







想了想,为了避免遗忘和方便回顾,还是记录一下,传统笔记似乎不太合适,就网上记了。
2023-2-23
*题目来自LeetCode,并用Python完成
1.Fizz Buzz
题目要求
给你一个整数 n ,找出从 1 到 n 各个整数的 Fizz Buzz 表示,并用字符串数组 answer(下标从 1 开始)返回结果,其中:
answer[i] == "FizzBuzz" 如果 i 同时是 3 和 5 的倍数。
answer[i] == "Fizz" 如果 i 是 3 的倍数。
answer[i] == "Buzz" 如果 i 是 5 的倍数。
answer[i] == i (以字符串形式)如果上述条件全不满足。
示例 1:
输入:n = 3
输出:["1","2","Fizz"]
示例 2:
输入:n = 5
输出:["1","2","Fizz","4","Buzz"]
示例 3:
输入:n = 15
输出:["1","2","Fizz","4","Buzz","Fizz","7","8","Fizz","Buzz","11","Fizz","13","14","FizzBuzz"]
实现
自己实现的时候很简单的考虑为能同时被3、5整除即给列表新增元素'FizzBuzz',仅能被3整除新增'Fizz',仅能被5整除新增'Buzz',都不满足则赋值当前数字的字符。
class Solution:
def fizzBuzz(self, n: int) -> List[str]:
answer = []
for i in range(1,n+1):
if i % 3 == 0:
if i % 5 == 0:
answer.append('FizzBuzz')
else:
answer.append('Fizz')
elif i % 5 == 0:
answer.append('Buzz')
else:
answer.append(str(i))
return answer查看官方的解题,发现是考虑的是通过字符串的拼接来实现
class Solution:
def fizzBuzz(self, n: int) -> List[str]:
answer = []
for i in range(1,n+1):
s = ""
if i % 3 == 0:
s += "Fizz"
if i % 5 ==0:
s += "Buzz"
if s == "":
s += str(i)
answer.append(s)
return answer官方拼接字符串的思路执行效率高于我自己的思路,但是消耗内存略多一点。
2.计数质数
题目要求
给定整数 n ,返回 所有小于非负整数 n 的质数的数量 。
示例 1:
输入:n = 10
输出:4
解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
示例 2:
输入:n = 0
输出:0
示例 3:
输入:n = 1
输出:0
思路
枚举
很直接可以想到用枚举一个一个的判断来解决,刚开始写的时候记得可以减半区间来判断,但是记不准确,就直接全部枚举(后续发现为:如果y是x的因数,那么x/y也是x的因数,因此只需校验y或者x/y即可。而如果我们每次选择校验两者中的较小数,则不难发现较小数一定落在 [2,sqrt(x)]的区间中,因此我们只需要枚举 [2,sqrt(x)]所有数即可,可以降低时间复杂度。)
class Solution:
def countPrimes(self, n: int) -> int:
if n <= 2:
return 0
count = 1
for i in range(3,n):
flag = 1
for j in range(2,i):
if i % j == 0:
flag = 0
break
if flag == 1:
count +=1
return count采用这种暴力的解法理论上是可行的,但是实际运行超时了。。。即使是只枚举[2,sqrt(x)]的所有数也会超时。所以此题只能寻求更好的办法完成。
埃氏筛
基于这样一个事实:如果x是质数,那么2x、3下、...一定不是质数,由此入手。
我们设 isPrime[i]表示数 i 是不是质数,如果是质数则为 1,否则为 0。从小到大遍历每个数,如果这个数为质数,则将其所有的倍数都标记为合数(除了该质数本身),即 000,这样在运行结束的时候我们即能知道质数的个数。
class Solution:
def countPrimes(self, n: int) -> int:
isPrimes = [1]*n
count = 0
for i in range(2,n):
if isPrimes[i]:
count += 1
j = 2
while j*i < n:
isPrimes[i*j] = 0
j += 1
return count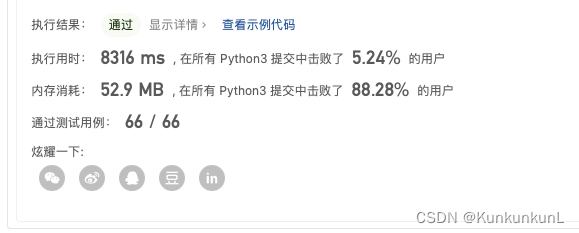
执行时间依旧不是很短= =,再此基础上还可以再进行优化。从2x开始其实是有冗余的,比如5将会标记15,但是15在之前就已经被3标记过了,造成了重复。所以应当从x*x开始标记。
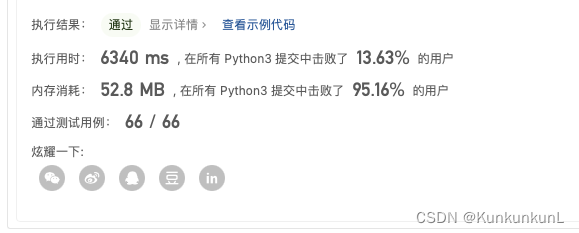
确实有了一定的提高。
另外还提到有线性筛。。。就先不深究了















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









