







序列化是指将数据从有结构清晰的语言定义的数据形式转化为二进制字符串,反序列化则是序列化的逆操作。
百度百科定义序列化如下:
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
关于序列化,其实在MapBox中就已经有雏形。MapBox的作法是使用map<string,string>作为底层容器,第一元素为 Tag标签,第二元素为 Context内容。方法toString()能够将MapBox转化为一个字符串,这个过程中MapBox是使用base64编码+特殊字符实现的。MapBox没有提供反序列化方法,只是在通过网络接收数据的时候能够 将字符串解析为MapBox。(毕竟MapBox的设计初衷就是网络编程,起初打算打造一个MapBox over socket的东西...,但是发现base64本身存在的缺点在数据量暴涨的时候大于base64的优点,于是放弃了MapBox over socket的设计。但是现在MapBox在传输不超过200MB的内容时仍然具有较好的表现)
最近翻了翻MapBox,序列化与反序列化的想法又冒了出来。Protocol Buffer的话,需要调用谷歌自己的编译程序(把rule编译为header),感觉比较麻烦(不过比其他的工具简单不少了)。Boost库的话,序列化倒是很方便,但是看了源码之后发现各种模板暂时理解不能... 所以还是想自己写一个小东西试一试。
于是就有了这么个东西 ( View Source On GitHub )
/** Templates */
template<typename T>
string serialize(const T& a)
{
return T::serialize(a);
}
template<typename T>
int deserialize(string str,T& a)
{
return T::deserialize(str,a);
}
/** Special Version
* For...
* int, double, float
*/
/// int
template<>
string serialize(const int& a)
{
string ans;
int c=htonl(a);
ans.append((const char*)&c,sizeof(c));
return ans;
}
template<>
int deserialize(string str,int& c)
{
memcpy(&c,str.data(),sizeof(c));
c=ntohl(c);
return sizeof(c);
}
/// string
template<>
string serialize(const string& a)
{
int len=a.size();
string ans;
ans.append(::serialize(len));
ans.append(a);
return ans;
}
template<>
int deserialize(string str,string& a)
{
int len;
::deserialize(str,len);
a=str.substr(sizeof(len),len);
return sizeof(int)+len;
}
/// Marco definition
#define NORMAL_DATA_SERIALIZE(Type) template<> \
string serialize(const Type& a) \
{ \
string ans; \
ans.append((const char*)&a,sizeof(a)); \
return ans; \
}
#define NORMAL_DATA_DESERIALIZE(Type) template<> \
int deserialize(string str,Type& a)\
{ \
memcpy(&a,str.data(),sizeof(a)); \
return sizeof(a); \
}
针对POD而且不需要字节序转换的宏定义
/// double
NORMAL_DATA_SERIALIZE(double);
NORMAL_DATA_DESERIALIZE(double);
NORMAL_DATA_SERIALIZE(float);
NORMAL_DATA_DESERIALIZE(float);
NORMAL_DATA_SERIALIZE(char);
NORMAL_DATA_DESERIALIZE(char);
template<typename SerializableType>
class Serializable
{
public:
static SerializableType deserialize(string);
static string serialize(const SerializableType& a);
};
class OutEngine
{
public:
template<typename SerializableType>
OutEngine& operator << (SerializableType& a)
{
string x=::serialize(a);
os.write(x.data(),x.size());
return *this;
}
string str()
{
return os.str();
}
void set_empty()
{
os.str("");
}
OutEngine():os(std::ios::binary){}
public:
ostringstream os;
};
class InEngine
{
public:
InEngine(string s) : is(s){n_size=leftsize();}
template<typename SerializableType>
InEngine& operator >> (SerializableType& a)
{
int ret=::deserialize(is,a);
is=is.substr(ret);
return *this;
}
void set_str(string s)
{
is=s;
n_size=leftsize();
}
int leftsize()
{
return is.size();
}
int donesize()
{
return n_size-leftsize();
}
protected:
string is;
int n_size;
};测试代码如下
注: 三个成员设计为public是因为方便main里面的代码
class cbox : public Serializable<cbox>
{
public:
int a;
double b;
string str;
static string serialize(const cbox& inc)
{
OutEngine x;
x<<inc.a<<inc.b<<inc.str;
return x.str();
}
static int deserialize(string inc,cbox& box)
{
InEngine x(inc);
x>>box.a>>box.b>>box.str;
return x.donesize();
}
};
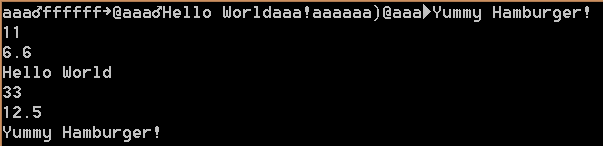
int main()
{
cbox box;
box.a=11;
box.b=6.6;
box.str="Hello World";
cbox box3;
box3.a=33;
box3.b=12.5;
box3.str="Yummy Hamburger!";
OutEngine oe;
oe<<box<<box3;
string b=oe.str();
cout<<b<<endl;
cbox box2;
cbox box4;
InEngine ie(b);
ie>>box2>>box4;
cout<<box2.a<<endl;
cout<<box2.b<<endl;
cout<<box2.str<<endl;
cout<<box4.a<<endl;
cout<<box4.b<<endl;
cout<<box4.str<<endl;
return 0;
}输出内容(二进制字串在不同设备上的输出应该是不同的,但是内容应该是一致的)















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









