







在Ubuntu 22.04系统中,我安装了当前最新的AMD AI平台ROCm6.1.1,并使用了两张显存容量为24GiB的RX 7900XTX显卡,在本地跑LLMs大语言模型推理任务。
我选择了GitHub开源的两种方式在AMD显卡上部署大语言模型,分别如下:
- ollama
- text-generation-webui
在装入双7900XTX前,我首先测试了单张7900XTX运行ollama或text-gen-webui进行文字生成的情况。从huggingface下载的llama2-7b-chat-hf/llama2-13b/qwen/chatglm3等模型都可以顺利调用显卡的计算资源并且快速生成文字内容。生成的文字内容清晰可读符合逻辑。
接着,我装入两张7900XTX,开机并使用amd-smi和rocminfo等工具查看两张显卡的待机情况,如图:
输入rocminfo指令,可以看到ROCm6.1.1已经正常识别到两个Agent,代表两块7900XTX
输入amd-smi指令,查看两块卡的当前状态

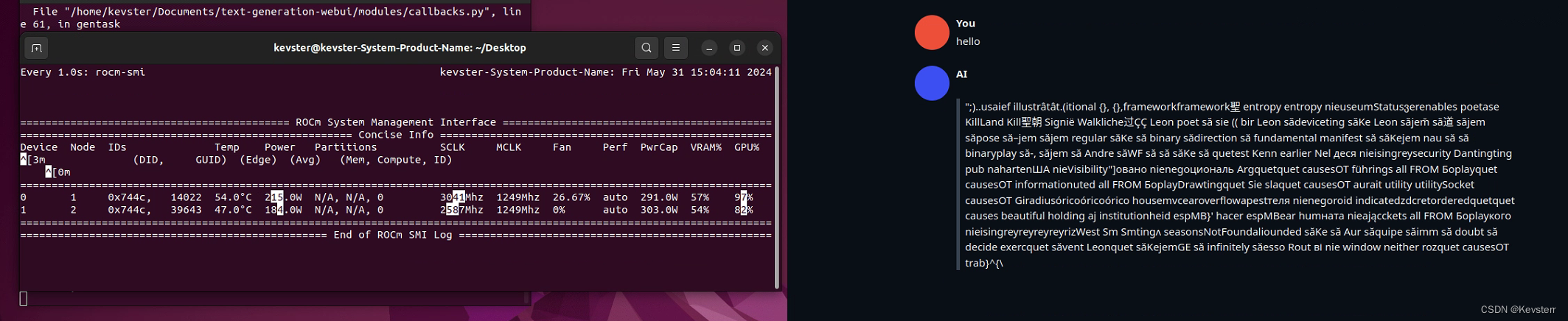
显卡的准备工作完成,接下来分别在ollama和text-gen-webui运行llama2-13b模型,发现生成的内容全是乱码,如图片所示
text-gen-webui:llama2-13b-chat-hf
ollama:llama2-13b
解决方案
关闭IOMMU(Input/Output Memory Management Unit)或将IOMMU设置为Passthrough模式可解决该问题,具体方法如下:
用gedit编辑器打开grub
![]()
添加iommu=pt以指定passthrough模式
![]()
更新grub
![]()
重启
![]()
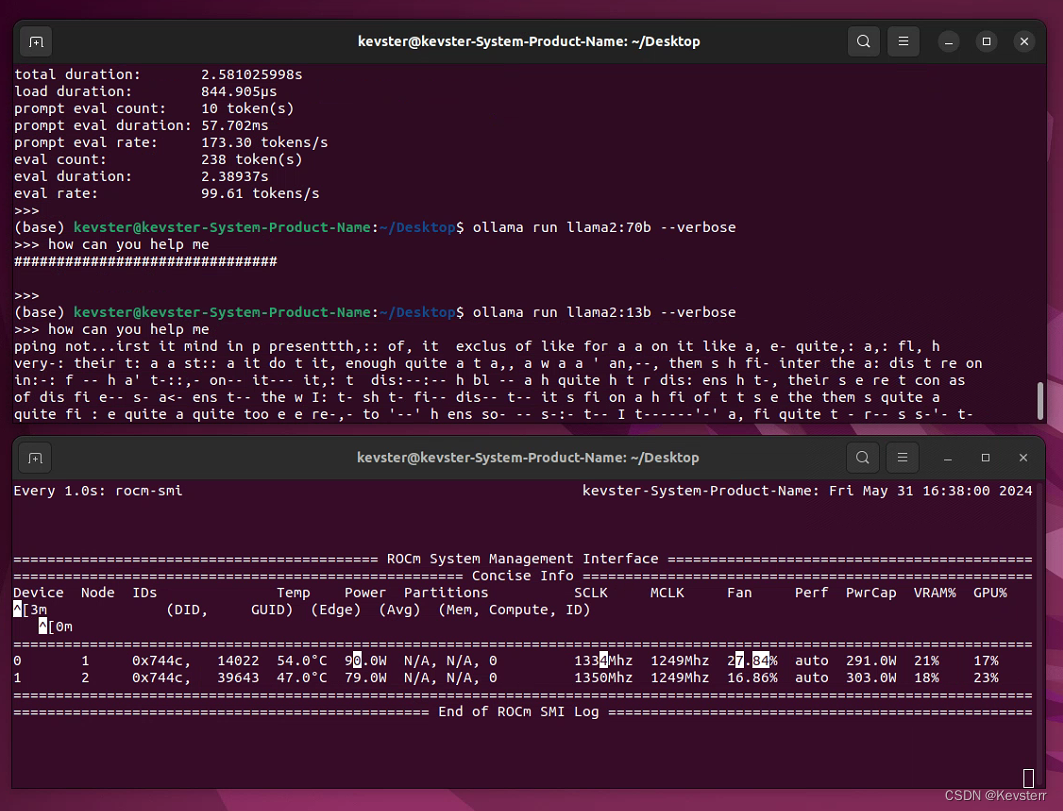
重启后,再次启用ollama或text-gen-webui进行大语言模型生成文字,一切正常
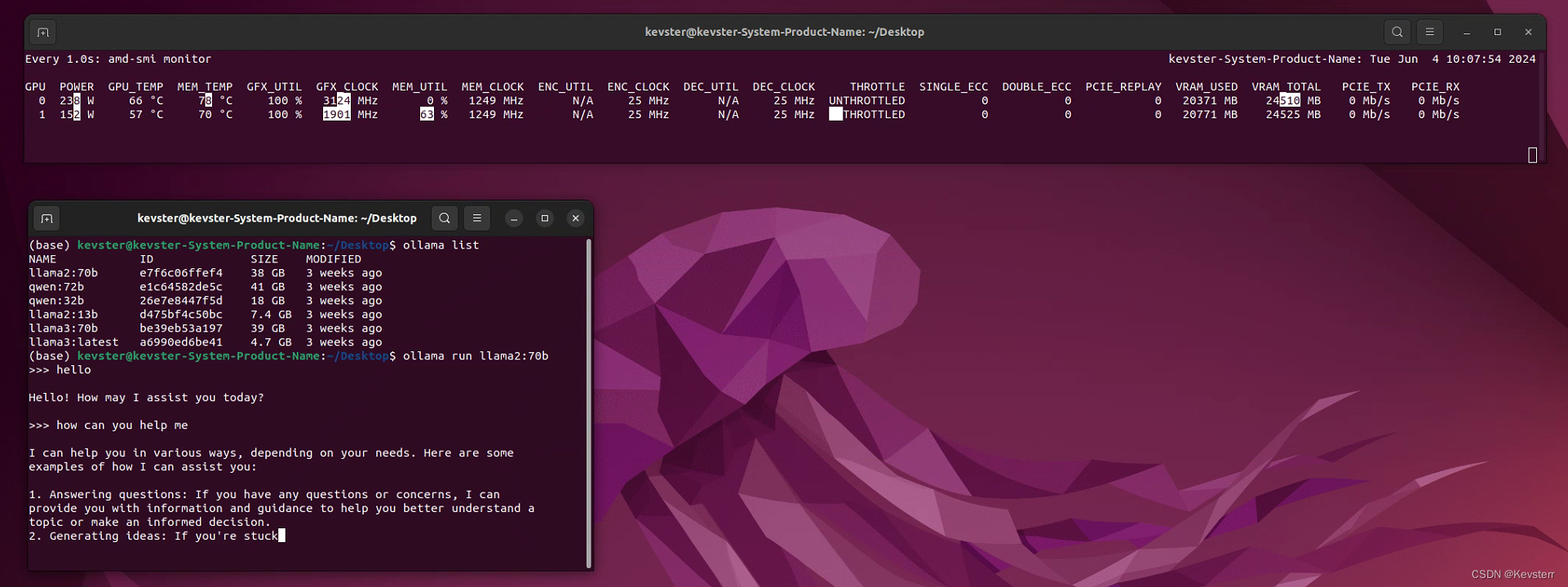
ollama:llama2-70b
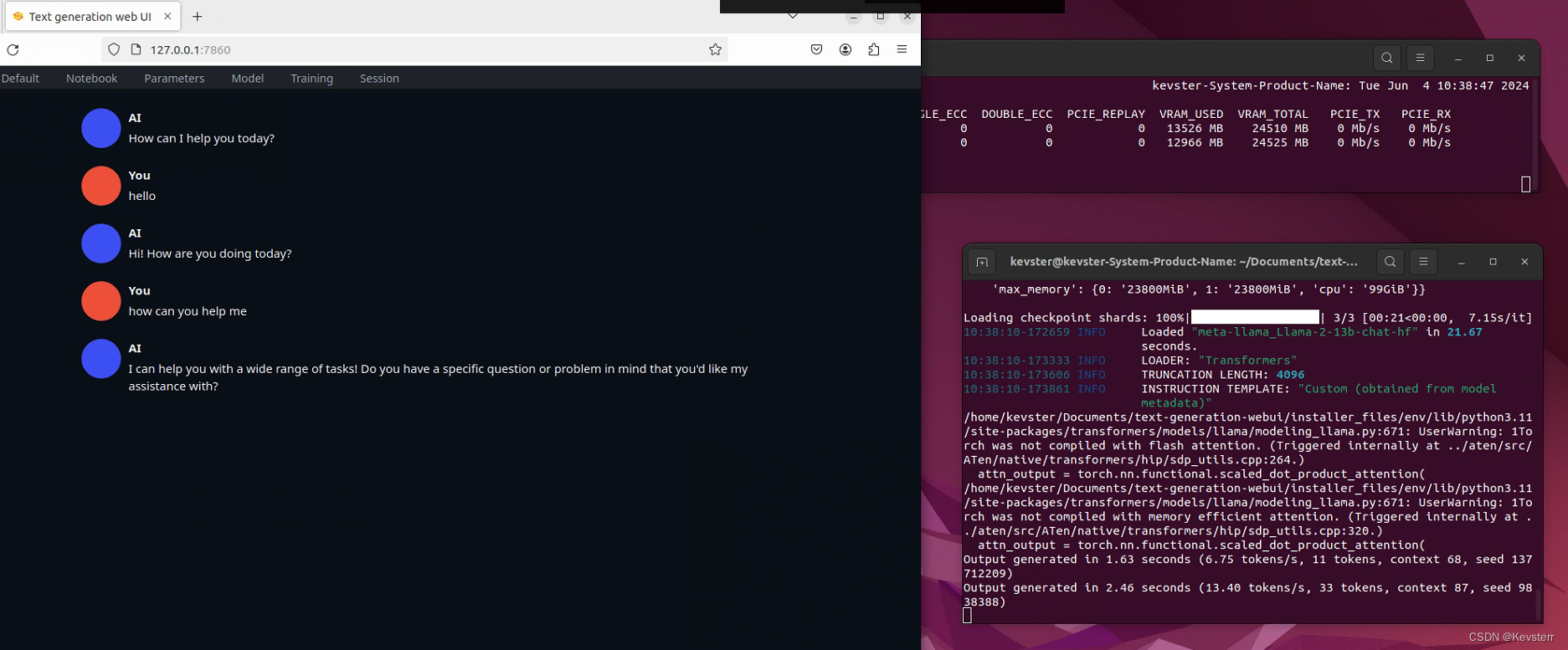
text-gen-webui:llama2-13b

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









