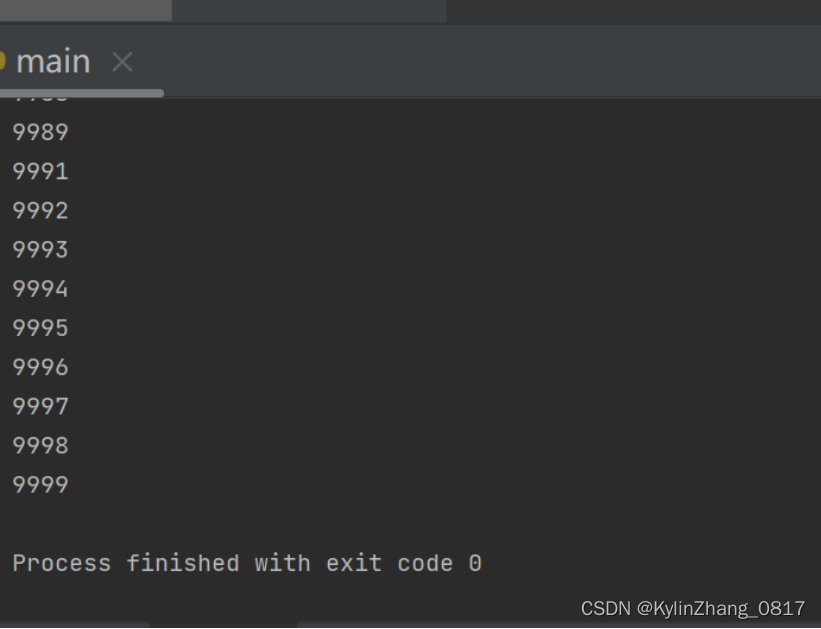
1.找出10000以内能被5或6整除,但不能被两者同时整除的数(函数)
def func():
for i in range(1, 10000):
if i % 5 == 0 or i % 6 == 0:
if i % 5 == 0 and i % 6 == 0:
continue
print(i)
func()
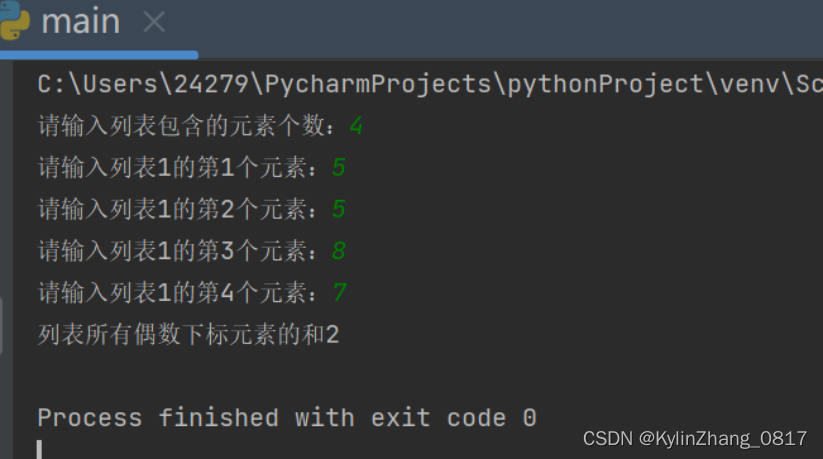
2.写一个方法,计算列表所有偶数下标元素的和(注意返回值)
def xiabioa_sum(ls=[]):
count = 0
for i in range(len(ls)):
xiabiao = i
if int(ls[xiabiao]) % 2 == 0:
count += xiabiao
return count
n = int(input('请输入列表包含的元素个数:'))
ls = []
for i in range(1, n + 1):
elem = input(f'请输入列表1的第{i}个元素:')
ls.append(elem)
print(f"列表所有偶数下标元素的和{xiabioa_sum(ls)}")
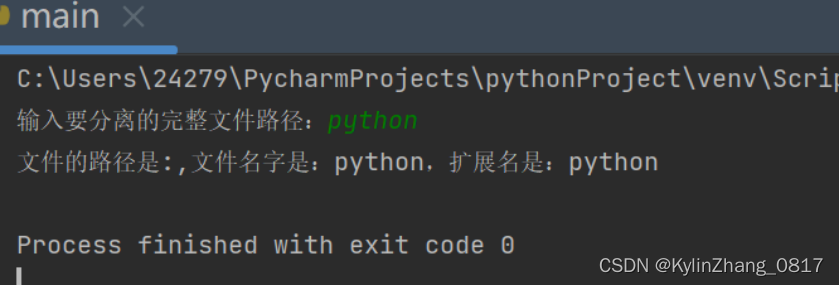
3.根据完整的路径从路径中分离文件路径、文件名及扩展名
path = input('输入要分离的完整文件路径:')
file_path = path[0:path.rfind("\\") + 1]
file_name = path[path.rfind("\\") + 1:]
file_extension = path[path.rfind(".") + 1:]
print(f"文件的路径是:{file_path},文件名字是:{file_name},扩展名是:{file_extension}")
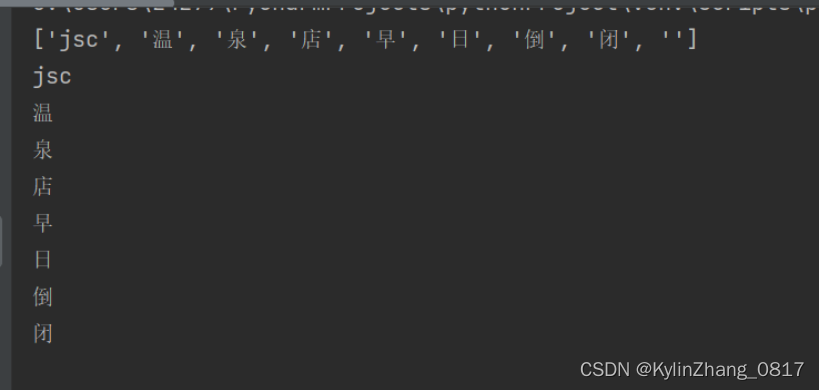
4.根据标点符号对字符串进行分行
s ='''jsc,温,泉,店,早,日,倒,闭,'''
a = s.split(",")
print(a)
for i in a:
print(i)
5.去掉字符串数组中每个字符串的空格
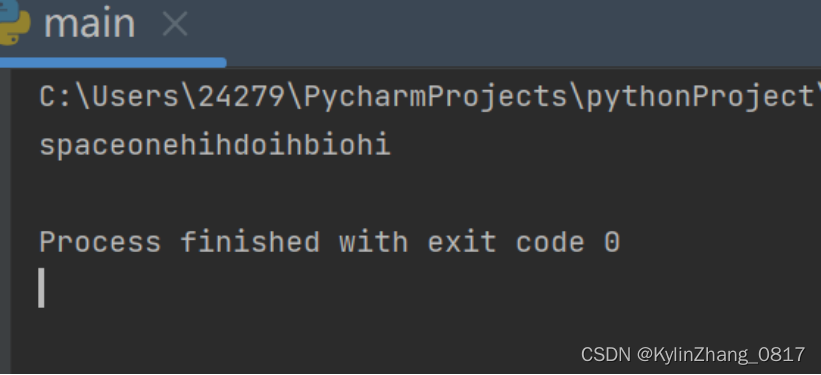
a = "sp ace o ne hih doih bi ohi"
a = a.replace(" ","")
print(a)
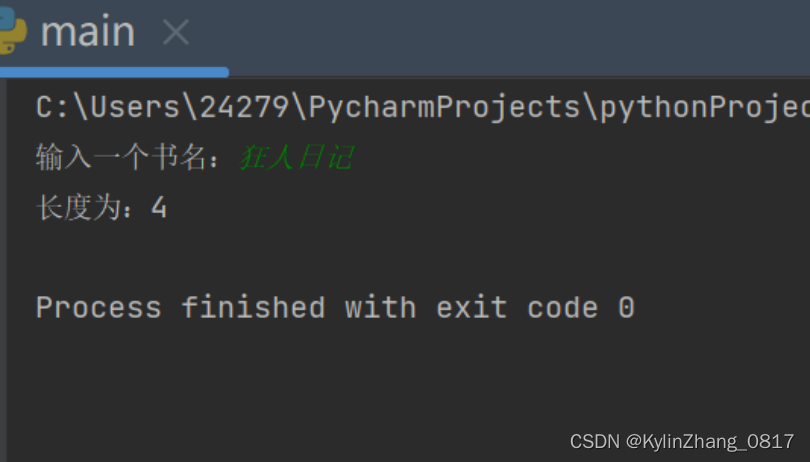
6.随意输入你心中想到的一个书名,然后输出它的字符串长度。 (len()属性:可以得字符串的长度)
book = input("输入一个书名:")
print("长度为:%s"%len(book))
7.两个学员输入各自最喜欢的游戏名称,判断是否一致,如
果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输
出你们俩喜欢不相同的游戏。
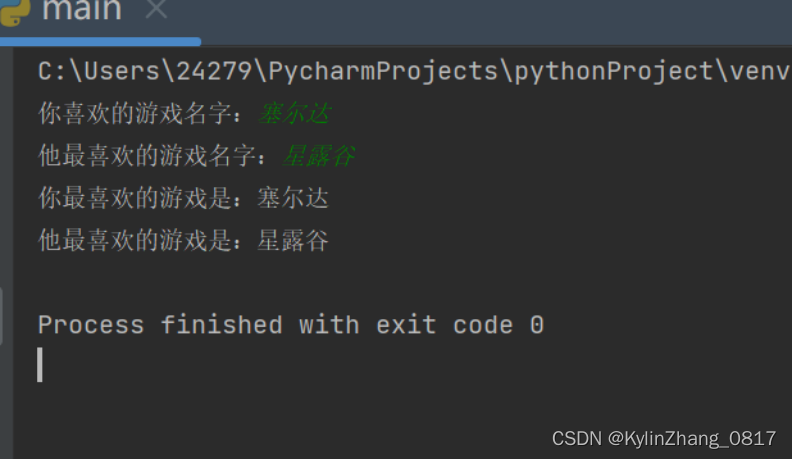
s1 = input("你喜欢的游戏名字:")
s2 = input("他最喜欢的游戏名字:")
if s1 == s2:
print("你们最喜欢的游戏是:{}".format(s1))
else:
print("你最喜欢的游戏是:{}".format(s1))
print("他最喜欢的游戏是:{}".format(s2))
8.上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
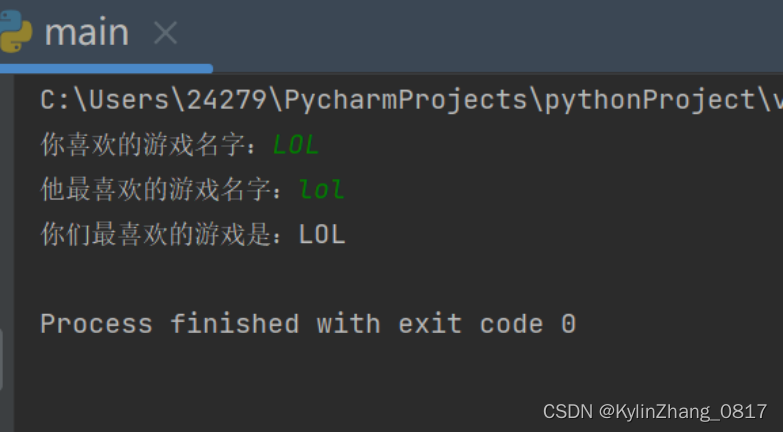
s1 = input("你喜欢的游戏名字:")
s2 = input("他最喜欢的游戏名字:")
s1 = s1.upper()
s2 = s2.upper()
if s1 == s2:
print("你们最喜欢的游戏是:{}".format(s1))
else:
print("你最喜欢的游戏是:{}".format(s1))
print("他最喜欢的游戏是:{}".format(s2))
9.让用户输入一个日期格式如“2008/08/08”, 输入的日
期格式转换为“2008年-8月-8日”。
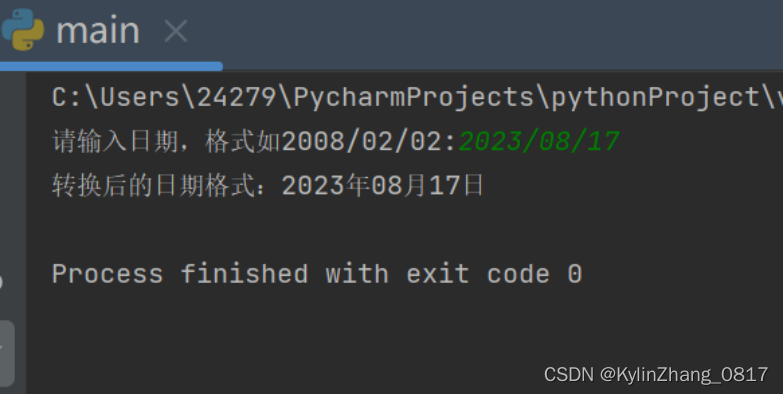
s = input("请输入日期,格式如2008/02/02:")
ls = s.split("/")
print("转换后的日期格式:{}年{}月{}日".format(ls[0],ls[1],ls[2]))
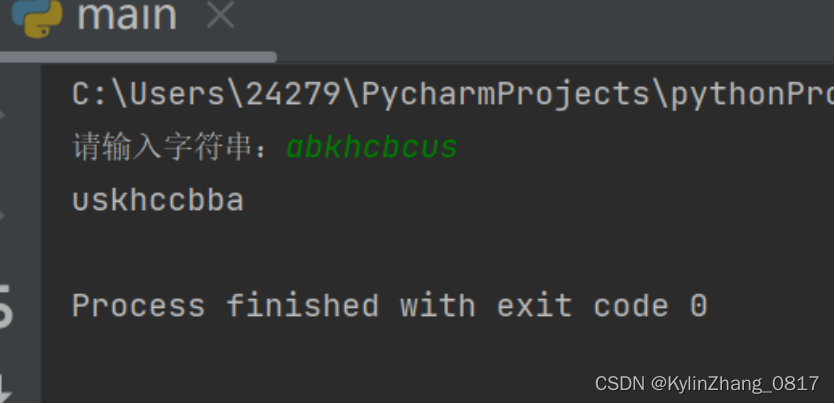
10.接收用户输入的字符串,将其中的字符进行排序(升
序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”。
s = input("请输入字符串:")
ls = list(s)
ls.sort()
ls.reverse()
s = ""
for i in range(0,len(ls)):
s += ls[i]
print(s)
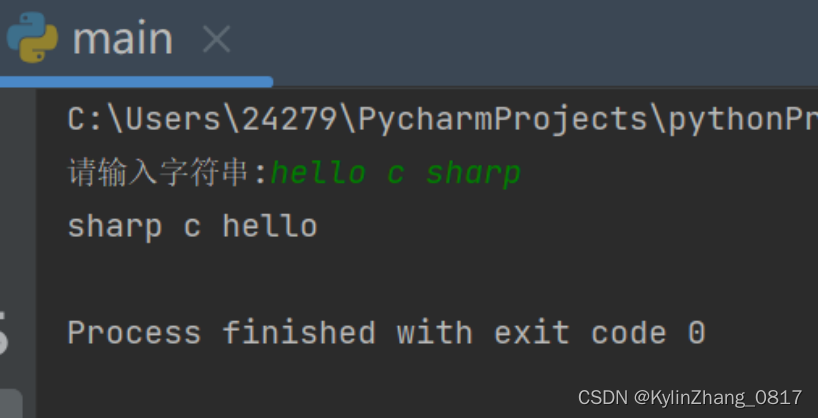
11.接收用户输入的一句英文,将其中的单词以反序输
出,“hello c sharp”→“sharp c hello”。
s = input("请输入字符串:")
ls = s.split(" ")
ls.reverse()
s = ""
for i in range(0,len(ls)):
s +=ls[i] + " "
print(s)
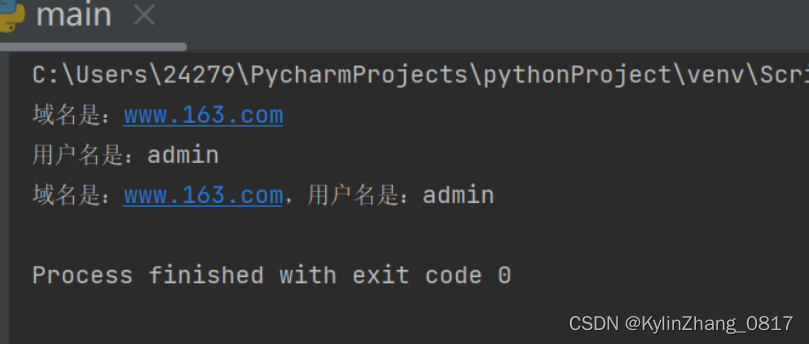
12.从请求地址中提取出用户名和域名
http://www.163.com?userName=admin&pwd=123456
s = "http://www.163.com?userName=admin&pwd=123456"
ls = s.split("/")
s1 = ls[2]
ls2 = s1.split("?")
print("域名是:{}".format(ls2[0]))
s1 = ls2[1]
ls3 = s1.split("&")
s1 = ls3[0]
ls4 = s1.split("=")
print("用户名是:{}".format(ls4[1]))
##用分割方法。
print("域名是:{},用户名是:{}".format(s[s.rfind("/")+1:s.find("?")],s[s.find("=")+1:s.find("&")]))
13.有个字符串数组,存储了10个书名,书名有长有短,现
在将他们统一处理,若书名长度大于10,则截取长度8的
子串并且最后添加“...”,加一个竖线后输出作者的名字。
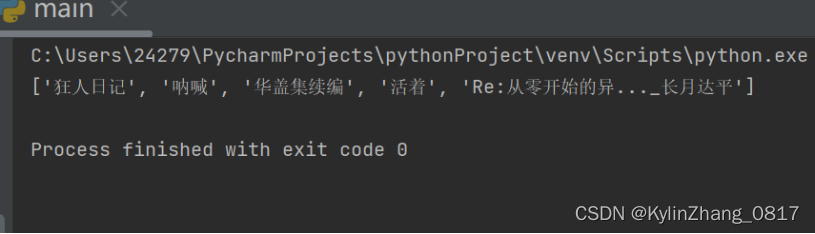
ls = ["狂人日记","呐喊","华盖集续编","活着","Re:从零开始的异世界生活"]
dir = {"狂人日记":"鲁迅","呐喊":"鲁迅","华盖集续编":"鲁迅","活着":"余华","Re:从零开始的异世界生活":"长月达平"}
for i in range(0,len(ls)):
s = ls[i]
if len(s) > 10:
s = s[0:9]+"..._"+str(dir[ls[i]])
ls[i] = s
print(ls)
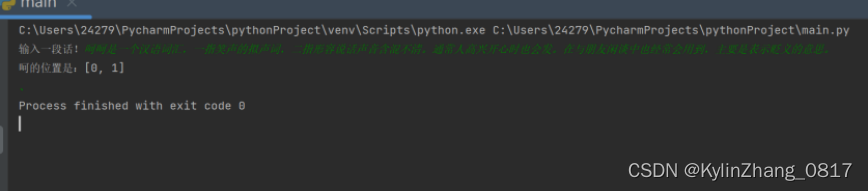
14.让用户输入一句话,找出所有"呵"的位置。
s = input("输入一段话!")
ls = []
for i in range(0,len(s)):
if s[i] == "呵":
ls.append(i)
print("呵的位置是:{}".format(ls))
15.让用户输入一句话,找出所有"呵呵"的位置。
s = input("输入一段话!")
ls = []
for i in range(0,len(s)-1):
if s[i] == "呵" and s[i+1] =="呵":
ls.append(i)
print("呵呵的位置是:{}".format(ls))

16.让用户输入一句话,判断这句话中有没有邪恶,如果有邪
恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变
成”老牛很**”;
s = input("输入字符串:")
print("邪恶消失后:{}".format(s.replace("邪恶","**")))

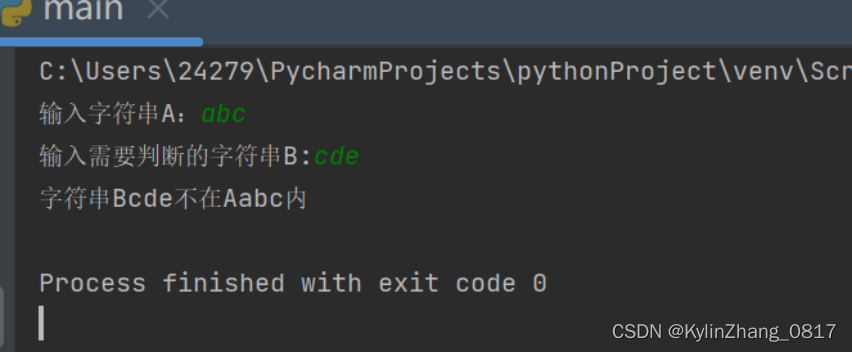
17.如何判断一个字符串是否为另一个字符串的子串
find()
index()
双层循环完成
s = input("输入字符串A:")
s1 = input("输入需要判断的字符串B:")
flag = True
if s.find(s1) != -1:
flag = False
if flag:
print("字符串B{}不在A{}内".format(s1,s))
else:
print("字符串B{}在A{}内".format(s1,s))
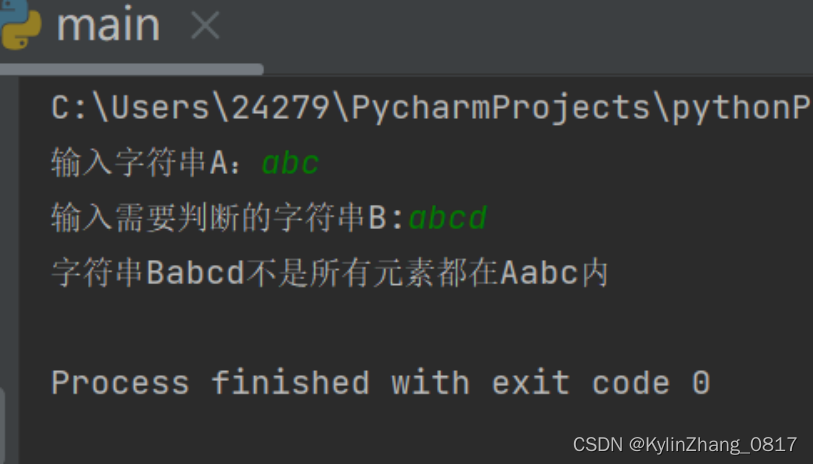
18.如何验证一个字符串中的每一个字符均在另一个字符串
中出现过双层循环
s = input("输入字符串A:")
s1 = input("输入需要判断的字符串B:")
flag = True
for i in range(0,len(s1)):
if s.find(s1[i]) == -1:
flag = False
if flag:
print("字符串B{}的所有元素在A{}内".format(s1,s))
else:
print("字符串B{}不是所有元素都在A{}内".format(s1,s))
19.如何随机生成无数字的全字母的字符串
import string
import random
s = string.ascii_letters
s1 = ""
for i in range(1,20):
s1 += random.choice(s)
print(s1)
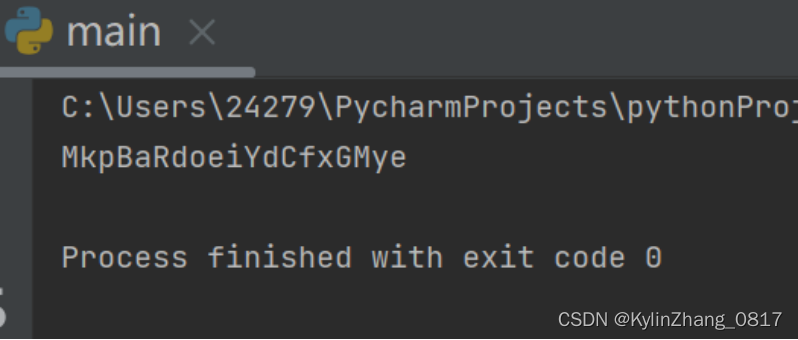
20.如何随机生成带数字和字母的字符串
import string
import random
s = string.ascii_letters + string.digits
s1 = ""
for i in range(1,20):
s1 += random.choice(s)
print(s1)

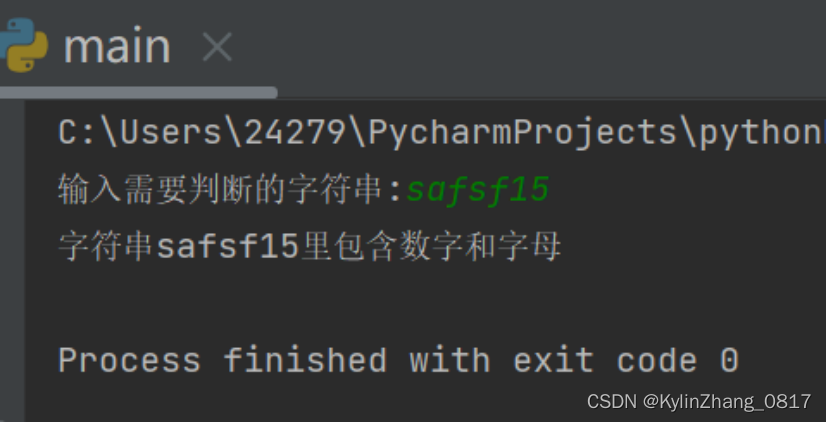
21.如何判定一个字符串中既有数字又有字母
s = input("输入需要判断的字符串:")
if (s.isalnum()and not s.isalpha()) and not s.isdigit():
print("字符串{}里包含数字和字母".format(s))
else:
print("字符串{}里并不是既包含字母又包含数字".format(s))
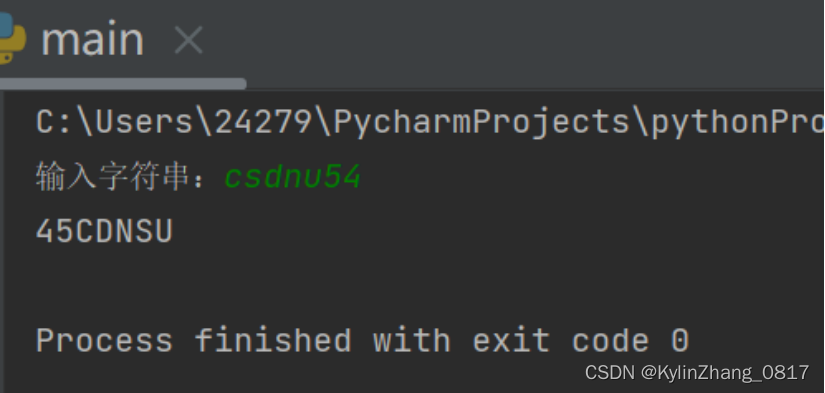
22.字符串内的字符排序(只按字母序不论大小写)
s = input("输入字符串:")
s1 = s.upper()
ls = list(s1)
ls.sort()
s2 = ""
for i in range(0,len(ls)):
s2 += ls[i]
print(s2)






















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









