







1、Zookeeper原理、结构——Kuring 经典
本文会从zookeeper的基础原理出发,整个服务的组成与实现,对于相关技术会有说明,为提升阅读效率不做过多解释。
zookeeper组成:
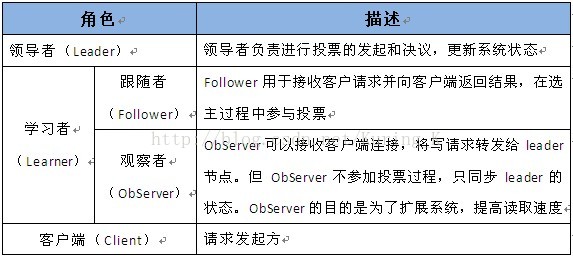
注:观察者(类似redis的备份)只接受INFORM消息,不包括提议proposal,可用于不同数据中心的数据交换,简单的说,主要用于读取,转发请求给Leader,且不处理事务,不会增加高可用性。
Zookeeper作为
分布式文件同步监听系统。
Zookeeper的核心是 原子广播(Zab),这个机制保证了各个Server之间的同步。
实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,
zookeeper采用了递增的事务id号(zxid)来标识事务
。
一、请求、事务、标识符
zookeeper 服务器会在本地处理只读请求,exists、getData、getChildren。
更改change类型请求,create、delete、setData,会发送给群首leader,由群首
执行相应的请求
并进行状态更新(transaction)
事务:
只有改变zookeeper状态的操作才会产生事务,读操作不会有事务
。
更改状态请求携带两个数据:节点新值、节点新版本号(mZxid、dataVersion等)。
zookeeper
支持事务的原子性操作,同时也支持幂等性操作
;也就是说同一个事物被完整的执行多次,也不会影响结果。
——leader在执行change请求的时会自动生成一个zxid,通过
zxid作为会话session的标识符
;只要follower按照群首指定zxid的顺序运行就能保证事务的原子性、幂等性,该过程对用户透明。
zxid 为一个long型64位整数,分为两部分:时间戳(epoch)、计数器(counter),各为32位。
二、群首选举

每个Server在工作过程中有三种状态:
- LOOKING:当前Server不知道leader是谁,正在搜寻。如果没有leader,进入群首选举通知leader election notifications。
leader election notifications:每当一个服务器进入LOOKING状态,就会广播一次消息:vote——sid(myid)、zxid(选举时zxid只有一个数字,在其他操作时为epoch和counter)
- LEADING:当前Server即为选举出来的leader
- FOLLOWING:leader已经选举出来,当前Server与之同步
选举过程:
1、leader election notifications:每当一个服务器进入LOOKING状态,就会广播一次消息:vote——sid(myid)、zxid(选举时zxid只有一个数字,在其他操作时为epoch和counter)
2、将接收到的消息中的voteId和voteZxid作为一个标识符,用mySid和myZxid表示自己服务器的值。
3、如果voteZxid>myZxid 或 voteZxid=myZxid and voteId>mySid,保留为新的投票消息,如果有同样的zid,其中sid最大的将被选中。
4、票数超过一半n/2将赢得选举,或重复投票(重新发起leader election notifications),直到选择出最新的zxid值得server作为leader。(不用确认票数)
5、选举完成后,参与选举的服务器会遵循选举最后结果进入LEADING或FOLLOWING状态,并相互连接。
6、leader和follower连接完成后,会进行
状态同步
,完成同步follower才能处理新的请求。
Java过程:
1、实现选举的类为QuorumPeer,其中run方法实现了服务器的主要循环。
2、当进入LOOKING状态,将会执行lookForLeader方法来进行群首的选举,该方法实现了选举协议。
3、该方法返回前会设置服务器状态为LEADING或FOLLOWING状态。
4、如果服务为LEADING状态,则会创建并运行一个Leader对象;如果为FOLLOWING则会创建并运行一个Follower对象。package org.apache.zookeeper.server.quorum.Leader/Follower
需要注意的是:
选举过程中,有可能有些机器有一定的延时,导致其他机器都选出来了,他还没有收到消息,或者丢失消息,导致选择了错误的leader。
群首查询:
如果有服务器选择了错误的follower作为leader,被选的服务器不会相应任何leader请求,导致请求超时。(不清楚该服务器会不会再次被纳入集群,因为没有选举给他用了)
但是如果没有足够的follower,服务器会再次发起群首选举,因此错误的群首会导致整个集群启动时间更长。
三、状态更新的广播协议,Zab(Zookeeper Atomic Broadcast protocol):请求的处理
Follower将一个请求发送给leader,leader将暂时执行该请求,并将
结果
以event方式进行广播,将事务保存在其指定的“DataTree”节点上。
Zab过程:
1、群首向所有追随者发送一个proposal消息p。
2、当一个追随者接收到消息p后,确认提案来源是否是追随的群首,验证事务中消息的顺序。
3、然后响应群首一个ACK消息,通知群首其已接受该提案proposal。
4、
收到仲裁数量的服务器发送确认消息后(仲裁数包括群首自己),群首就会发送消息通知追随者进行提交commit操作
。
(
Zab保障:
1、保障事务顺序一致性。
2、事务更新一致性。
3、leader确保commit所有之前的epoch需要提交的事务,才开始执行新的event。
4、任何时候,都不会出现两个被仲裁支持的leader。
)
更新过程:
两种方式来更新追随者
DIFF,发送DIFF差异,滞后群首不多。事务日志
SNAP,发送SNAP快照,滞后群首太多。有效快照
java代码标识:
Zab代码范围:Leader、LearnerHandler(Leader执行)和Follower(Follower执行)。
Leader.lead()、Follower.followLeader(),在服务器QuorumPeer守护进程中从LOOKING到LEADING或FOLLOWING时被调用。
四、zookeeper事务过程(Server代码类)
Prep、Proposal、Sync 、Ack、Commit、ToBeApplied、Final
Follower、Commit、Sync、Ack、Final
单机事务处理过程:
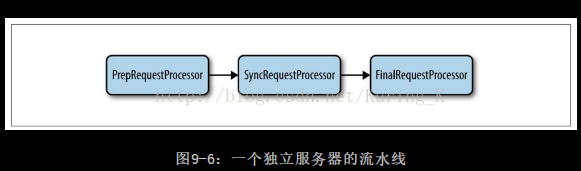
PrepRequestProcessor:接收客户端请求并执行
SyncRequestProcessor:将事务持久化到磁盘(事务日志)
FinalRequestProcessor:执行更新类型请求,或读取类型请求。
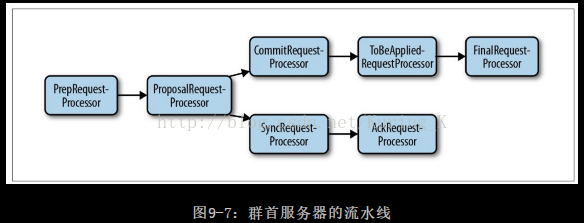
仲裁事务处理过程:
1、PrepRequestProcessor:接收客户端请求并执行
2、ProposalRequestProcessor:生成proposal提议,并转发所有请求给跟随者(CommitRequestProcessor 、SyncRequestProcessor(有写请求,先) )
3、SyncRequestProcessor:将事务持久化到磁盘(事务日志),并触发AckRequestProcessor。
4、AckRequestProcessor:生成确认消息,并返回给CommitRequestProcessor。
5、CommitRequestProcessor:收集到足够多的确认消息后进行提交。(Leader.processAck()添加消息到该类的一个队列中)
6、ToBeAppliedRequestProcessor:维护proposal列表,Leader使用该列表与Follower之间同步,在FinalRequestProcessor处理完后删除从列表中该提议,非读操作。
7、FinalRequestProcessor:执行更新类型请求,或读取类型请求。
追随者事务处理过程:

1、FollowerRequestProcessor:接收客户端请求并执行,处理完成后,转发给CommitRequestProcessor和Leader。
2、CommitRequestProcessor:转发读、写请求到FinalRequestProcessor,读请求直接执行,写请求需要等待Leader的commit消息。
3、SyncRequestProcessor:接收到Leader的proposal,将事务持久化到磁盘(事务日志),并触发SendAckRequestProcessor。
4、AckRequestProcessor:生成确认消息,并返回给Leader。
5、FinalRequestProcessor:当Leader的CommitRequestProcessor收到足够消息就会发送commit消息给Follower的FinalRequestProcessor,同时发送INFORM消息给观察者。
6、观察者的CommitRequestProcessor也会提交事务,但由于不会接收到proposal,也就不需要进行持久化到磁盘,也就不需要确认。
读写状态:
为了保证顺序一致性,在Leader、Follower的CommitRequestProcessor在收到一个写请求时会阻塞,直到将读请求转给FollowerRequestProcessor。
五、本地存储
日志和快照由SyncRequestProcessor处理,日志写入需要IO开销,所以批量写入是不错的选择,在该类的run()方法中,可以看出:使用while(true)在不停循环操作,满足一些条件后将会flush(),如队列超过1000事务。
toFlush
.add(si)
;
if
(
toFlush
.size() >
1000
) {
flush(
toFlush
)
;
}
在服务器把事务写入日志后确认对应的proposal,会调用ZKDatabase的commit()方法,该方法中会调用FileChannel.force()方法来保证已经将事务持久化到磁盘中。
注意:由于操作系统对于IO都是有“dirty page”缓存的,执行异步写入磁盘介质,所以要保证数据按照操作立即执行,需要调用IO流中的flush()操作(所有IO流都实现Flushable接口)
其次,现代磁盘也有磁盘写缓存,
六、快照
Zookeeper的快照类似于
热备
:在提取快照的过程中,继续处理请求。只备份每个节点的当前状态。
恢复快照到最新点:快照+日志。
七、会话
session是Client与Server之间的抽象,或者类似于连接。
仲裁模式,会话由Leader服务器来跟踪维护(SessionTracker接口,SessionTrackerImpl类);Follower只是把Client连接的会话信息转发给Leader(LearnerSessionTracker类)。
心跳:为了保证每个连接Server的Session存活,Server会发送一个请求或ping(LearnerHandler.run())到Client。心跳的发起由Leader Server触发(SessionTrackerImpl.touchSession())一个ping消息给她的Followers,由Follower收集存活的Session的列表返回给Leader,由她维护。(心跳包含client的session)
Leader每半个
tick
就会发起一次心跳,例如tick为2s,则每一秒就会发起一次心跳。
会话管理:使用ExpiryQueue类的数据结构,每个bucket对应某段时间内过期的会话,每隔expirationInterval的一个tick进行一次过期会话标记,下一次tick会清除被标记的会话。
bucket分配算法:

例如:
expirationInterval=2,超时时间为10s,则分配到bucke12中。
expirationInterval是一个tick,单位为秒。
八、监视点
Watcher是由读取操作所设置的一次性触发器。所有Server端都由WatchManager类的实例负责管理监视点列表和触发它们。监视点没有持久化,不会写入日志。Client与Server断连后,会从Server内存清除,重连后由Client(也有一份监视点列表)重新恢复。
Java过程:
1、DataTree类中持有一个WatchManager实例来监控子节点和数据。
2、处理设置监视点的读请求时,这个监视点会被加入到监视点列表。
3、处理事务时,会先查找监视点列表,并调用Manager的方法触发。
(注册监视点和触发监视点,都会以read请求和FinalRequestProcessor类的一个事务开始。)
4、发送给
ServerCnxn
类,该类的实例实现了Watcher接口,并承担起Server和Client之间的连接。其中的Watch.process()方法会发送被序列化的触发监视点到Client。
5、Client接收到监视点后反序列化,然后传递给应用。
九、客户端Client
以上都是Server的原理和结构,下面单独说一下客户端。
客户端的代码中有2个主要类:ZooKeeper、ClientCnxn.
ZooKeeper:Session的建立、操作等等。
ClientCnxn
:管理Client到Server的Socket连接,并维护一个Zookeeper服务器列表,用于重连其他Server。当重连其他Server后(如果该Session没有过期),客户端会重置Client的监视点到该服务器上(ClientCnxn.SendThread.primeConnection())。(也就一个client的监视点只会对应部署在一个Server节点上)
断连重置监视点默认开启 ,可以通过设置disableAutoWatchReset来禁用。
十、序列化
Zookeeper使用Hadoop中的
Jute
来做序列化。
所有数据,在同步或写入的时候都是以事务的序列化格式传输。















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









