






 在使用puppeteer-interceptor进行网络请求截获时,遇到中文响应体乱码的情况,原因在于拦截器未正确识别UTF-8编码,而是按ISO-8859-1处理。通过引入iconv-lite库,将从ISO-8859-1转码为UTF-8,成功解决了中文乱码问题。
在使用puppeteer-interceptor进行网络请求截获时,遇到中文响应体乱码的情况,原因在于拦截器未正确识别UTF-8编码,而是按ISO-8859-1处理。通过引入iconv-lite库,将从ISO-8859-1转码为UTF-8,成功解决了中文乱码问题。
问题
使用puppeteer-interceptor模块进行网络请求的数据截获时,response body中出现了中文编码乱码的问题。

html文件中文原文内容
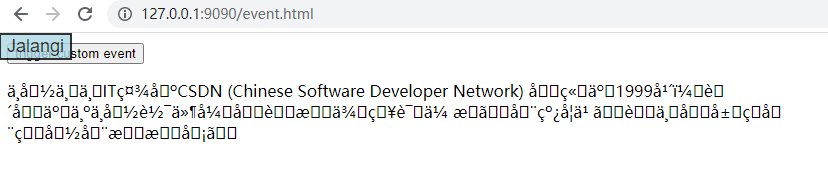
截获后返回的报文乱码内容
使用VSCode的HEX Editor插件对比源文件和乱码文件的不同。发现截获报文时对原有的中文数据部分进行了一些重编码。编码后原有的一个字节数据被拆分成了两个字节,出现了大量诸如十六进制C2 C3这样的字节,也即“å”这样的特殊字符。而原有的UTF-8中文编码则无法正常显示。对非中文内容则不存在问题。

查阅了一些资料后得到了解答。puppeteer-interceptor并没有正确识别响应包头中的charset=utf-8,而是使用了ISO-8859-1编码。
ISO-8859-1
别名是Latin1,Iso-8859-1编码是属于单字节的编码,即编码的范围是0到255.总共能表示256个字符,向下兼容了ACSII,也就是在ASCII编码的基础上扩展了127-255之间位置。编码范围是0x00-0xFF,涵盖了部分西欧的语言字符.由于和计算机的存储单元一样,应用比较广泛,例如在网络传输协议中和Mysql数据库默认的编码。
解决方法
在node.js中,安装iconv-lite库。
const iconv = require('iconv-lite');使用decode和encode函数进行编码转换,具体代码如下。
// 原始代码
const data = event.response.body;
// 改后代码
const data = iconv.decode(iconv.encode(event.response.body, "iso-8859-1"), "utf-8");最终得到的返回报文中,中文编码正常。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









