







点击流的概念
点击流(Click Stream)是指用户在网站上持续访问的轨迹。这个概念更注
重用户浏览网站的整个流程。用户对网站的每次访问包含了一系列的点击动作行
为,这些点击行为数据就构成了点击流数据(Click Stream Data),它代表了用
户浏览网站的整个流程。
点击流和网站日志是两个不同的概念,点击流是从用户的角度出发,注重用
户浏览网站的整个流程;而网站日志是面向整个站点,它包含了用户行为数据、
服务器响应数据等众多日志信息,我们通过对网站日志的分析可以获得用户的点
击流数据。
网站是由多个网页(Page)构成,当用户在访问多个网页时,网页与网页之
间是靠 Referrers 参数来标识上级网页来源。由此,可以确定网页被依次访问的
顺序,当然也可以通过时间来标识访问的次序。其次,用户对网站的每次访问,
可视作是一次会话(Session),在网站日志中将会用不同的 Sessionid 来唯一标
识每次会话。如果把 Page 视为“点”的话,那么我们可以很容易的把 Session
描绘成一条“线”,也就是用户的点击流数据轨迹曲线。
1 点击流模型生成
点击流数据在具体操作上是由散点状的点击日志数据梳理所得。点击数据在
数据建模时存在两张模型表 Pageviews 和 visits,例如:

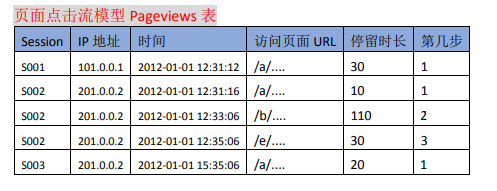
页面点击流模型 Pageviews 表
点击流模型 Visits 表(按 session 聚集的页面访问信息)

常见的数据采集信息
1、访客ip地址:
例如: 58.215.204.118
2、访客用户信息: - -
3、请求时间:
例如: [18/Sep/2013:06:51:35 +0000]
4、请求方式:
例如:GET
5、请求的url:
例如: /wp-includes/js/jquery/jquery.js?ver=1.10.2
6、请求所用协议:
例如:HTTP/1.1
7、响应码:
例如: 304
8、返回的数据流量:
例如: 0
9、访客的来源url:
例如: http://blog.fens.me/nodejs-socketio-chat/
10、访客所用浏览器:
例如: Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
**
pageview模型和visit模型

点击流型pageview的代码实现
import cn.itcast.bigdata.weblog.mrbean.WebLogBean;
import cn.itcast.bigdata.weblog.utils.DateUtil;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.net.URI;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*;
/**
*
* 将清洗之后的日志梳理出点击流pageviews模型数据
*
* 输入数据是清洗过后的结果数据
*
* 区分出每一次会话,给每一次visit(session)增加了session-id(随机uuid)
* 梳理出每一次会话中所访问的每个页面(请求时间,url,停留时长,以及该页面在这次session中的序号)
* 保留referral_url,body_bytes_send,useragent
*
* 判断同一个用户两次的时间间隔,如果小于30分钟,就认为是同一个session,如果大于30分钟就认为是多个session
* 第一步:将同一个用户的所有的数据都找出来,发送到同一个reduce里面去,进行判断
* 用什么来做K2,会将我同一个用的数据都发送到同一个reduce里面去,通过IP来进行区分不同的用户
*
*
*
*
*
*
使用IP作为key2
集合当中的数据,先按照时间进行排序 比较下一条与上一条数据之间的时间间隔
如果时间间隔小于三十分 session的标识,我们不需要改动,编号顺序的网上涨
如果时间间隔大于三十分 session的标识,我们需要变动,编号顺序从1开始网上涨
*
* @author
*
*/
public class ClickStreamPageView extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
String inputPath="hdfs://node01:8020/weblog/"+DateUtil.getYestDate()+"/weblogPreOut";
String outputPath="hdfs://node01:8020/weblog/"+DateUtil.getYestDate()+"/pageViewOut";
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:8020"), conf);
if (fileSystem.exists(new Path(outputPath))){
fileSystem.delete(new Path(outputPath),true);
}
fileSystem.close();
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F:\\日志文件数据\\weblogPreOut2"));
TextOutputFormat.setOutputPath(job,new Path("file:///F:\\日志文件数据\\pageViewOut2"));
job.setJarByClass(ClickStreamPageView.class);
job.setMapperClass(ClickStreamMapper.class);
job.setReducerClass(ClickStreamReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(WebLogBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
boolean b = job.waitForCompletion(true);
return b?0:1;
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









