分:
1)通过图卷积encoder,将输入的网格转换成rich features;
2)经过残差量化,将features量化为码表embeddings,这样可以有效减小序列长度,减轻transformer压力;
3)对embeddings进行排序;
4)通过一维ResNet,输出最简单的9通道网格embeddings。网络的输入和输出均为网格信息。
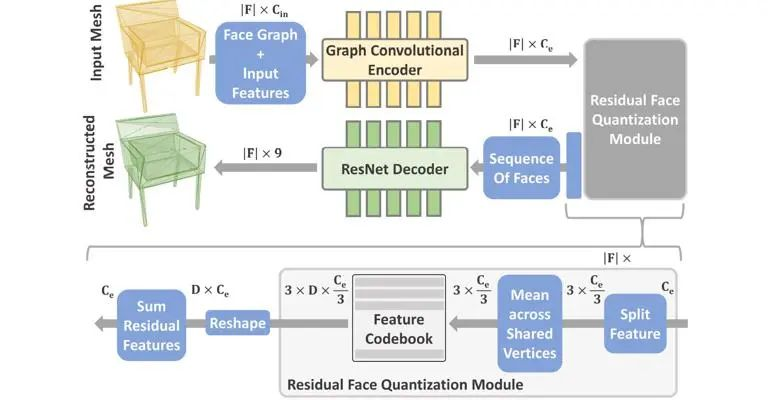
图1. 学习量化三角形embeddings的过程
(1) GraphSAGE作为encoder
本案例采用的encoder参考了PolyGen。但直接套用PolyGen会对接下来的transformer训练形成挑战,PolyGen采用离散坐标点作为token不能捕捉到几何特征,缺乏与临近网格的联系。因此本案例采用了图神经网络GraphSAGE[2]作为encoder。GraphSAGE的核心两点可以总结为:邻居采样和特征聚合。
具体地,GraphSAGE的SAGE Conv Layer将节点自身的属性特征与采样的邻居节点特征分别做一次线性变换(也就是乘一个W参数矩阵,一般还会加个relu激活增强表示),然后将两者连接起来,再进行一次线性变换得到目标节点的特征表示,如图2所示。GraphSAGE的实践发现,采样阶数k不必取很大的值,当k=2时,效果就非常好了,也就是只用扩展到2阶邻居即可。至于邻居的个数,文中提到S1×S2<=500,即两次扩展的邻居数之际小于500,大约每次只需要扩展20个邻居即可。
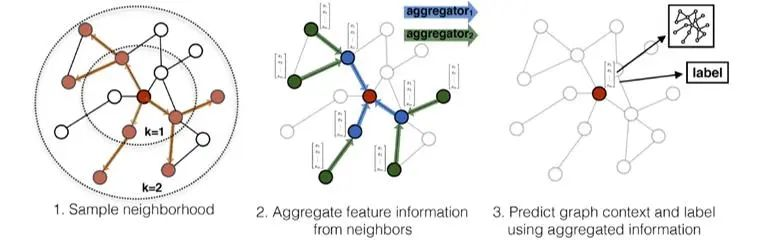
图2. GraphSAGE示意图
使用GraphSAGE的好处在于,通过邻居采样的方式可以解决GCN内存爆炸的问题,适用于大规模图;将直推式学习(transductive)转化为归纳式(inductive)学习,避免节点的特征每次都需要重训的情况,支持增量特征;引入邻居采样,会将直推式节点只表示一种局部结构转变为对应多种局部结构的节点归纳表示,可有效防止训练过拟合,增强泛化能力。
在本案例中,可以将每个网格面视作一个节点,与其相邻的面与它本身通过无方向线段连接,如图3所示。每个节点包括信息有:9个坐标值(三个顶点,每个顶点三维坐标)、面的法向方向、面的三个角的角度和面的面积。而后,经过多层前文提到的SAGE Conv Layer,将输入的网格转换成rich features。
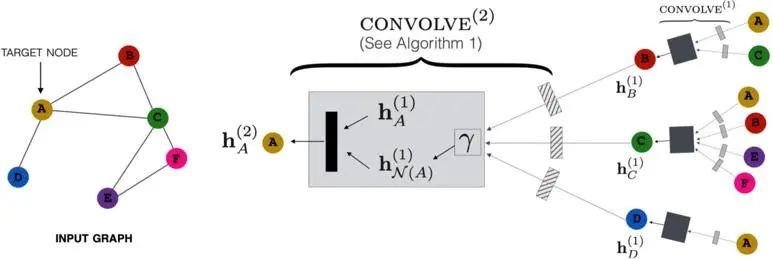
图3. 本案例中SAGE Conv Layer的应用
(2) 残差量化
如果直接使用上一节生成的rich features作为embeddings,即每个网格面使用单个code,会造成重构精度不足的现象。因此,本案例参考了残差向量量化(Residual vector Quantization,RQ)[3]的方法,每个面使用D个codes(D为RQ的深度)来进行改善。
残差量化应用了残差的思想,将原先的一层码本映射变成很多层映射,可以理解是用一个共享的码本去将原先的下采样的一个数值矩阵变成一个深度为D的向量矩阵,那么每个矩阵(i,j)位置对应的内容就成为了一个D维的向量,其中每个维度代表了一个残差层的结果。共享码本(也就是说D个层共用一个码本)的好处是:首先,使用单独的码本需要进行广泛的超参数搜索以确定每个深度的码本大小,但共享码本只需要确定总码本大小;其次,共享码本使每个量化深度的所有代码嵌入都可用,因此,代码可以在每个深度使用,以最大化其效用。
在本案例中,将特征通道分解到每个面的三个网格节点上,而后通过共享的网格节点聚合特征,每个节点保留D/3个codes,最终得到每个面的D个codes。这样在保证重建质量的前提下,能够降低其计算成本,提高生成速度。
(3) 一维ResNet作为Decoder
Decoder的应用较为简单。解码过程使用的是一维ResNet34网络。特别地,本案例发现相比于在连续实数域预测坐标,离散地预测往往效果更好(例如,准备一组离散的位置,给出在每个位置上的概率)。本案例也采用了这种方式。
1.2 Decoder-only GPT
本案例采用了GPT2-medium model,如图4所示。其输入为经过RQ量化的SAGE输出的embeddings。通过学到的离散位置encoding用来指明网格面的顺序。另外,注意到输出的网格节点是重复的(一点连接多面),额外使用了MeshLab来封闭节点。
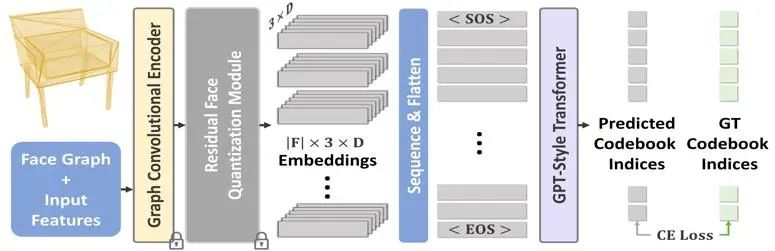
图4. 本文使用的Decoder-only GPT
2、实验与结果
本案例的实验中,Encoder-Decoder采用RQ深度为2,对应每个面的D为6,其中每个d有192个维度。Code book通过指数加权平均EWMA进行feature更新。采用的数据集为ShapeNetV2 Dataset,2张卡训练耗时约2天。GPT-2的context window选取为4608,需要4张卡训练约5天。
如图5,相比对比方案,本案例明显能够通过紧凑轻量的网格对三维几何进行更高精度的表示。

图5. 本案例生成的三维网格表示与其他方法的对比
3、感想
本案例整体架构思路清晰明确,在三维形状的网格表示上对准确性和细节处理成本改善明显。值得参考的地方在于:使用GraphSAGE对网格进行编码并进行RQ残差量化的整体思路和一些细节的处理,例如相比于在连续实数域预测坐标,离散地预测往往效果更好。
但同时也应该注意到,本案例的效果是基于在数据集中选取四类几何种类进行强化训练后得到的。因此,在几何种类增多的情况下网络的泛化性有待进一步考察。同时,科学计算场景下,需要考虑三维形状表征的网格与科学计算中的几何离散网格如何建立起更直接高效的匹配。
参考文献
[1] Siddiqui Y, Alliegro A, Artemov A, et al. MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers[J]. arXiv preprint arXiv:2311.15475, 2023. https://arxiv.org/abs/2311.15475
[2] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[J]. Advances in neural information processing systems, 2017, 30.
[3] Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









