






《昇思学习打卡营第五期·NLP特辑》的直播和打卡已全部完成。由打卡营优秀学员们输出的学习笔记同样值得我们研读和学习。本期技术文章由打卡营学员鲍迪输出并投稿。如果您也在本期打卡营中获益良多,欢迎私聊我们投稿。
成语释义与解析挑战
中文成语,汉语的瑰宝,承载着千年的文化传统和智慧积淀。它们通常由四字组成,形式简洁却内涵丰富,寥寥数语便能传递深刻的思想和情感。成语的理解和应用,不仅要求掌握其字面意义,更要洞悉其背后的文化和历史渊源。在人工智能领域,构建能够准确理解并恰当运用成语的模型,对于推动中文自然语言处理技术的发展具有重要意义。
这个赛题旨在挑战和提升模型对中文成语的深入理解能力。大家需要构建模型,通过理解成语在具体语境中的使用,从给定的候选成语中选择最合适的选项,填补文本中的空白。这一任务不仅考察模型对成语基本义项的掌握,更考验其对成语深层次含义及使用场景的精准把握。
数据集由2972条中文通俗介绍的句子组成,每条句子对应一个成语单词。对于每个句子需要提交最有可能的五个成语单词,五个成语中只要有一个是正确的即可。调用开源大模型利用其对中文语义的理解,生成语义所描述的成语。
数据集前10条文本:

使用自然语言指令驱使大模型对2972条这样的文义语句进行总结,每条语义可以总结为5个成语,其中有一个正确即可。这样的语义理解任务对于开源大模型的中文能力要求是相当高的,同时这样的半开放命题也是一个非常好的大模型技术学习机会。基于我们的调优手段,可以产生以下的调优思路:
1、选择中文表现优秀的大模型
2、对于选取优质的开源大模型进行成语语义文本的微调以提高生成表现
3、对于Prompt进行优化以获取更好的回答
4、对于Decoding策略进行优化,通过model.generate()参数的调整获取更好的回答
本文选取了能力优秀的Llama3-8B-Instruct模型作为大模型,使用Mindspore框架基于华为云Modelarts环境的NPU进行高效推理。
Llama3-8B-Instruct
Llama 3
2024年4月18日,Meta 重磅推出了Meta Llama 3,Llama 3是Meta最先进开源大型语言模型的下一代,包括具有80亿和700亿参数的预训练和指令微调的语言模型,能够支持广泛的应用场景。
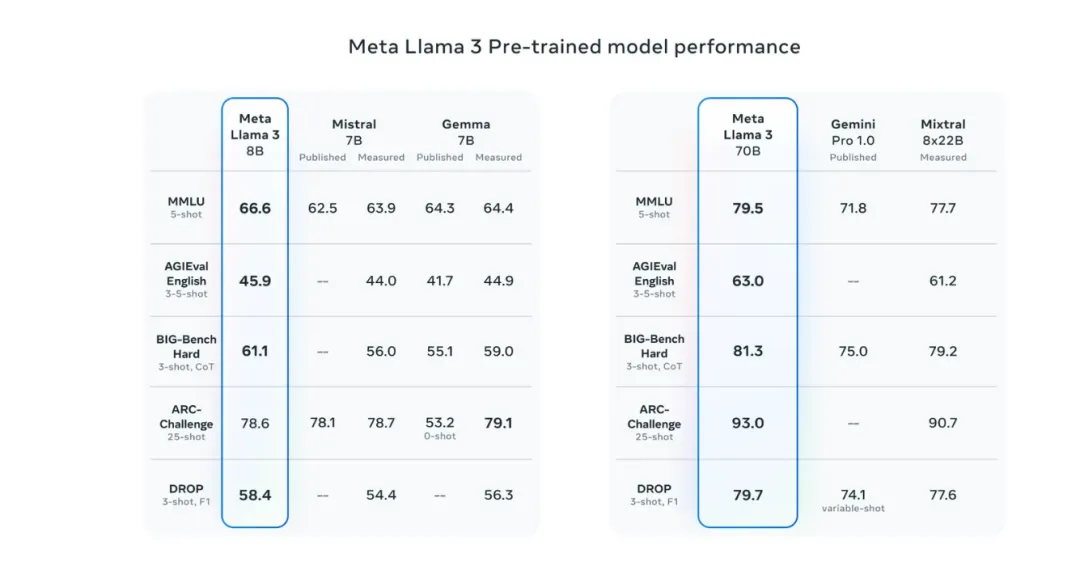
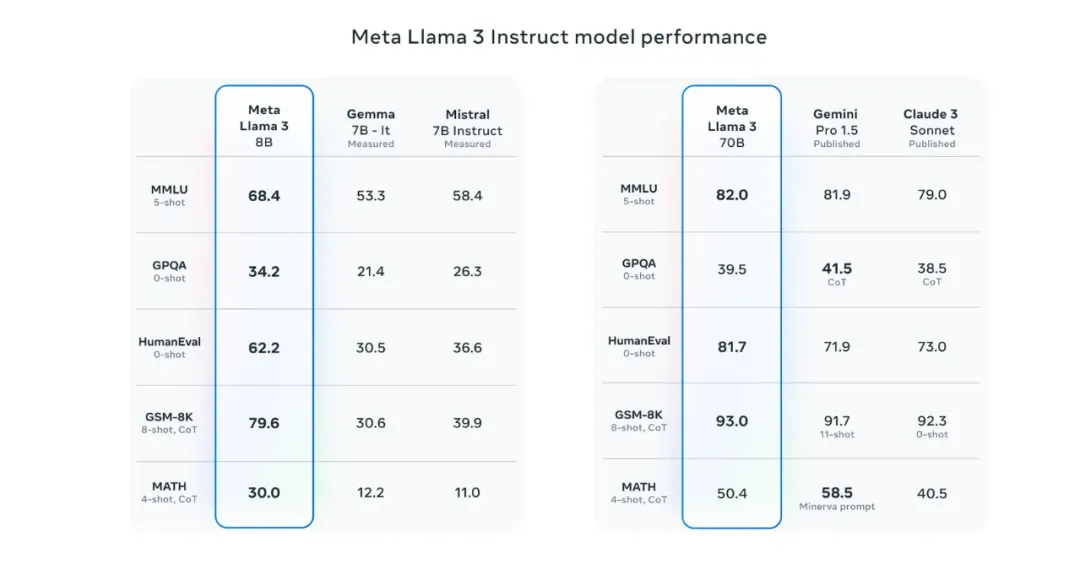
新的80亿和700亿参数的Llama 3模型在Llama 2的基础上取得了显著进展,为这类大规模语言模型(LLM)设立了新的行业标杆。通过预训练和后训练阶段的改进,这些模型在当前可用的80亿和700亿参数规模中表现最佳。这些改进还带来了推理能力、代码生成以及指令遵循方面的大幅提升,使得Llama 3模型变得更加易于操控和高效。因此,可以说,通过一系列优化措施,Llama 3在多个关键性能指标上实现了对前代产品的超越,展示了其在自然语言处理领域的强大竞争力。
Llama3-8B-Instruct
Meta-Llama-3-8B-Instruct是Meta公司开发的大型语言模型(LLM)系列中的一员。它是一个经过指令微调的80亿参数规模的模型,专门针对对话场景进行了优化。该模型是Meta Llama 3模型家族中的一个重要成员,旨在提供强大的自然语言处理能力,同时兼顾安全性和有用性。
模型特点
Meta-Llama-3-8B-Instruct模型具有以下几个主要特点:
1、参数规模: 拥有80亿参数,属于中等规模的语言模型。
2、上下文长度: 支持8k token的上下文窗口,可以处理较长的输入文本。
3、训练数据: 使用了15T以上的公开在线数据进行预训练。
4、知识截止: 模型的知识截止到2023年3月。
5、架构优化: 采用了优化的Transformer架构,并使用了分组查询注意力(GQA)机制来提高推理效率。
6、指令微调: 经过了监督微调(SFT)和基于人类反馈的强化学习(RLHF)的训练,以提高模型的有用性和安全性。
使用场景
Meta-Llama-3-8B-Instruct模型主要针对以下场景设计:
1、商业应用: 可用于开发各种商业化的自然语言处理应用。
2、研究用途: 适合进行自然语言处理相关的学术研究。
3、对话系统: 特别擅长处理类似人工助手的聊天任务。
4、英语处理: 主要针对英语语言进行了优化。
需要注意的是,该模型不应用于违反法律法规的用途,也不建议直接用于英语之外的语言处理任务。
MindSpore NLP适配
msrun是动态组网(https://www.mindspore.cn/docs/zh-CN/r2.4.1/model_train/parallel/dynamic_cluster.html)启动方式的封装,用户可使用msrun以单个命令行指令的方式在各节点拉起多进程分布式任务,并且无需手动设置动态组网环境变量(https://www.mindspore.cn/docs/zh-CN/r2.4.1/model_train/parallel/dynamic_cluster.html)。msrun同时支持Ascend,GPU和CPU后端。与动态组网启动方式一样,msrun无需依赖第三方库以及配置文件。
MindSpore NLP是基于MindSpore的一个自然语言处理(NLP)开源库,其中包含了许多自然语言处理的常用方法,提供了一个易用的NLP平台,旨在帮助研究人员和开发者更高效地构建和训练模型。
提供丰富的NLP数据处理模块,可灵活高效地完成数据预处理,包括Multi30k、SQuAD、CoNLL等经典数据集。
提供多种可配置神经网络组件,易于用户自定义模型,可大幅提升NLP任务建模的效率。
简化了MindSpore中复杂的训练过程,提供了灵活易用的 Trainer 和 Evaluator ,可以轻松地训练和评估模型
-
丰富完备的数据预处理模块
-
用户友好的NLP模型工具集
-
灵活易用的训练与推理引擎
-
完整的平台支持:全面支持 Ascend 910 series、Ascend 310B (Orange Pi)、GPU和CPU。(注意:目前 Orange Pi 上唯一可用的 AI 开发套件。
-
分布式并行推理:对超过 10B 参数的模型提供多设备、多进程并行推理支持。
-
量化算法支持:SmoothQuant 可用于 Orange Pi;GPU 支持类似 bitsandbytes 的 int8 量化。
-
Sentence Transformer 支持:实现高效的 RAG(检索增强生成)开发。
-
动态图性能优化:在 Ascend 硬件上实现动态图的 PyTorch+GPU 级推理速度(在 85 毫秒/令牌下测试 Llama 性能)。
-
真正的静态和动态图形统一:单行切换到图形模式,与 Hugging Face 代码风格完全兼容,既易于使用又能快速提升性能。在Ascend硬件上测试的Llama性能达到了2倍的动态图速度(45ms/token),与其他MindSpore基于静态图的套件一致。mindspore.jit
-
广泛的 LLM 应用程序更新:包括 Text information extraction、Chatbots、Speech recognition、ChatPDF、Music generation、Code generation、Voice clone 等。随着模型支持的增加,更多令人兴奋的应用程序等待开发!
-
MindSpore NLP对于Llama-3-8B-Instruct模型进行了适配,能够通过MindSporeNLP组件很方便地使用简短代码调用模型:
from mindnlp.transformers import AutoModel
model = AutoModel.from_pretrained('LLM-Research/Meta-Llama-3-8B-Instruct')复制-
代码仓中提供了基于Mindspore和mindnlp.transformers的Llama3脚本和分布式推理脚本
https://github.com/mindspore-lab/mindnlp/tree/master/llm/inference/llama3,使用者能够通过msrun和mpirun很方便地构建多个节点进行模型推理。
Baseline解读
步骤1:更新或安装所需环境
!pip install --upgrade modelscope requests urllib3 tqdm pandas mindspore mindnlp
!apt update > /dev/null; apt install aria2 git-lfs axel -y > /dev/null复制-
pip install --upgrade: 这个命令用于升级已安装的Python包到最新版本。--upgrade选项告诉pip检查并安装最新版本的指定包。
-
modelscope: ModelScope 是一个由阿里巴巴达摩院开源的模型即服务(MaaS)平台,旨在简化机器学习模型的使用流程,提供多种预训练模型,涵盖计算机视觉、自然语言处理、语音识别等多个领域。它集成了众多开源AI模型,涵盖了多个领域,开发者可以轻松找到满足自己需求的模型。ModelScope,开发者只需一行代码即可调用AI模型,极大地简化了模型调用过程。用户可以通过SDK或者WEB端的方式上传数据集,通过ModelScope或者公开Host托管。这是国内最大的大模型托管社区,类比为国内版hugging face.在这次代码中用来导入和运行大模型。
-
requests: Python的requests包是一个非常流行的HTTP请求库,广泛用于网络爬虫、API交互等场景。它简化了HTTP请求的复杂性,提供了简洁而强大的API,使得开发者可以轻松地发送HTTP请求并处理响应。
-
urllib3: urllib3 是一个功能强大且易于使用的 Python HTTP 客户端库,广泛应用于 Python 生态系统中。它提供了许多 Python 标准库 urllib 所不具备的重要特性,如线程安全、连接池管理、客户端 SSL/TLS 验证、文件分部编码上传、自动重试、支持压缩编码、支持 HTTP 和 SOCKS 代理等
-
tqdm: tqdm是一个快速、可扩展的Python进度条库,广泛用于在Python长循环中添加进度提示信息。它可以帮助用户监测程序运行的进度,估计运行时长,并且在调试时也非常有用。tqdm的主要功能是通过封装任意的迭代器来显示进度条,用户只需在循环中使用tqdm(iterator)即可。这次代码中是用来做进度条的。
-
pandas: Pandas 是一个强大的 Python 数据分析工具包,广泛应用于数据科学和数据分析领域。它提供了高效、灵活且易于使用的数据结构,旨在简化数据处理和分析任务。
在这次代码中发挥了以下作用
数据导入/导出:支持从多种文件格式(如 CSV、Excel、SQL、JSON 等)导入和导出数据。
数据清洗:提供丰富的函数和方法来处理缺失数据、重复数据和异常值。
-
aria2: Aria2 是一个轻量级的多协议、多源命令行下载工具,支持 HTTP/HTTPS、FTP、SFTP、BitTorrent 和 Metalink 协议。它可以通过内置的 JSON-RPC 和 XML-RPC 接口进行操作,非常适合用于批量下载和管理下载任务。
-
git-lfs: Git LFS(Large File Storage)是一个Git扩展,专门用于处理大型文件,如音频、视频、图像或任何其他二进制大文件。它通过将这些大文件存储在外部系统而不是Git仓库本身来优化性能,从而显著减小了Git仓库的大小,同时也保留了对大文件的版本控制能力。
-
axel: Python包之axel是一个用于加速文件下载的工具,它通过同时下载文件的不同部分并合并它们来提高下载速度。这个包是Axel命令行工具的Python实现,旨在帮助用户通过多线程下载来加速文件传输。
-
apt update: apt update 是一个用于更新软件包列表的命令,它在 Debian 和 Ubuntu 系统中广泛使用。这个命令的主要功能是从远程软件仓库获取最新的软件包元数据,并更新本地的软件包数据库。通过执行 apt update,系统可以确保在安装或升级软件包时,使用的是最新的可用版本。
-
/dev/null: 这个操作符将命令的输出重定向到/dev/null,即丢弃输出。这样可以避免在终端中显示更新过程中的详细信息。
-
apt install aria2 git-lfs axel -y: 这个命令用于安装指定的软件包。-y选项表示自动确认安装,不需要用户输入确认信息。
步骤2:下载数据集
!axel -n 12 -a https://ai-contest-static.xfyun.cn/2024/%E5%A4%A7%E6%A8%A1%E5%9E%8B%E8%83%BD%E5%8A%9B%E8%AF%84%E6%B5%8B%EF%BC%9A%E4%B8%AD%E6%96%87%E6%88%90%E8%AF%AD%E9%87%8A%E4%B9%89%E4%B8%8E%E8%A7%A3%E6%9E%90%E6%8C%91%E6%88%98%E8%B5%9B/test_input.csv复制下载数据集文件“test_input.csv”也可以从代码仓获取再手动上传。
步骤3:构建模型
import mindspore
from mindnlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "LLM-Research/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, mirror='modelscope')
model = AutoModelForCausalLM.from_pretrained(
model_id,
ms_dtype=mindspore.float16,
mirror='modelscope'
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=50,
eos_token_id=terminators,
# do_sample=False,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))复制导入mindnlp.transformers基于Modelarts提供的NPU环境进行高效推理:
1、使用AutoTokenizer导入模型Id和魔搭镜像,使用AutoModelForCausalLM规定模型Id、镜像和数据类型。
2、在messages类中规定系统提示词,并封装为输入提供给模型。
3、经过input_ids、terminators、outputs的传递,打印解码后的response。
4、得到一个针对"Who are you?"的回答,确认模型构建成功。
步骤4:读取数据集
import pandas as pd
test = pd.read_csv('./test_input.csv', header=None)复制从pandas类里拿出pd工具,这个用来读取表格test_input.csv里的2972条短句,然后全部赋值给test。
步骤5:输出成语
from tqdm import tqdm
import os
i = 1
# 假设 test 是一个 DataFrame
# 遍历测试数据集的第一项的值,目的是生成与给定句子最相关的五个成语
for test_prompt in tqdm(test[0].values, total=len(test[0].values), desc="处理进度"):
i = i + 1
# 构造提示信息,要求模型输出与句子最相关的五个成语
prompt = f"列举与下面句子最符合的五个成语。只需要输出五个成语,不需要有其他的输出,写在一行中:{test_prompt}"
# 初始化一个长度为5的列表,填充默认成语“同舟共济”
words = ['同舟共济'] * 5
# 构建聊天消息格式,用于提示模型进行生成
messages = [
{"role": "system", "content": "You are a helpful chinese teacher."},
{"role": "user", "content": f"{prompt}"},
]
# 应用聊天模板对消息进行处理,准备模型输入
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
# 对输入文本进行编码,准备模型输入数据
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
# 生成回答,限制最大生成长度
outputs = model.generate(
input_ids,
max_new_tokens=100,
eos_token_id=terminators,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
do_sample=False,
#length_penalty=1.0,
)
# 提取模型输出,去除输入部分
response = outputs[0][input_ids.shape[-1]:]
# 解码模型输出,去除特殊标记
response = tokenizer.decode(response, skip_special_tokens=True)
# 清理回答文本,确保格式统一
response = response.replace('\n', ' ').replace('、', ' ')
# 提取回答中的成语,确保每个成语长度为4且非空
words = [x for x in response.split() if len(x) == 4 and x.strip() != '']
# 如果生成的成语列表长度不满足要求(即20个字符),则使用默认成语列表
#if len(' '.join(words).strip()) != 24:
# words = ['同舟共济'] * 5
while True:
text = ' '.join(words).strip()
if len(text) < 24:
words.append('同舟共济')
else:
break
# 将最终的成语列表写入提交文件
with open('submit.csv', 'a+', encoding='utf-8') as up:
up.write(' '.join(words) + '\n')
# 查看阶段性结果
if i % 50 == 0:
tqdm.write(f"大模型第{i}次返回的结果是:\n {response}\n")
tqdm.write(f"submit.cvs第{i}行输出结果:\n {words}\n")
# 为了尽快拿到结果,我们暂时仅获得500个结果(如果有时间的话,可以删除这两行)
if i == 2973:
break
print('submit.csv 已生成')复制1、使用test_prompt在每一个循环中从test列表中获取一个成语语义描述;
2、从test_prompt中获取成语表述,以更新每个循环提交给模型的prompt;
3、利用构建成功的模型获得输出response;
4、解码并清理response,除去标点符号等,提取成语填充进words的一行中;
5、判断words的一行中成语是否够5个,不足的就用‘同舟共济’补足;
6、讲这一行5个成语写入'submit.csv'中,并开启下一个循环,直到循环结束。
单卡推理脚本
# llama3-8b-instruct.py
# 安装依赖 Terminal 中执行
# pip install --upgrade modelscope requests urllib3 tqdm pandas mindspore mindnlp
# pip uninstall mindformers
# Modelarts中可以不执行此句
#!apt update > /dev/null; apt install aria2 git-lfs axel -y > /dev/null
import mindspore
from mindnlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "LLM-Research/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, mirror='modelscope')
model = AutoModelForCausalLM.from_pretrained(
model_id,
ms_dtype=mindspore.float16,
mirror='modelscope'
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=50,
eos_token_id=terminators,
# do_sample=False,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
import pandas as pd
test = pd.read_csv('./test_input.csv', header=None)
from tqdm import tqdm
import os
i = 1
# 假设 test 是一个 DataFrame
# 遍历测试数据集的第一项的值,目的是生成与给定句子最相关的五个成语
for test_prompt in tqdm(test[0].values, total=len(test[0].values), desc="处理进度"):
i = i + 1
# 构造提示信息,要求模型输出与句子最相关的五个成语
prompt = f"列举与下面句子最符合的五个成语。只需要输出五个成语,不需要有其他的输出,写在一行中:{test_prompt}"
# 初始化一个长度为5的列表,填充默认成语“同舟共济”
words = ['同舟共济'] * 5
# 构建聊天消息格式,用于提示模型进行生成
messages = [
{"role": "system", "content": "You are a helpful chinese teacher."},
{"role": "user", "content": f"{prompt}"},
]
# 应用聊天模板对消息进行处理,准备模型输入
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
# 对输入文本进行编码,准备模型输入数据
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
# 生成回答,限制最大生成长度
outputs = model.generate(
input_ids,
max_new_tokens=100,
eos_token_id=terminators,
no_repeat_ngram_size=2,
num_beams=5,
num_return_sequences=5,
do_sample=False,
remove_invalid_values=True,
#temperature=0.6,
#top_p=0.9,
#top_k=50,
#length_penalty=1.0,
)
# 提取模型输出,去除输入部分
response = outputs[0][input_ids.shape[-1]:]
# 解码模型输出,去除特殊标记
response = tokenizer.decode(response, skip_special_tokens=True)
# 清理回答文本,确保格式统一
response = response.replace('\n', ' ').replace('、', ' ')
# 提取回答中的成语,确保每个成语长度为4且非空
words = [x for x in response.split() if len(x) == 4 and x.strip() != '']
# 如果生成的成语列表长度不满足要求(即20个字符),则使用默认成语列表
#if len(' '.join(words).strip()) != 24:
# words = ['同舟共济'] * 5
while True:
text = ' '.join(words).strip()
if len(text) < 24:
words.append('同舟共济')
else:
break
# 将最终的成语列表写入提交文件
with open('submit.csv', 'a+', encoding='utf-8') as up:
up.write(' '.join(words) + '\n')
# 查看阶段性结果
if i % 50 == 0:
tqdm.write(f"大模型第{i}次返回的结果是:\n {response}\n")
tqdm.write(f"submit.cvs第{i}行输出结果:\n {words}\n")
# 完整的循环数为2973,如果想要测试,可以设置为10
if i == 2973:
break
print('submit.csv 已生成')复制分布式推理脚本
使用动态组网,自行定义节点数量和主端口,拉起分布式任务。
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 --join=True llama3-8b-instruct-distributed.py复制或者使用MPI组网。
mpirun -n 2 python llama3-8b-instruct-distributed.py复制导入mindspore.communication库的Init类,并使用init()初始化计算实例,让代码在多个节点中运行。
# llama3-8b-instruct-distributed.py
# 安装依赖 Terminal 中执行
# pip install --upgrade modelscope requests urllib3 tqdm pandas mindspore mindnlp
# pip uninstall mindformers
# Modelarts中可以不执行此句
#!apt update > /dev/null; apt install aria2 git-lfs axel -y > /dev/null
# msrun --worker_num=2 --local_worker_num=2 --master_port=8118 --join=True llama3-8b-instruct-distributed.py
import mindspore
from mindspore.communication import init
from mindnlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "LLM-Research/Meta-Llama-3-8B-Instruct"
init()
tokenizer = AutoTokenizer.from_pretrained(model_id, mirror='modelscope')
model = AutoModelForCausalLM.from_pretrained(
model_id,
ms_dtype=mindspore.float16,
mirror='modelscope'
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=50,
eos_token_id=terminators,
# do_sample=False,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
import pandas as pd
test = pd.read_csv('./test_input.csv', header=None)
from tqdm import tqdm
import os
i = 1
# 假设 test 是一个 DataFrame
# 遍历测试数据集的第一项的值,目的是生成与给定句子最相关的五个成语
for test_prompt in tqdm(test[0].values, total=len(test[0].values), desc="处理进度"):
i = i + 1
# 构造提示信息,要求模型输出与句子最相关的五个成语
prompt = f"列举与下面句子最符合的五个成语。只需要输出五个成语,不需要有其他的输出,写在一行中:{test_prompt}"
# 初始化一个长度为5的列表,填充默认成语“同舟共济”
words = ['同舟共济'] * 5
# 构建聊天消息格式,用于提示模型进行生成
messages = [
{"role": "system", "content": "You are a helpful chinese teacher."},
{"role": "user", "content": f"{prompt}"},
]
# 应用聊天模板对消息进行处理,准备模型输入
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
# 对输入文本进行编码,准备模型输入数据
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
# 生成回答,限制最大生成长度
outputs = model.generate(
input_ids,
max_new_tokens=100,
eos_token_id=terminators,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
do_sample=False,
#length_penalty=1.0,
)
# 提取模型输出,去除输入部分
response = outputs[0][input_ids.shape[-1]:]
# 解码模型输出,去除特殊标记
response = tokenizer.decode(response, skip_special_tokens=True)
# 清理回答文本,确保格式统一
response = response.replace('\n', ' ').replace('、', ' ')
# 提取回答中的成语,确保每个成语长度为4且非空
words = [x for x in response.split() if len(x) == 4 and x.strip() != '']
# 如果生成的成语列表长度不满足要求(即20个字符),则使用默认成语列表
#if len(' '.join(words).strip()) != 24:
# words = ['同舟共济'] * 5
while True:
text = ' '.join(words).strip()
if len(text) < 24:
words.append('同舟共济')
else:
break
# 将最终的成语列表写入提交文件
with open('submit.csv', 'a+', encoding='utf-8') as up:
up.write(' '.join(words) + '\n')
# 查看阶段性结果
if i % 50 == 0:
tqdm.write(f"大模型第{i}次返回的结果是:\n {response}\n")
tqdm.write(f"submit.cvs第{i}行输出结果:\n {words}\n")
# 完整的循环数为2973,如果想要测试,可以设置为10
if i == 2973:
break
print('submit.csv 已生成') |复制参考文章
[1] https://blog.csdn.net/qq_41185868/article/details/137981416
[1] https://www.dongaigc.com/p/meta-llama/Meta-Llama-3-8B-Instruct


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









